















Apache Sparkで始めるお手軽機械学習(Word2Vec編)
Tweet

ソリューション事業部
ビッグデータ基盤ビジネスユニット
チーフエンジニア
小山 哲平

ソリューション事業部
ビッグデータ基盤ビジネスユニット
主任エンジニア
川﨑 寛文
Apache Sparkと機械学習
当社のコラムでも既に何度か取り上げてきたが、Apache Sparkがいよいよ本格的な流行の様子を見せている。Apache Sparkは下図のようなエコシステムを持っているが、特にその中でも、Spark Streamingによるリアルタイム処理とともに、MLlibによる機械学習処理が人気を博している。日本ではHiveを用いてのバッチ処理高速化にてHadoopが広く使われるようになったが、Apache Sparkの場合は、リアルタイム処理・機械学習処理を糸口にパラダイムシフトが行われていると言っても過言ではないだろう。
(出典:Apache Spark公式サイト )
本コラムではMLlibを用いての機械学習処理について簡単な使い方を説明するものとする。
Apache Sparkは分散メモリRDDを活用することで、特定のデータに対する繰り返し処理に向くアーキテクチャーであり、MLlibはその特徴を活用して機械学習を実装することで、高速な学習処理を実現している。MLlibは現在もビルドインの機械学習アルゴリズムを増加させており、実用的な機械学習用途でも十分に活躍できる存在となってきている。本コラムでは、そのビルドイン機械学習アルゴリズムの中から、自然言語処理系アルゴリズムであるWord2Vecを取り上げ、MLlibを用いた機械学習の使い方を例示しよう。
Word2Vecとは?
MLlibでは多くの機械学習関連のアルゴリズムが実装されている。それは、決定木やベイズ分類器といったモデリングアルゴリズムのみならず、TF-iDFなどの特徴抽出アルゴリズムまで、広い範囲をカバーしており、提供対象は日々増加している。
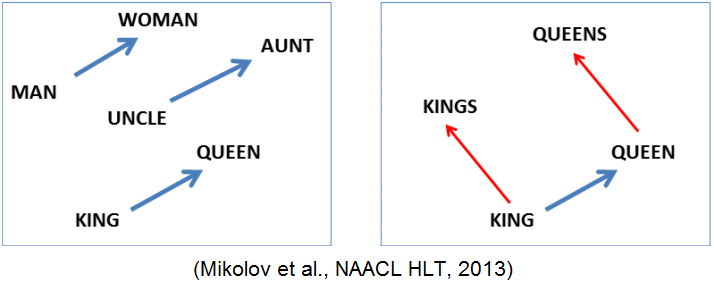
本コラムでは、その中でも昨年・一昨年に流行を見せたWord2Vecを取り上げることにしよう。Word2Vecとは、2013年にGoogle研究所が複数の論文を発表して以来、世界中の自然言語研究者・開発者の間で流行したアルゴリズムである。「同じ文脈で利用される単語は、同じ意味を持つ」という仮説に基づき、「単語」の特徴をベクトルで表現する技術となっている。この仮説に基づくため、単語の特徴や意味構造を含めてベクトル化することができ、意味的に近い単語は、空間上で近くに存在するベクトルとして表現されることから、類義語の抽出に用いられている。また、ベクトルで表現されるため、単語同士の引き算や足し算が可能なことが興味深い技術である。(例:“king”-“man”+“woman”=“queen”)
本コラムのサンプルプログラムの概要説明
本コラムでは、Wikipediaの文章をコーパス(学習用文章)として利用し、Word2Vecにて各単語の特徴を学習させ、学習したモデルを用いて任意の単語の類似語を推定するサンプルを紹介する。以下に、本コラムで紹介するサンプルプログラムの実行の流れを図示する。
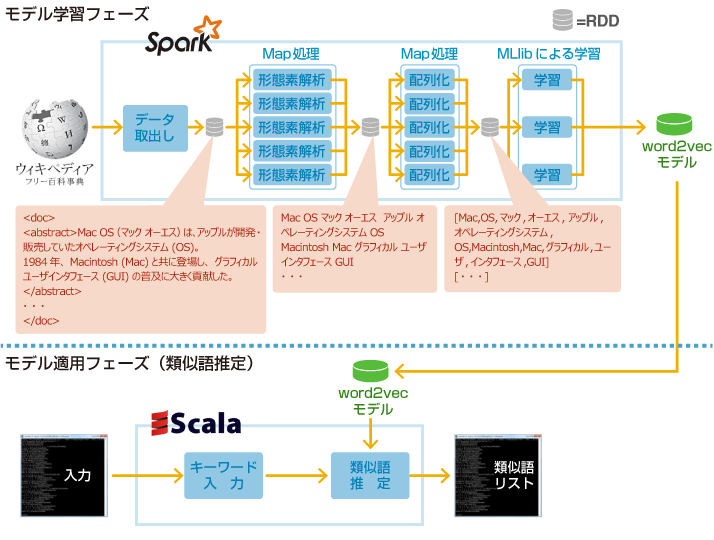
一般的に機械学習は、モデルを学習するフェーズと、そのモデルを適用するフェーズに分けて考えることができる。
まず、学習フェーズの流れは以下のようになる。
- あらかじめWikipediaの記事データ(本コラムでは概要のみを使用)をダウンロードしておく。
- Apache Sparkのジョブを起動し、Wikipediaのデータファイルを読み込む。
- 不要文字列の削除、および、形態素解析を実行する。なお、形態素解析にはKuromojiライブラリを利用する。
- 形態素解析の結果を配列へ変換する。
- MLlibのWord2Vec実装へ配列を渡し、モデルを学習させる。
2~5がApache Spark上で実行する部分であり、並列処理が可能になることで学習フェーズの処理時間を大幅に短縮することが可能となる。
次に、作成されたモデルを用いて類似語推定を行う、モデル適用フェーズについて説明する。今回は、単純に、作成されたモデルデータに対して1件のキーワードを与え、その類似語推定を行うものとする。従って分散処理を行う必要がないため、Spark-Shell上のScalaで実行結果を表示させるのみのプログラムとしている。
環境構築
Apache SparkはWindows環境でも動作するものの、Windows環境のSparkは日本語文字列の扱いが得意ではないため、LinuxにてApache Spark、および、サンプルプログラムを実行できる環境を用意する。今回のサンプルプログラムは、以下の環境を前提に作成している。
OS : CentOS 6.6 64bit Minimal
CPU : Core i5 1.7GHz 以上
メモリ : 4GB以上
HDD : 空き領域30GB以上
Apache Sparkのインストール、および、サンプルプログラムの実行に必要なプログラムのインストールの手順を以下に記述する。
# 環境構築に必要なプログラムのインストール sudo yum install -y vim wget unzip java-1.7.0-openjdk-devel # Apache Sparkのインストール cd wget http://d3kbcqa49mib13.cloudfront.net/spark-1.3.1-bin-hadoop1.tgz tar zxvf spark-1.3.1-bin-hadoop1.tgz sudo mv spark-1.3.1-bin-hadoop1 /opt/. cd /opt sudo ln -s spark-1.3.1-bin-hadoop1 spark # Kuromoji形態素解析器のインストール cd wget https://github.com/downloads/atilika/kuromoji/kuromoji-0.7.7.zip unzip kuromoji-0.7.7.zip cd kuromoji-0.7.7/lib sudo mv kuromoji-0.7.7.jar /opt/spark/lib/. # 一時ファイルの削除 cd rm spark-1.3.1-bin-hadoop1.tgz rm -r kuromoji-0.7.7
上記インストール手順を実行後、以下の動作確認コマンドを実行する。
# Sparkのインストール確認方法(Sparkの起動) /opt/spark/bin/spark-shell --driver-memory 3g --jars /opt/spark/lib/kuromoji-0.7.7.jar scala> import org.atilika.kuromoji._ import org.atilika.kuromoji._ // と表示されれば正常にインストールが完了されている。
「 import org.atilika.kuromoji._ 」
と入力し、エンターを押下後、再度、
「 import org.atilika.kuromoji._ 」
と表示されれば、問題無くインストールは完了している。
「 <console>:19: error: object atilika is not a member of package org 」
などが表示される場合は、Kuromojiのインストールに失敗しているか、Apache Sparkの起動コマンドが誤っている可能性があるので確認頂きたい。
サンプルプログラムの実行
前述のように、サンプルプログラムは、モデルの学習用サンプルプログラムと、モデルの適用用サンプルプログラム(実際はワンラインだが・・・)の2種を用意している。各サンプルプログラムの入出力データについて以下の表に記述する。
| 学習フェーズ入力 | Wikipedia ja の概要ダンプデータファイル |
|---|---|
| 学習フェーズ出力 | 学習結果のモデル |
| 適用フェーズ入力 | 類似語を知りたい単語 |
| 適用フェーズ出力 | 類似語リスト |
まずは、モデルの学習用サンプルプログラムを以下に示す。Wikipediaのデータファイルを読み込み、それを形態素解析した上で、Word2Vecライブラリでモデルを学習する流れとなっている。
モデル学習サンプルプログラム
import scala.collection.convert.WrapAsScala._
import org.apache.spark.mllib.feature.Word2Vec
import org.atilika.kuromoji._
// XMLから必要情報のみを抜き出すための正規表現
val replacePatterns = "<.*?>|\\[\\[.*?\\]\\]|\\[.*?\\]||\\{\\{.*?\\}\\}|\\=\\=.*?\\=\\=|>|<|"|&| |-|\\||\\!|\\*|'|^[a-zA-Z\\:\\;\\/\\=]$|;|\\(|\\)|\\/|:"
// 名詞のみの分かち書きテキスト配列を作成
val input = sc.textFile("jawiki-latest-abstract.xml").map(line => {
val tokens : java.util.List[Token] = Tokenizer.builder().build().tokenize(line.replaceAll(replacePatterns, ""))
val output : StringBuilder = new StringBuilder();
tokens.foreach(token => {
if(token.getAllFeatures().indexOf("名詞") != -1) {
output.append(token.getSurfaceForm())
output.append(" ")
}
})
output.toString() // return
}
).map(line => line.split(" ").toSeq)
// 分かち書きテキスト配列をWord2Vecに与えて学習
val Word2Vec = new Word2Vec()
val model = Word2Vec.fit(input)
続いて、モデル適用のサンプルを示す。モデルを用いて類義語を表示する操作は、下記の1行にて実行できる。「[類似語を知りたい単語]」の箇所の単語を変えることで、任意の単語の類似語を推定できる。
モデル適用サンプルプログラム
for((synonym, cosineSimilarity) <- model.findsynonyms("[類似語を知りたい単語]",="" 40))="" {="" println(s"$synonym="" $cosinesimilarity")="" }="">
サンプルプログラムの実行
それでは、Apache Sparkを起動し、先述のサンプルプログラムを実行してみよう。 まず、Wikipediaから元となるWikipediaのデータをダウンロードし、Apache Sparkを起動する。起動後「モデル学習サンプルプログラム」を実行した上で、「モデル適用サンプルプログラム」を実行する。
# 元データの準備(Wikipediaデータのダウンロード) cd wget http://dumps.wikimedia.org/jawiki/latest/jawiki-latest-abstract.xml # Apache Sparkの起動 /opt/spark/bin/spark-shell --driver-memory 3g --jars /opt/spark/lib/kuromoji-0.7.7.jar ## 「学習プログラム」をSpark-Shellにそのまま貼り付けて学習の実行を開始する。 ## 「学習プログラム」の実行が完了後、「類似語推定プログラム」をSpark-Shellにそのまま貼り付けて推定したい類義語を指定し、実行を行う。
実行結果のサンプルとして、「Mac」の類似語を検索した際のキャプチャを掲載する。
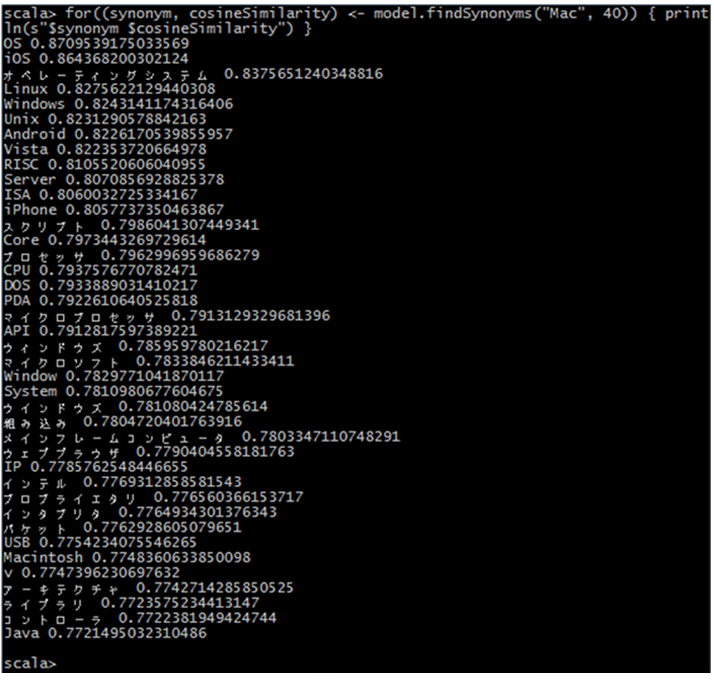
「OS」、「オペレーティングシステム」など所属する製品のジャンルや、「Linux」「Windows」「Unix」などの類似した製品名などが類似語としてヒットしている。なお、横の数値は、「Mac」と推定された類似語のそれぞれのベクトル間のコサイン距離であり、それを類似度として用いている。
また、処理時間については、Wikipediaのデータは1.6GBほどあり、手元の1台のPCにて実行した際は、「モデル学習サンプルプログラム」の実行に5時間ほどを要した。もしもリソースに余裕があるのならば、Apache Sparkはクラスタ化して実行した方が良いであろう。一方、構築したモデルを用いての類似語推定の処理時間は数秒ほどであるので、特に意識する必要はない。
Apache SparkでのWord2Vecモデルの活用
機械学習で最も処理時間が必要となるモデルの学習において、Apache Sparkのアーキテクチャーを用いることで効率的な分散処理が可能となり、処理時間の短縮につながることは先述した。それに加え、MLlibにて構築したモデルはSpark Streaming内での適用も可能なため、ストリーミングデータに対してリアルタイムにモデル適用処理を容易に行うことができ、機械学習の利用用途が広がるものと考えている。
例えば、Spark Streaming内でWord2Vecモデルを利用した例として考えられるものは、「ソーシャルメディア上のお客さまの声を集めてアラーティングやレポートを作成するシステム」が考えられる。
モデルのみを日次や週次で作成し、そのモデルをSpark Streaming内でストリーミングデータに対して活用することにより、より高度なアラートシステムを構築することができる。例えば、製品名をキーワードにソーシャルデータをフックする際、日々モデルを学習することで、ユーザの中で生まれた略語などを学習し、特に手間をかけずにそれらの単語でも製品関連の情報を拾うことができるようになるだろう。
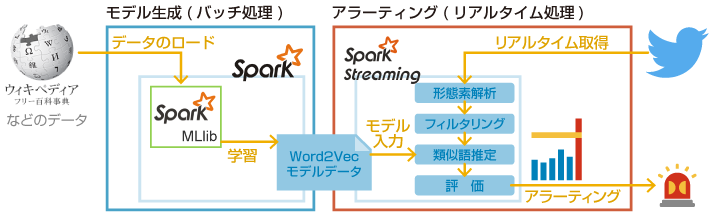
このように、機械学習を利用する際にApache Sparkを用いることで、
- 学習処理の処理時間短縮(および、スケールアウトの実現)
- Spark Streamingなどの他のSparkエコシステムとの連携の可能性
という2つの大きな利点を得ることができる。
Tweet