















第3回 人工知能(AI) ディープラーニング(深層学習)の仕組み
前回は人工知能の一番のトピックである“ニューラルネットとディープラーニング(深層学習)”についてお話しました。深い層をもつニューラルネットに、多くのデータを与えて学習させることで、さまざまな予測や判断をしてくれるようになります。この学習というのは、第2回の中で「ニューラルネットの中のニューロンをつなぐシナプスの重みづけを調整していくこと」と、解説しました。今回は、この重みづけの調整のしくみについて解説したいと思います。
その前に、実際にニューラルネットワークを学習させることと、その学習した結果を活用することについて、少し整理しておきましょう。
5. ニューラルネットワークの「学習」の活用 -学習と推論-
赤ちゃんが成長して、やがて学校に入りさまざまな勉強をしたのちに大人になって仕事に就くのと同じように、人工知能は「学習」してから仕事をします。(正確に言うと「学習」しながら仕事もします)ですので、人工知能を活用するには2つのフェーズが必要になります。
1つ目が「学習(training)フェーズ」、2つ目が「推論(inference)フェーズ」です。
まず、大量のデータをニューラルネットワークに読み込ませ、シナプスの「重みづけ」を最適に調整したネットワークを“学習済みモデル”として作り上げることが「学習(training)」フェーズです。続いてこの“学習済みモデル”に新しい事象を入力することで、得られる出力が人工知能の「知能」を活用した出力となるのです。これが2つ目の「推論(inference)」フェーズになります。難しいですね。
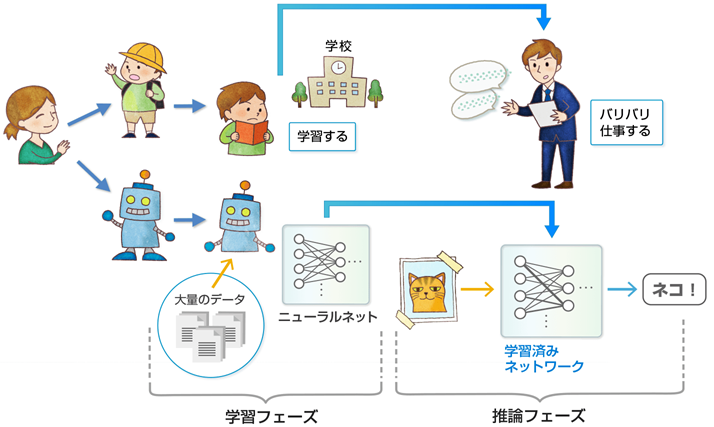
前回の画像コンテストの話 でもう一度考えてみましょう。「学習(training)」フェーズでは「ヨット」「花」「動物」「猫」のさまざまな写真をニューラルネットワークに大量に見せて“学習済みネットワーク”、つまり“シナプスの重みづけの塊”を作り上げます(作り方は次章で説明します)。そして「推論(inference)」フェーズでは、「学習(training)」フェーズで作り上げた“学習済みネットワーク”に、まだ見せたことのない画像を見せると、その画像が「ヨット」「花」「動物」「猫」のどれか言い当ててくれる、つまり人工知能が推論してくれるのです。
人工知能が「こういうことじゃないかなぁ?」と答えを出すのです。「推論」と言う言葉を使いましたが、人間が、過去の経験に基づき頭で考えて、見たこと聞いたこと、あるいは触れたこと、それらを複合して行動すること、は「推論(あるいは「予測」)」から始まります。文字を読むとき「ここに書かれた文字は「あ」と言う文字かなぁ」とか、目で色々と見るとき「この写真に写っているのは「ヨット」かなぁ」とか、言葉を聞くとき「お母さんが言っているのは「おはよう」かなぁ」とか、体を動かすとき「こうすればバットにボールが当たるかなぁ」とか、推論(あるいは予測)していきますね。かのホーキンス先生も推論(あるいは予測)することが、知能の土台になっていると言っています。※
※ 参考文献:Jeff Hawkins, Sandra Blakeslee著 "On Intelligence: How a New Understanding of the Brain Will Lead to the Creation of Truly Intelligent Machines" St. Martin's Griffin発行,2005年(邦訳題:「考える脳 考えるコンピュータ」、ランダムハウス講談社発行、伊藤文英訳)
このようにして、「学習(training)」と「推論」のフェーズを使って人工知能をさまざまな場面で使うことが可能となるわけです。では、ようやく、どのようにして「学習(training)」をするのか?そのしくみについて説明をはじめましょう。
6. 「学習(training)」のしくみ
シナプスの重みづけをどうやって調整しましょうか?
簡単に言うと、「答え合わせを何度も繰り返して調整する」となります。
例えば、画像を入力し、何が写っているか?という出力が得られるようなニューラルネットワークを組むことにします。このネットワークは、組み始めは、生まれたての赤ちゃんと同じなので、何も「学習」していません。そこで、シナプスの重みづけをすべて均等に、例えばすべて「1倍」にしておきます。そして「猫」の画像を見せてあげる。「猫」が出力されれば、重みづけは調整しません。でも、さまざまな「猫」の画像を見せるうちに「動物」とか「ヨット」とかを出力してしまう場合も出てきます。その場合には、重みづけを調整して、なんとか「猫」と出力できるように調整します。もちろん、それまでに見せた「猫」の画像も、できるだけ「猫」と言う答えが出るように調整を進めます。さまざまな「猫」の画像に対して、できるだけ「猫」という答えが出るように調整するのです。
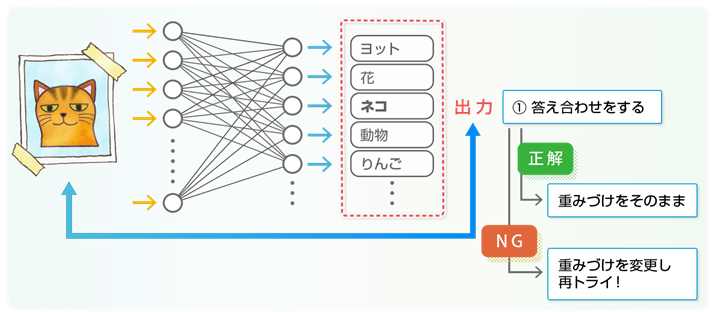
この調整が実に難しい。「これは「猫」だよ、これも「猫」だよ、これもね」と言いながら「猫」と答えを出すための調整です。どう調整を進めたら良いのでしょうか?ここからは計算方法の説明になります。
専門用語では「誤差逆伝搬(バックプロパゲーション)」で調整を進めます。「誤差」というのは、入力の「猫」と出力の差ですね。例えば出力が「猫」なら誤差は無し、それ以外は誤差が有りとなります。この誤差を最小にするシナプスの重みづけを出力から入力に向かって計算してゆく手法です。正確には数式を追いかける必要がありますが、ここではこんな感じで調整を進めるという理解にとどめたいと思います。
誤差を小さくするには、誤差の量を見ながら重みづけを変化させ試行錯誤します。例えばシナプスが1本の場合を考えます。その重みづけを、増やせば誤差が小さくなるのか、減らせば誤差が小さくなるのか?グラフで書くとこんな感じですね(図参照)。
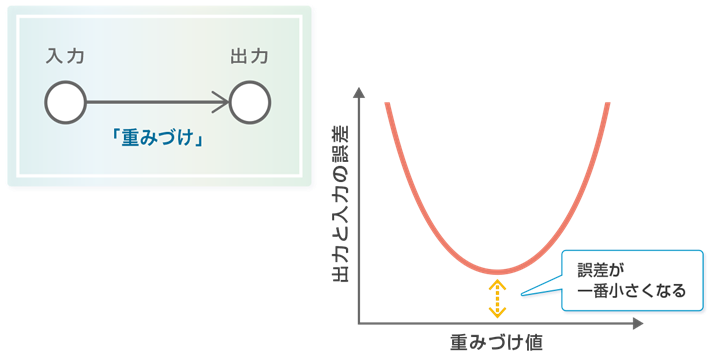
誤差は量なので、一番小さくなる時の重みづけの値が出てきます。ここにすれば誤差が一番小さくなるのです。簡単ですね。では、シナプスが2本の場合はどうでしょう?図を描いてみると、こんな感じになります(図参照)。
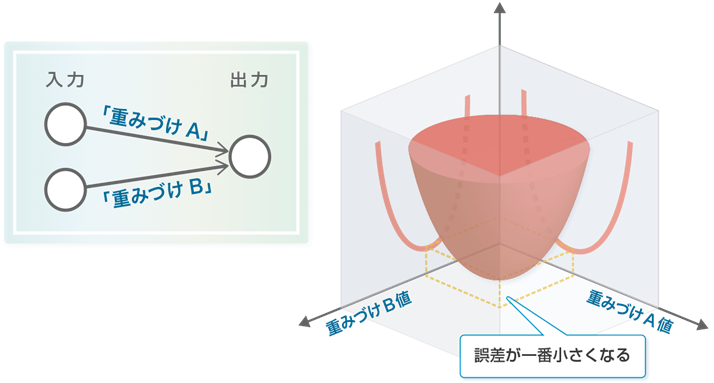
2本のシナプスの重みづけを底面に持つすり鉢のような形で、すり鉢の一番“くぼみ”部分である中央底が、誤差が一番小さくなる重みづけの組合せとなります。
なるほど、では3本、4本、と増えた場合は?これは図では書き表しにくくなりますが、同じような考え方をすると、何か誤差が最小になるような重みづけの組合せが出てくることが想像できます。このようにして出力につながるニューロン1つに入り込むシナプスの調整ができました。次は、その一つ前の層のニューロンについて、同じように重みづけを調整します。これを繰り返し、ちょうど出力から入力に向けて誤差を層ごとに小さくしながら伝搬していくように調整を続けるのです。もちろん、ニューロンやシナプスの数には限りがあるので完全に誤差が無くなる(ゼロになる)ような重みづけの組合せに辿り着くことは稀で、誤差ができるだけ小さくなるような組み合わせを計算していくのです。
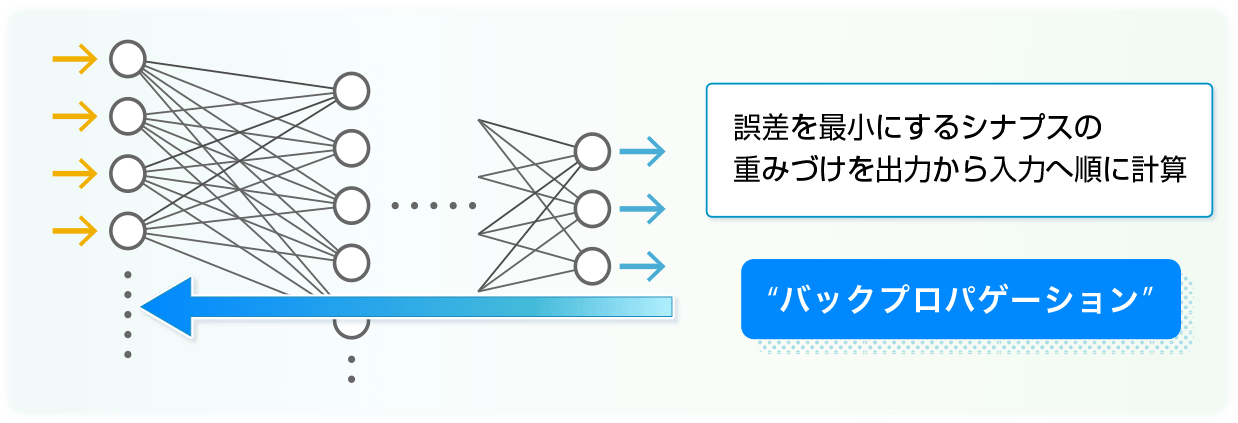
このようにして、すべてのシナプスの重みづけの組合せを丹念に計算して見つけて行くのです。また、例えば入力に「猫」の画像を用いていたとすると、さまざまな「猫」の画像を見せては、ニューラルネットワーク内の重みづけを調整し続けることで、「猫」を学習していきます。これで完璧!
※ この誤差逆伝搬の計算では、例えば上でお話したシナプスが2本の場合の説明で出てきた“すり鉢”は1例であり、色々な“くぼみ”を持つお皿のような形をしていることもあり、この“くぼみ”を探す計算過程で誤差が一番小さくならない重みづけの組合せに落ち着くというような課題も出てきます。
しかしながら、すでにもうお気づきの方も沢山いらっしゃると思いますが、ニューロンやシナプスが、それこそ人間の脳のように千数百億個もあり、また沢山のデータを読み込ませて、重みづけを調整しようとすると、気の遠くなるような計算量が必要になりますね。そうなのです。もし人間の脳レベルのニューラルネットワークの計算をさせようと思うと、みなさんご存知の現在のスーパーコンピューターを使っても果てしない時間がかかってしまい、いつまでたっても答えが出ません。
でも、例えば画像に写っているのが「お母さん」と言い当てたり、「おはよう」と言っているとか聞き分けたりするのに必要なニューロンの数は数十個~数百個であれば十分で、これであれば何とか実用的な時間内に重みづけの組合せを計算できるようになってきました。
なんか、素晴らしい技術だなということが分かってきましたか?ですので、現在の人工知能ブームが巻き起こっているのです。なんかできるかもしれないぞ!と。
ですが、課題や問題も山積みです。次回はディープラーニングの「ブラックボックス問題」などについてご紹介していきます。
Writer Profile
営業推進部
AIビジネスコーディネーション担当
川村 直毅
Tweet
本コラムの内容に基づき、以下のサイトにて説明動画を公開しています。ぜひご覧ください。
また、ご説明にお伺いすることも可能ですので、お問い合わせください。
※ 第1回は動画内3番目の講演「人工知能技術とは?」をご覧ください。