















第1回 人工知能(AI) 入門の入門
概要
AI (人工知能, artificial intelligence) は最近テレビでもしょっちゅう耳にする言葉になりました。一般的になってきたのはこの数年ですが、実は40年近く前から人工知能は研究されたり使われたりしてきているのです。ただ、現在目にするような音声認識だとか画像認識とは少し違ったものでした。このコラムでは、何回かに分けて人工知能の過去、現在、未来について書いていきたいと思います。
1. 人工知能のはじめ:エキスパートシステム
人工知能という言葉がコンピューターの世界で言われだしたのは1960年台、もう50年以上も前のことです。このあたりの事情をざっと説明しましょう。
コンピューターが電卓と異なるのは、計算手順をプログラムとして蓄えておいて、その手順通りに計算ができることでした。電卓では機械がやってくれるのは計算の部分だけで、順序は人間が考えてキー入力しなければなりませんでしたので、これは大きな違いです。特に重要なのは、計算手順の中でいろいろな条件を判断して、その条件に合致した場合とそうでない場合で別な計算手順を実行できることでした。条件によって計算手順は変えられますが、この手順も事前に決めて入力しておく必要があります。これを条件分岐といいます。(注: 厳密には、条件によって次の実行手順を作り出すことも可能ですが、どのように作り出すかはあらかじめ決めておかなければなりません)。
こうなると、コンピューターは単に数字の計算をする機械ではなく、いろいろな条件を組み合わせて複雑な判断をさせることが可能になります。そこで、専門家がさまざまなデータを眺めて行う専門的な判断をコンピューターに置き換えられないかという試みが行われるようになりました。専門家(エキスパート)の判断を代わりに行うので、このようなシステムをエキスパートシステムといいます。
スタンフォード大学で作られた有機化学の化合物分析の Dendral (1965年), ハーバード大学での医療診断を行う MYCIN (1970年) が代表的なものでした。これらのシステムは、いろいろなデータを組み合わせて専門家が行う判断を上記の条件分岐を複雑に組み合わせてできています。その意味では普通のコンピュータープログラムです。条件分岐は判断の規則(ルール)の組み合わせなので、これをルールベースシステムと呼ぶこともあります。
図1はエキスパートシステムがどのように判断をしていくのかをごく簡単に書いています。Webサーバーの故障の原因を探るために調査をして範囲を絞り込んでいく様子がわかると思います。
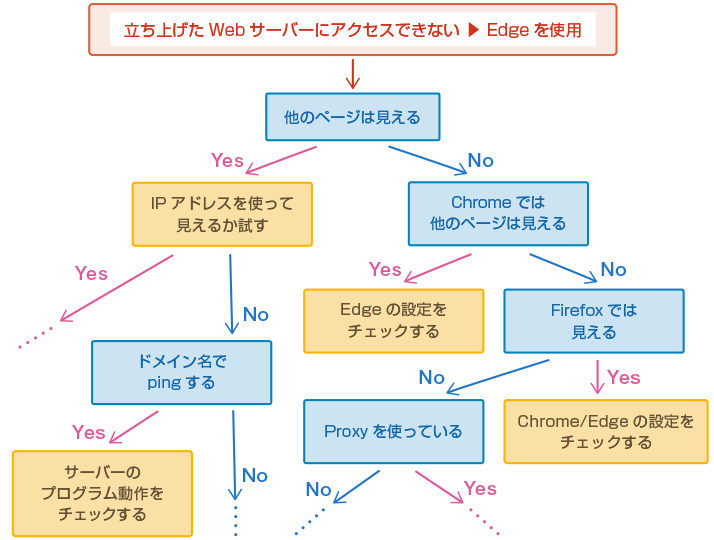
図1 エキスパートシステム内の判断ロジックの例
このように、エキスパートシステムでは診断や判断といったこれまで人間の独壇場だった領域がコンピューターで置き換えられるようになりました。このようなエキスパートシステムの成功事例がいくつか知られるようになるにつれ、この考え方を発展させていけば人間にしかできない判断、例えば音声や画像の内容を理解したり、文章の内容を理解したりすることができるのではないかと考えられるようになり、人工知能 (AI, artificial intelligence)という言葉が使われるようになりました。
しかし、この試みはごく狭い範囲の問題にしか適用できないことが次第に明らかになってきます。音声、画像のデータは膨大でした。当時は CD-ROM もなく、デジタル録音機もデジカメもない時代で、現在のデジカメで撮影した写真1枚分ですらコンピューターに蓄積して処理するなど思いもよらない事でした。しかも、複雑な問題を解くためのルールを作っても、ルールが複雑すぎてプログラムを書くこと自身が大変困難で、仮にルールが書けたとしてもこれをコンピューターが実用的な性能で解くことも困難であるばかりでなく、専門家が行っている思考過程が簡単に書き出せるものばかりではないことがわかってきたのです。
2. 学習の登場: 機械学習
最初の人工知能は、乱暴に言えば人間の脳が行っている情報処理をすべてコンピュータープログラムで書いてしまおうというものでした。このようなやり方がなかなかうまくいかない中で台頭してきたやり方が機械学習です。実際のデータを使ってプログラムのパラメーターを決め、これを使って新しいデータの予測をしようというものです。データがなければこのようなことはできません。この背景には使えるデータの量が爆発的に増え、データの処理性能もうなぎのぼりに高くなってきた事情が反映されています。インターネットの普及とマイクロプロセッサの性能向上です。インターネットは最初米国の軍と教育機関で使われていたものが1980年代後半から1990年代 (日本では1993年です)にかけて一般利用ができるようになったもので、この上の Web ブラウザは1992 年に発表されています。これが契機になって音声や画像、動画像のデジタル化が促進され、誰でも簡単にデジタルデータを作ったり送ったりすることができるようになってきたのです。マイクロプロセッサは1990年代当初に32ビットのものが出現して以来、ムーアの法則に言われるように2年で2倍の容量と性能の向上が図られてきました。現在のスマートフォンの計算能力やデータ蓄積能力は1960年代のメインフレームコンピューターと比較にならないほど高くなっているのです。
こうして多くのデータが低コストで集められ、計算できるようになると、すべてをプログラムで書いてしまうのではなく、ある程度プログラムの枠組みを作り、その結果が集めたデータと一致するようにプログラムを変えればいいのではないかという発想が出てきます。これが学習という考え方です。
図2にごく簡単な例を示してあります。ある銀行がお客さまの年収と資産額を調査したところ、この図のような結果が得られたとします。どうやら見てみると例外はあるものの年収の多い人ほど資産額が大きい傾向にあり、どうも両者は比例関係にあるように見えます。そこで、データに基づいて年収額と資産額の関係を直線で引いておけば、年収額から資産額が推定できることになります。データを増やしていけばこの関係のもっともらしさは増えていくことでしょう。
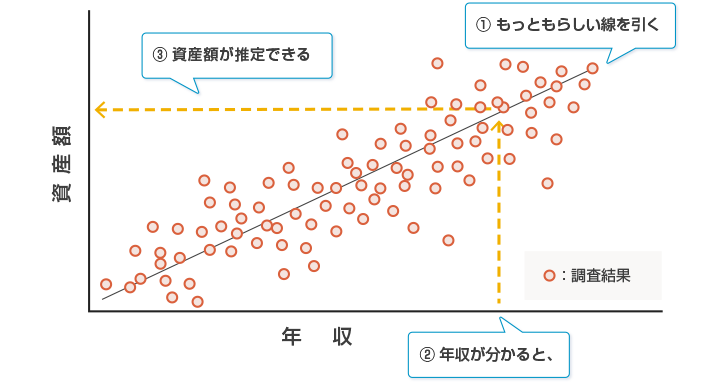
図2 調査データを使って資産額を推定する
機械学習では、学習の基本になるプログラムやその枠組が何種類もあり、アプリケーションに応じて使う枠組みを決めていきます。この枠組のほとんどは確率統計論を基本にしています。
機械学習は、現在では非常に多くのアプリケーションで使われています。例えば、マーケティング。Web でデータをブラウズしたあとに似た宣伝が表示されたりしますが、これも機械学習が組み込まれています。クレジットカードやローンの審査などもその仲間です。文章を読んで意味を解析したり、類似の文章を調べたりするのにも機械学習は使われています。
機械学習では、いろいろなデータからどうやって結論を判断したのかをある程度説明することができます。図2であれば、「調査によって年収額と資産額には一定の相関があるので、この統計情報を利用して資産額を推定したと説明が可能です。また、次に述べる深層学習ほど多くの計算は必要ありません。
3. ニューラルネットと深層学習
最近の一番の話題は深層学習です。機械学習では、人間におなじみの音声や画像を見てこれが何なのかを判断したり、自動的に絵を書いたりすることはできません。それを可能にして、ますます適用領域を広げているのが深層学習です。
これは、ニューラルネットを基本にしています。ニューラルネットとは、図3に示すように人間の脳細胞と神経細胞の間の信号のやり取りをコンピューターの上で擬似したものです。この図では、神経細胞は樹状突起が信号を集め、これを細胞体で処理してその情報を次の神経細胞に届け、これが連鎖していく構造になっています。この神経細胞一つをコンピューター上で模擬したのがパーセプトロンといいます。図4にその概要を示します。大変簡単なもので、これで入力データから出力データを生み出すのはそれほど難しくはありません。
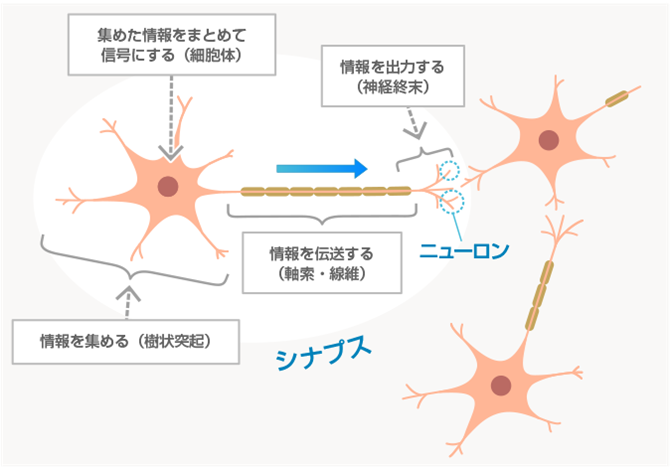
図3 神経細胞における情報の収集・伝達・処理のモデル
生命科学教育シェアリンググループ「神経細胞の構造」をもとに当社にて独自に作成
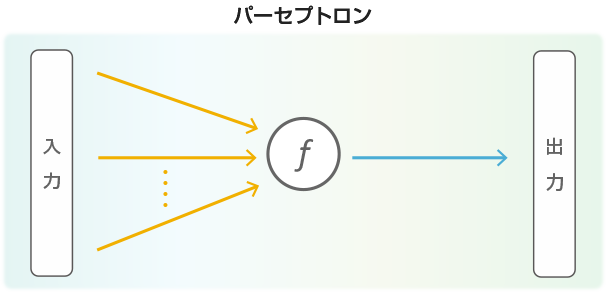
図4 神経細胞を模したパーセプトロン ー 深層学習の基礎
実際には、生物の脳と同じようにこれをたくさん組み合わせて図5のようなネットワークにします。神経 (ニューロン) のネットワークということで、これをニューラルネットといいます。このようなモデルが提案されたのも 1960年代でしたが、当時のコンピューターではこのような複雑なネットワークで実用的なプログラムを作ることはできませんでした。
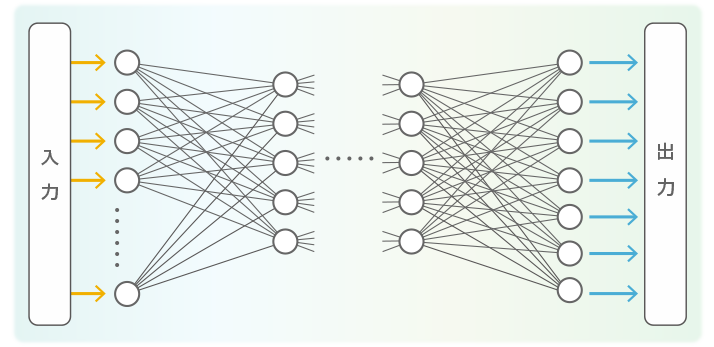
図5 パーセプトロンを組み合わせてニューラルネットにする
ところが、21世紀になってコンピューターの性能が飛躍的に高まり、ネットワークの発展と相まってデジタルデータの収集も簡単になってくると事情が変わります。これまでプログラムを1行ずつ書いて作ってきた画像認識にニューラルネットが使われるようになってきたのです。図6にその模様を示します。2012年にニューラルネットを使った画像認識によって認識誤差は一気に10%以上改善され、人間の能力も追い越していく模様がわかると思います。
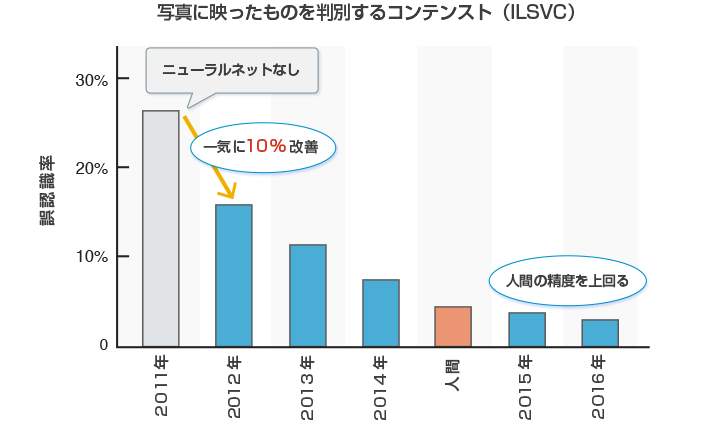
図6 ニューラルネットを使って画像認識が飛躍的に発展
福島俊一(2017, JST)「ビッグデータ×人工知能技術の挑戦」をもとに当社にて独自に作成
機械学習と同様にニューラルネットも「学習」というプロセスを経て実際のデータを処理できるようになります。これら、「学習」とはどういうことをするのか、次回以降順次解説していきます。
Writer Profile
鈴木 幸市
Tweet
本コラムの内容に基づき、以下のサイトにて説明動画を公開しています。ぜひご覧ください。
また、ご説明にお伺いすることも可能ですので、お問い合わせください。
※ 第1回は動画内3番目の講演「人工知能技術とは?」をご覧ください。