















第2回「Hashインデックス」
本記事ではPostgreSQL 10の新機能のひとつである「ハッシュインデックス」について紹介します。
PostgreSQLではB-tree、Hash、Gist、SP-Gist、GIN、BRIN、bloomの7種類のインデックスをサポートしています。データベースのインデックスとして一番良く使われるインデックスはB-treeインデックスですが、PostgreSQL 10で強化されたHashインデックスはどのようなインデックスで、どのような用途に向いているインデックスなのでしょうか。本コラムでは「Hashインデックス」について、その概要、改善点などを紹介します。
Hashインデックスとは?
PostgreSQLのHashインデックスでは、Hash関数を使用し、キーのHash値とそのレコードの物理位置(TID: Tuple ID)を格納します。例えば、値を100で割ったときの余り返す関数をHash関数とした場合、ID=234のHash値は34になり、この34に対応する位置にHash値とTIDを格納します(図 1参照)。検索時も同様に、検索キーのHash値を元にHashインデックスを検索することで、目的のデータを取得します。
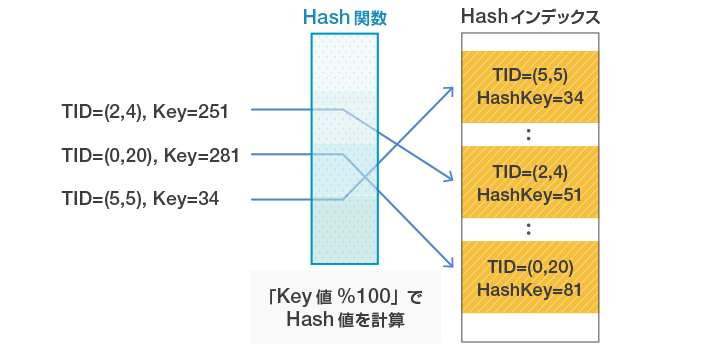
図1 Hashインデックスへの格納
ツリー型のB-treeインデックスでは、目的のキーを検索するために、ツリーのルート(根)から順にツリー構造を辿りますが、HashインデックスではHash値を求めるだけで検索できます。したがって、Hash関数により上手くデータが分散している場合は、ほぼ定数時間O(1)で検索できることが、Hashインデックスの最大の特徴です。これは、検索だけでなく挿入、更新、削除でも同様です。しかし、Hashインデックスには、一致検索しか行えないという制約があります。不一致検索、範囲検索をすることはできません(表 1)。また、検索結果の順序は保証されないため、ソート処理の手助けにもなりません。
| 検索の種類 | B-tree | Hash |
|---|---|---|
| 一致 (=) | ○ | ○ |
| 大小比較 (<,><=,>, >=) | ○ | × |
| 不一致 (!=, <>) | ○ | × |
ハッシュ関数は、原理上、異なる複数のキーに対して、同じHash値を結果として返すことが起こり得ます*1。そのため、Hashインデックスを用いた検索では、インデックスを用いた検索の後に、再度検索結果の正当性を確認する処理(Recheck処理と呼ばれます)を行います。
PostgreSQL 10での改善点
PostgreSQLは古くからHashインデックスをサポートしています。しかし、バージョン9.6までのHashインデックスはWAL(トランザクションログ)に未対応だったため、データの永続性の問題や、ストリーミングレプリケーションとの相性の悪さなど、さまざまな問題を抱えていました。そのため、PostgreSQLの公式ドキュメント*2でも以下のようにHashインデックスの利用は推奨されていませんでした。
現在ハッシュインデックス操作はWALに記録されません。そのため、データベースクラッシュの後ハッシュインデックスをREINDEXで再構築しなければならない可能性があります。また、ストリーミングレプリケーションやファイルベースのレプリケーションでは複製されません。この理由により、ハッシュインデックスの使用は現在お勧めできません。
PostgreSQL 10では以下の点が強化されました。
- WAL(トランザクションログ)対応
- 性能向上
- *1: 例えば、冒頭の例だとID=234とID=334からは同じHash値(34)が計算されます
- *2: https://www.postgresql.jp/document/9.6/html/indexes-types.html
これにより、PostgreSQL 10のドキュメントでは、非推奨という注意書きが外され、Hashインデックスは他のインデックスと同じように利用できるようになりました。
Hashインデックスの使い方
Hashインデックスの使い方について例を用いて紹介します。
まずは、テーブルとデータを用意し、Hashインデックスを作成します。Hashインデックスの作成では、CREATE INDEX文のUSING句の後に「hash」を指定します。
-- テーブルを作成 =# CREATE TABLE test (c int); CREATE TABLE -- 1万行をINSERT =# INSERT INTO test SELECT generate_series(1, 10000); INSERT 10000 -- c列に対しHashインデックスを作成 =# CREATE INDEX test_hashidx ON test USING hash (c);
Hashインデックスを使ってデータを検索してみましょう。c = 100を検索してみます。
=# EXPLAIN SELECT * FROM test WHERE c = 100;
QUERY PLAN
-----------------------------------------------------------------------
Index Scan using test_hashidx on test (cost=0.00..8.02 rows=1 width=4)
Index Cond: (c = 100)
Index Scanが選択され、先程作成したHashインデックスが使用されていることがわかります。次に、範囲検索を試してみます。
=# EXPLAIN SELECT * FROM test WHERE c < 10;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on test (cost=0.00..17.50 rows=100 width=4)
Filter: (c < 10)
Hashインデックスは使用されず、Seq Scan(逐次スキャン)が選択されました。前述の通り、Hashインデックスは一致検索のみをサポートしているため、範囲検索をした場合、Hashインデックスは使われません。
B-treeインデックスとの比較
B-treeインデックスとインデックスサイズ、一致検索性能を比較してみます。まずはインデックスサイズです。
インデックスサイズの比較
INT型とTEXT型の2列あり、1億行のレコードが格納されているテーブルを用意しました。TEXT型の列には64バイトのランダム文字列が格納されています。INT型列、TEXT型列のそれぞれにHashインデックスとB-treeインデックスを作成し、インデックスサイズを比較します。
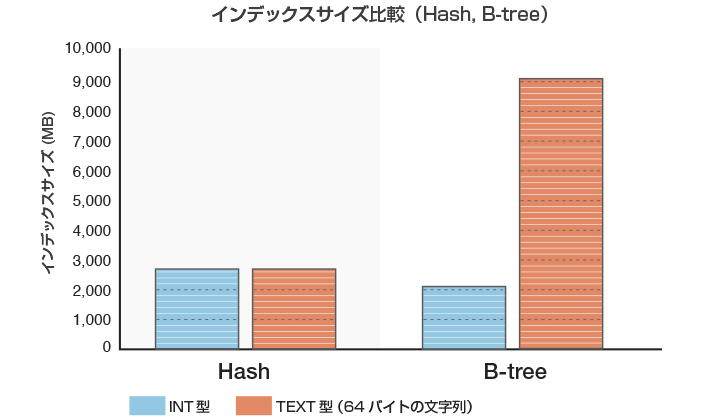
図2 インデックスサイズ比較(テーブルサイズは10GB)
図の通り、Hashインデックスではインデックスキーの大きさ(TEXT型、INT型)によらずインデックスサイズが一定になっています。これは、Hashインデックスでは、インデックスキーではなく「インデックスキーのHash値*3」のみを格納するためです。そのため、Text型などの列サイズが大きい場合は、キー全体をインデックスに保存するB-treeインデックスに比べて、インデックスサイズが小さくなりました。
- *3: 4バイトのHash値を格納します
検索時間の比較
次に、テーブルからデータを1件取得する検索で検索性能を比較してみます。
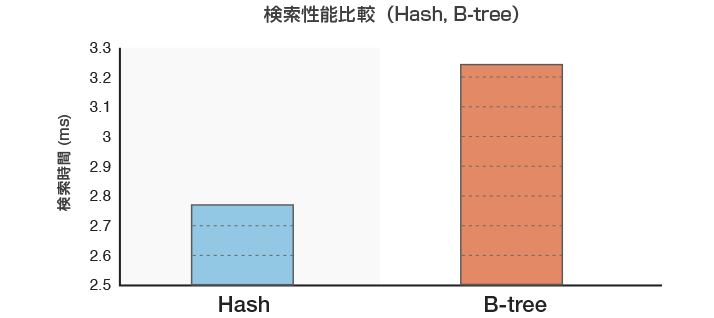
図3 検索性能比較(一致検索を5回実施した平均値)
Hashインデックスの方が、検索性能が高い結果となりました。インデックスデータのキャッシュヒット率にも依存しますが、テーブルのレコード数が多いほど、その効果は大きくなるでしょう。
Hashインデックスの内部構造
Hashインデックスの内部構造について解説します。Hashインデックスは、バケットと呼ばれる単位で論理的に分割されています。各バケットは一つ以上のブロック*4から構成されており、インデックスエントリはブロックに格納されます(図4)。
- *4: PostgreSQLが管理するテーブル、インデックス領域の最小単位
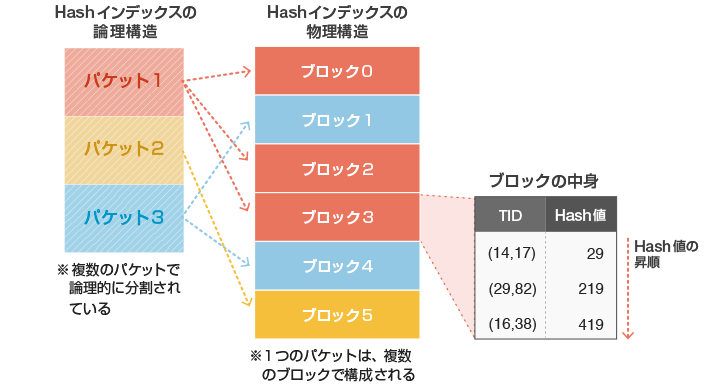
図4 Hashインデックスの内部構造
Hashインデックスにデータを登録する際は、まずHash値からバケット番号を算出します。そして、算出したバケット番号を元に、構成するブロックを探索し、空き領域のあるブロックにインデックスエントリを格納します。バケット数はインデックスに格納されるデータ量によって動的に増加しますが、バケット数が増加しても、Hashインデックス内のデータの移動は必要がないように作られています。
インデックスキー = 1150であるデータの挿入を例に見てみましょう(図 5)。キーからHash値(=150)と、バケット番号(=1)が算出されます。1番バケットは、ブロック0、ブロック2、ブロック3から構成されていますので、その中から順に空きのあるブロックを探し(例では3番ブロックに挿入しています)、ブロック内ではHash値の昇順になるように挿入します。
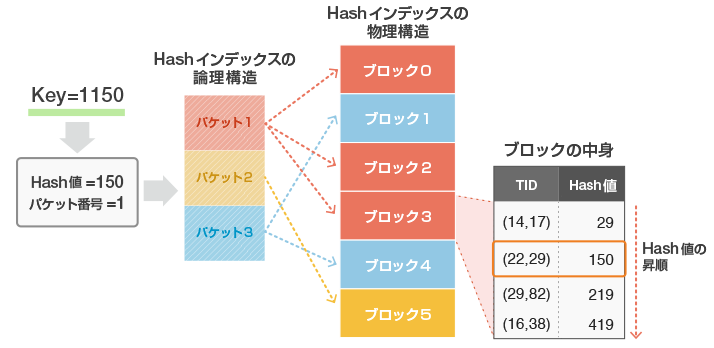
図5 Hashインデックスの内部構造(新しいインデックスを追加)
ブロック内でHash値の昇順となるように格納するのはなぜでしょうか?これは、ブロック内の検索を高速に行うためです。異なるHash値から同じバケット番号が算出される事があるため、一つのバケットにはHash値が異なる複数のインデックスエントリが格納されます。そのため、ブロック内のインデックスエントリの格納をHash値の昇順で格納することにより、ページ内の検索を二分探索で検索できるようにしています。
Hashインデックスの中身を確認
pageinspectモジュール*5を利用することで、Hashインデックスの内部の情報を確認することができます*6。
=# CREATE EXTENSION pageinspect;
=# SELECT * FROM hash_page_items(get_raw_page('hoge_hash', 10)) LIMIT 15; -- 10番ブロックの中身を出力するSQL
itemoffset | ctid | data
-----------+------------+----------
1 | (4322,148) | 27262985
2 | (3880,196) | 27262985
3 | (3437,18) | 27262985
4 | (2995,66) | 27262985
5 | (2552,114) | 27262985
6 | (2110,162) | 27262985
7 | (1667,210) | 27262985
8 | (1225,32) | 27262985
9 | (787,80) | 27262985
10 | (349,128) | 27262985
11 | (4001,180) | 36700169
12 | (3554,2) | 36700169
13 | (3106,50) | 36700169
14 | (2758,98) | 36700169
15 | (2210,146) | 36700169
(15 rows)
1つのインデックスエントリにつき1行で表示されます。1列目はインデックスエントリのオフセット、2列目は各インデックスエントリが指すTID、3列目はインデックスキー値に対するHash値を表しています。3列目(data列)が昇順になっていることが確認できます。
- *5: contribモジュールとしてPostgreSQLに同梱されています
- *6: PostgreSQL 10.1のpageinspectには間違った結果を返すバグが含まれているため、バージョン10.2以降のpageinspectを利用する事を推奨します。
まとめ
今回はPostgreSQLのHashインデックスについて解説をしました。Hashインデックスは利用用途が限られますが、一致検索においては、B-treeに比べて低コストで実行すること、そして、インデックスサイズが一定になることが強みです。一致検索で安定した早い性能が必要な場合は、ぜひHashインデックスの利用を検討してみてください。
PostgreSQL開発コミュニティ速報 - PostgreSQL 11がFeature Freeze
PostgreSQL開発コミュニティにて開発が進められているPostgreSQL 11がFeature Freezeを迎えました。Feature Freezeは、これ以上新しい機能が追加されない事を意味しており、これからは2018年9月頃に予定されている正式リリースに向けて、品質向上フェーズに入ります。PostgreSQL 11で導入される予定の機能の一部を紹介します*7。
- テーブル・パーティショニングの改善(Hashパーティショニングやパーティション全体での一意制約)
- プロシージャ内でのトランザクション制御
- LLVMを用いたJITコンパイル基盤
- CREATE INDEXのパラレルクエリサポート(B-treeインデックスのみ)
最新のPostgreSQLのソースコードは、https://github.com/postgres/postgres*8から取得できます。ぜひ最新のPostgreSQLを試してみてください!
- *7: 正式リリースまでに変更される可能性があります
- *8: PostgreSQLの公式ミラーリポジトリです
(澤田 雅彦)
Tweet