















第1回「テーブル・パーティショニング」
本記事ではPostgreSQL 10の新機能のひとつである「テーブル・パーティショニング」について紹介します。
テーブル・パーティショニングとは?
テーブル・パーティショニングとは、テーブル内のデータを分割して保持する機能です。データを分割することで性能や運用性が向上します。特に、巨大なテーブルを保持している場合は、テーブル・パーティショニングは有効な手段のひとつです。
テーブル・パーティショニングの用途については、こちらをご覧ください*1。
- *1 PostgreSQL 9.6の日本語マニュアルなので、本コラムで紹介する新しい方式のテーブル・パーティショニングの記述はありません
新機能"テーブル・パーティショニング"とは?
テーブル・パーティショニング自体はPostgreSQL 10以前のバージョンでも使うことはできました。ただし、テーブル・パーティショニング専用の機能はなく、複数の別機能を組み合わせる事で、"テーブル・パーティショニングのような機能"を実現していました。そのため、性能、運用性、拡張性などの多くの面で課題を持っていました。
そこで、NTT OSSセンタのAmit Langote氏を主導に開発されたのが、新しい「テーブル・パーティショニング」です。本機能では、テーブル・パーティショニング専用のDDL(Data Definition Language)が導入されただけでなく、旧方式のテーブル・パーティショニングに比べて性能、運用性が改善されています。
テーブル・パーティショニングは、やりたいことに応じてテーブルを分割する仕組み(機能)ですが、その分割方法について、PostgreSQL 10のテーブル・パーティショニングでは、"リスト方式"と"レンジ方式"の2つの方法をサポートしています。リスト方式では、いくつかの選択肢から値を選ぶ列がある場合に、その値に応じてテーブルを分割します。一方、レンジ方式では、値の範囲ごとにテーブルを分割します。さらに、子テーブルの追加(Attach)、取り外し(Detach)などの運用管理もコマンドひとつで実行することが可能です。
使い方
本章では、テーブル・パーティショニングの基本的な使い方について、例を用いて紹介します。(図1参照)
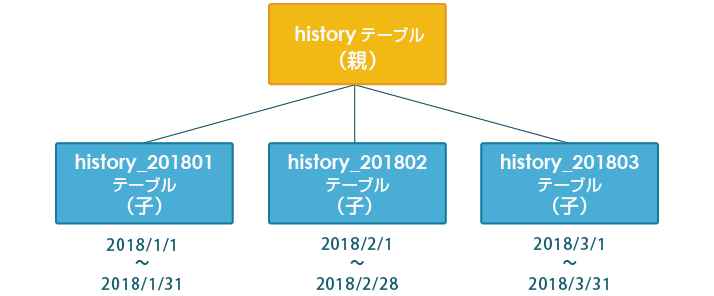
図1 レンジ・パーティショニングを用いた例:親テーブルと3つの子テーブル
まずは、イベント履歴を保持する親テーブル(historyテーブル)を作成し、イベント発生日時(logdate列)をレンジ方式で分割します。
-- 親テーブルの作成 =# CREATE TABLE history (event_id int, logdate date) PARTITION BY RANGE (logdate);
親テーブル作成時には、CREATE TABLEの後に「PARTITION BY 分割方式 (列名)」と指定し、分割方式には「RANGE」または「LIST」を指定し、列名にはパーティションキーとなる列の列名をひとつ以上指定します。
次に、各月ごとのデータを格納するテーブルを子テーブルとして3つ作成します。
-- 2018年1月用のテーブルを作成
=# CREATE TABLE history_201801 PARTITION OF history FOR VALUES FROM ('2017-01-01') TO ('2017-02-01');
CREATE TABLE
-- 2018年2月用のテーブルを作成
=# CREATE TABLE history_201802 PARTITION OF history FOR VALUES FROM ('2017-02-01') TO ('2017-03-01');
CREATE TABLE
-- 2018年3月用のテーブルを作成
=# CREATE TABLE history_201803 PARTITION OF history FOR VALUES FROM ('2017-03-01') TO ('2017-04-01');
CREATE TABLE
レンジ方式での子テーブルの作成では、各子テーブルが格納するパーティションキーの値の上限値、下限値を設定します。下限値に設定した値は含まれ、上限値に設定した値は含まれないことにご注意ください。
パーティション・テーブルの情報は"\d+ テーブル名"コマンドで確認することができます。
-- テーブルの定義情報を確認する
=# \d+ history
Table "public.history"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+---------+--------------+-------------
event_id | integer | | | | plain | |
logdate | date | | | | plain | |
Partition key: RANGE (logdate)
Partitions: history_201801 FOR VALUES FROM ('2017-01-01') TO ('2017-02-01')
history_201802 FOR VALUES FROM ('2017-02-01') TO ('2017-03-01'),
history_201803 FOR VALUES FROM ('2017-03-01') TO ('2017-04-01'),
次に、いくつかデータを挿入し、各子テーブルにどのようにデータが入っているかを見てみます。
-- データを4件挿入
=# INSERT INTO history VALUES (1, '2017-01-10'), (2, '2017-01-12'), (3, '2017-02-02'), (4, '2017-03-29');
INSERT 4
-- 親テーブルを参照する。全子テーブルの情報をまとめて参照できる。
=# SELECT * FROM history;
event_id | logdate
----------+------------
1 | 2017-01-10
2 | 2017-01-12
3 | 2017-02-02
4 | 2017-03-29
(4 rows)
-- 各子テーブルを参照する。各子テーブルに格納されているデータのみが参照できる。
=# SELECT * FROM history_201801;
event_id | logdate
----------+------------
1 | 2017-01-10
2 | 2017-01-12
(2 rows)
=# SELECT * FROM history_201802;
event_id | logdate
----------+------------
3 | 2017-02-02
(1 row)
=# SELECT * FROM history_201803;
event_id | logdate
----------+------------
4 | 2017-03-29
(1 row)
パーティション・テーブルへの挿入では、親テーブルを指定することで対応する子テーブルへと振り分けられます。そして、実際のデータは各子テーブルに入っていますが、親テーブル(historyテーブル)を指定して読み込んだ場合は、すべての子テーブルに格納された情報を透過的に見ることができます。
また、挿入した値に対応する子テーブルが存在しない場合は、エラーとなります。
-- データ1件挿入。2017-04-01に対応する子テーブルは存在しないためエラーになる =# INSERT INTO history VALUES (5, '2017-04-01'); ERROR: no partition of relation "history" found for row DETAIL: Partition key of the failing row contains (logdate) = (2017-04-01).
さらに、特定の子テーブルをパーティション・テーブルから取り外す(Detach)ことや、既存のテーブルを新しい子テーブルとして追加することも可能です。
-- 1月用の子テーブルを親テーブルから取りはずす
=# ALTER TABLE history DETACH PARTITION history_201801;
ALTER TABLE
-- 4月用のテーブルを通常のテーブルとして作成
=# CREATE TABLE history_201804 (LIKE history);
CREATE TABLE
-- 4月用の子テーブルを親テーブルに取り付ける
=# ALTER TABLE history ATTACH PARTITION history_201804 FOR VALUES FROM ('2017-04-01') TO ('2017-05-01');
ALTER TABLE
-- 4月のデータを1件挿入。対応するテーブルが存在するので、INSERTは成功する
=# INSERT INTO history (5, '2017-04-01');
INSERT 1
-- 親テーブルを参照する。2月,3月,4月のデータが取得できる
=# SELECT * FROM history;
event_id | logdate
----------+------------
2 | 2017-01-12
3 | 2017-02-02
4 | 2017-03-29
5 | 2017-04-01
(4 rows)
テーブル・パーティショニングによる性能向上
PostgreSQL 10のテーブル・パーティショニングでは、これまで紹介したような運用性の向上の他、パーティション・テーブルに対するINSERT性能も向上しています。
PostgreSQL 9.6以前のテーブル・パーティショニングで、あらかじめ用意したトリガーとストアド・プロシージャを用いて、振り分け先のテーブルを選定する必要があったため、オーバヘッドが大きく、通常テーブルへのINSERT性能よりも大きく性能が落ちる課題がありました。一方、PostgreSQL 10で採用している新しい方式ではPostgreSQL内部のコードで振り分け先を決定します。その結果、子テーブルへの振り分けのためのオーバヘッドが格段に小さくなり、INSERT性能が向上しました。(図2参照)
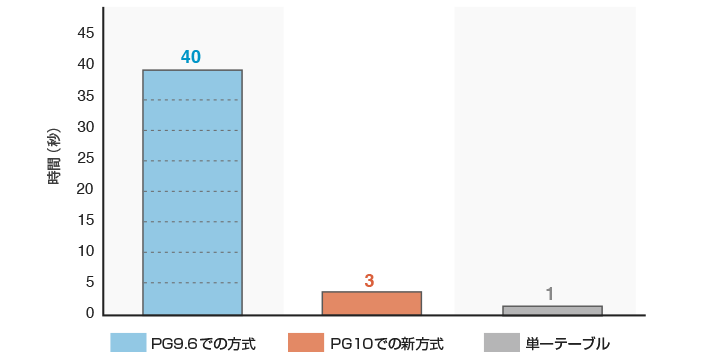
図2 約100万件データのINSERTに要した時間
検索については、PostgreSQL9.6以前のテーブル・パーティショニングと同様の仕組みを使用しているため、性能に大きな違いはありません。
テーブル・パーティショニングの制約
PostgreSQL 10ではまだいくつか使用上の制約があります。以下にいくつか例を列挙します。
- 挿入する値に対応する子テーブルがない場合はエラーとなる
- ハッシュパーティショニングに対応できない
- パーティションを跨った一意制約を付けることができない
- 子テーブル数が多くなるに連れて、プランニング時間が増大する
- パーティションを跨ったUPDATEができない
- 外部テーブルの子テーブルにはINSERTができない
など
これらの制約はPostgreSQLコミュニティで改善が進められており、いつかの制約については次期バージョン(PostgreSQL 11)で修正される見込みです。
テーブル・パーティショニングの改善
PostgreSQLの開発コミュニティではPostgreSQL 11のリリースに向けて、多くの機能が開発されています。その中でもテーブル・パーティショニングは最も開発されている機能の一つであり、多くの開発者がパッチを投稿しています。すでに取り込まれている機能をいくつか紹介します。
- Hash Partition
- パーティションキーのハッシュ値を元にテーブルを分割する機能。各子テーブルに均等にデータを割り振ることができる。
- Default Partition
- 対応する子テーブルが存在しない場合、エラーとなる代わりに、指定した子テーブルにデータを格納する機能。
- Partition-wise Join
- パーティション・テーブル同士のJoinの際に、子テーブル同士を先にJoinし、それぞれのJoin結果をAppendする。不要なJoinが減ることで性能が向上する。
また、テーブル・パーティショニングは、単一データベース内にてテーブルを分割するだけでなく、FDW(Foreign Data Wrapper)機能と組み合わせることで、データベース・シャーディング にも利用することが可能です。詳細については、次回以降のコラムで紹介する予定ですが、興味のある方はPGConf.ASIA 2017の発表資料をご参照ください。
- PostgreSQL Built-in Sharding -Enabling big data management with the blue elephant
http://www.pgconf.asia/JA/2017/wp-content/uploads/sites/2/2017/12/D2-B1.pdf
まとめ
本記事では、PostgreSQL 10で導入されたテーブル・パーティショニングについて紹介しました。PostgreSQL 10ではバージョン9.6以前からの方式と、バージョン10から導入された新しい方式の両方が使用できますが、多くの面で優れているので後者を選択することをおすすめします。 テーブル・パーティショニングはPostgreSQLコミュニティ内でも注目を浴びている機能であり、多くの改善が現在進行形で進んでいます。今後もさまざまな改善や新機能が導入されるのが楽しみですね。
(澤田 雅彦)
Tweet