















第5回「設定パラメーターの管理」
Tweet
前回のコラムでは、システムを構築する「プログラム」が使う情報の取得と管理について説明しました。今回はシステムを構築する「プログラム」が使うアプリケーション設定パラメーターなどのシステムから取得する以外の情報管理について説明します。
当たり前の話ではありますが、システムから取得できない情報は自動化ツール側で管理する必要があります。
システム構築するには、前回紹介しましたシステムから取得できる情報以外にも、インストールするアプリケーションなどに設定するパラメーターなど、人間が決めている情報が必要です。ですが、それらの情報をシステムを構築する「プログラム」の中にハードコーディングしてしまうと、同じような構成のサーバーを作る場合でも、サーバー台数分のコードブロックが必要になってしまいますし、何より非効率的です。
そのため自動化ツール側ではホスト名などのユニークな名称をキーとして情報を管理し、「プログラム」から取得できるようにする、データを管理する機構があります。
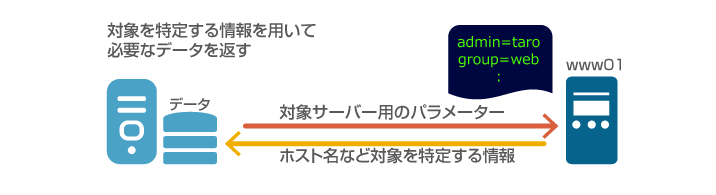
これらの機構について紹介します。最初にPuppetの場合です。
Puppetには“Hiera”と呼ばれる、key/value型のデータストアが実装されています。Hieraを使うとアプリケーションの設定パラメーターやノード固有の情報などを必要に応じてPuppetの「プログラム」である「マニフェスト」から呼び出す事ができます。また、データソースをYAML形式もしくはJSON形式で記述します。
このHieraが大きな特徴は、データソースを階層(Hierarchy)化できるところです。Hieraという名前からも何となく連想はできますね。具体的にはデータソースとなるYAML形式もしくはJSON形式のファイルに優先順位を付けています。keyからvalueを探す時は、この優先順位に従ってデータソースを参照します。
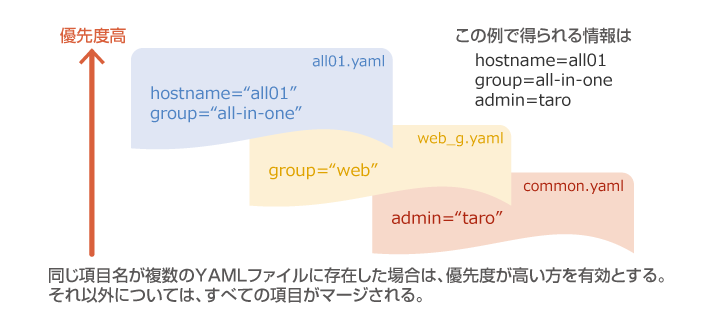
この階層構造によって、特に指定しない場合に使うデフォルト値を定義しておき、その上にノードグループ単位での指定値や特定のノードに対する指定値をオーバーライドする事ができます。この仕組みにより、最初に標準的な設定値をデフォルト値として定義しておけば、以降はデフォルト値との差分だけをノードグループやノード固有の値として定義すればよくなりますので、同じような設定を繰り返し記述しないで済みます。それは結果としてメンテナンスの手間を軽減し、マニフェストを修正する事なくモジュールの再利用を可能にしています。
Hieraで定義したデータはhiera関数にて呼び出すほか、クラスという一般の言語でのライブラリに相当するものに与えるパラメーターを“Automatic Parameter Lookup”という機能によって、クラスを呼び出す際にパラメーターの指定をしなくても、自動的にHieraからパラメーターを取得するようになります。
簡単ですが具体的な例を以下に示します。Hieraのデータは以下のように記述します。
myclass::username: "taro" myclass::userhome: "/home/taro"
これを呼び出すマニフェストは以下のようになります。
class myclass($username, $userhome){
notify {$username:}
notify {$userhome:}
}
include myclass
このようにクラスの引数にする変数名とHiera側で記述する項目名を“クラス名::引数の変数名”とすると、Automatic Parameter LookupによってHieraから自動的にパラメーターを取得します。また、Hieraのデータを明示的に呼び出す場合で、データがクラスとは無関係な場合は、「something: "data"」のように任意の項目名でも問題ありません。前述のデータを明示的に呼び出すには以下のようにします。
$username = hiera("myclass::username","")
$userhome = hiera("myclass::userhome","")
notify {$username:}
notify {$userhome:}
その他のHieraについて詳細は、以下のURLを参照してください。
次にChefの場合です。Chefには“Data Bag”と呼ばれる任意のデータを格納する機構があります。データはJSON形式で記述します。chef-solo環境の場合は、記述したJSONデータファイルをdata_bag_pathで指定されているディレクトリに、Data Bag名でサブディレクトリを作成して格納します。複数のJSONデータファイルを同じディレクトリに格納する事もできます。Chef Serverの場合は“knife data bag from file”コマンドで格納できます。
Data Bagの特徴は、Chefの「プログラム」である「レシピ」からRubyのハッシュとしてアクセスできるところです。ハッシュとして取得したデータをeachメソッドを使って読み出していきます。
データの記述例を以下に示します。
{
"id": "admin_users",
"users": [
{
"name": "taro",
"home": "/home/taro",
}
]
}
まずData Bagでは“id”という項目を使ってデータを管理するため、必ず記述する必要があります。他の項目はData Bagで管理するデータになります。Data Bagのデータをレシピから呼び出す手順を、以下に示します。
databag = data_bag('admin_users')
databag.each do |d|
item = data_bag_item('admin_users', d)
item['users'].each do |u|
log u['name']
log u['home']
end
end
これは、さきほどのデータをData Bagから読み出してログに出力するだけのサンプルです。最初にData Bag名を引数としてdata_bag関数を呼び出してData Bagを取得します。次にData Bag名と取得したData Bagを引数に呼び出し、個々のデータを得る流れになります。またRubyのハッシュそのものであるため、HieraのようにData Bagの優先順位を設けたい場合は、何らかの方法で実装する必要はあります。
その他のData Bagについての詳細は、以下のURLを参照してください。
次にAnsibleの場合です。Ansibleはとてもシンプルです。変数idとリストusersを定義して利用するサンプルを記載します。
site.yml
- hosts: dbserver
vars:
- id: admin_users
- users:
- name: taro
home: /home/taro
- name: jiro
home: /home/jiro
tasks:
- debug: msg="id : {{ id }}"
- user: name={{ item.name }} state=present home={{item.home}
with_items: users
上記と同じ用に変数idとハッシュリストusersを定義した例です。変数へのアクセスは、{{ 変数名 }}と記述するだけです。リストを利用したユーザ作成のタスクも以下のように簡潔に記述できます。
- user: name={{ item.name }} state=present home={{item.home}
with_items: users
with_itemsでitemにusersの配列の要素を取得し、item.nameとitem.homeで各ユーザ名とホームディレクトリのパスを直感的に取得できます。
上記のように定義してしまうと、すべてのサーバーで同じ変数値が設定されます。インベントリを使うと、サーバーグループ毎の変数を簡単に定義できます。例えば、WebサーバーとDBサーバーでuserという変数名を切り替えたいとします。プレイブックではなく、インベントリ(/etc/ansible/hosts)に記述することによって、簡単にサーバー毎の設定を記述することができます。
/etc/ansible/hosts
[dbservers] 192.168.1.1 192.168.1.2 [dbservers:vars] user=postgres [webservers] 192.168.11.1 192.168.11.2 user=custom [webserver:vars] user=apache
上記の例は、dbserversで定義されたホストに対して処理するときは、user変数にpostgresを、webserversで定義されたホストに対して処理するときは、user変数にapacheを設定する例です。ただし、192.168.11.2のホストにだけは、user変数にcustomを設定します。
このように、Ansibleでは、サーバーグループの環境やホスト固有の環境を変数で簡単に定義することができます。
その他のInventoryについての詳細は、以下のURLを参照してください。
Tweet