















第2回「PostgreSQL11でのテーブル・パーティショニング機能の改善」
PostgreSQL 11では、デーブル・パーティショニング機能が大幅にアップデートされる予定です。本コラムでは2回に分けてテーブル・パーティショニング機能にどのような改善が導入されたかを徹底解説していきます。今回は、以下の機能を紹介します。
パーティション・プルーニングの改善
パーティション・プルーニングは、クエリによって要求されるデータを含まないパーティションへのスキャンをスキップする機能です。このようなクエリには、パーティション・キーに対する条件が含まれます。サーバーは、条件内の他のパラメーター値とパーティション境界を比較することで、パーティションを絞り込むことが可能です。
以下の例を考えてみましょう。
CREATE TABLE orders (id int, order_date date) PARTITION BY RANGE (order_date);
CREATE TABLE orders_nov18 PARTITION OF orders FOR VALUES FROM ('2018-11-01') TO ('2018-12-01');
CREATE TABLE orders_dec18 PARTITION OF orders FOR VALUES FROM ('2018-12-01') TO ('2019-01-01');
CREATE TABLE orders_jan19 PARTITION OF orders FOR VALUES FROM ('2019-01-01') TO ('2019-02-01');
SELECT COUNT(*) FROM orders WHERE order_date = '2018-11-05';
上記のクエリは、他のパーティションは、order_date列に2018-11-05の値を含まないため、orders_nov18パーティションのみを調べる必要があります。パーティション・プルーニングは他のパーティションがスキャンされないようにします。
古いPostgreSQL(バージョン10を含む)は、これらのデータとパーティション境界を直接比較しません。その代わりに、PostgreSQLの「Constraint Exclusion」という機能を利用いて最適化を行っていました。Constraint Exclusionは、クエリの条件とパーティションの制約(CHECK制約のような形)を比較して、制約がクエリの条件と矛盾するパーティションを「除外」としてマークします。
\d+ orders_dec18
Table "public.orders_dec18"
Column │ Type │ Collation │ Nullable │ Default │ Storage │ Stats target │ Description
────────────┼─────────┼───────────┼──────────┼─────────┼─────────┼──────────────┼─────────────
id │ integer │ │ │ │ plain │ │
order_date │ date │ │ │ │ plain │ │
Partition of: orders FOR VALUES FROM ('2018-12-01') TO ('2019-01-01')
Partition constraint: ((order_date IS NOT NULL) AND (order_date >= '2018-12-01'::date) AND (order_date < '2019-01-01'::date))
WHERE条件のorder_date = 2018-11-05はorders_dec18とorders_jan19のパーティション制約と矛盾することは明確です。そのため、これらのパーティションはクエリの実行計画から除外され、以下のようになります。
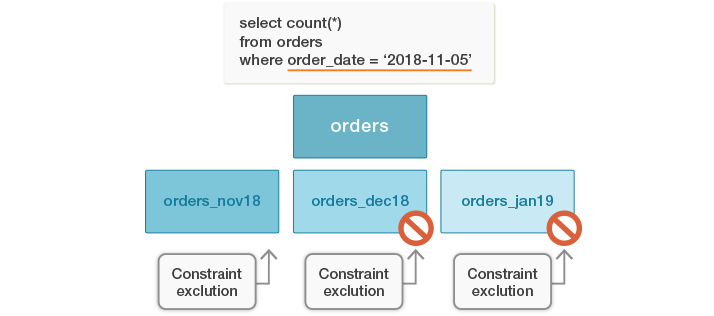
constraint exclusionのより詳細な情報は公式ドキュメントをご参照ください。
ドキュメントに記載の通り、constraint exclusionは各パーティションを個別に検討する必要があり、計算コストがかかるため、パーティションの数に応じてスケールしませんでした。
PostgreSQL11では、クエリの条件を分析し、パーティショニング列と比較するパラメーターを取得し、パラメーターを直接比較することでクエリの条件と満たすパーティション境界を決定する新しいメカニズムを実装しています。 例えば、この場合、検索される値(2018-11-05)よりも大きい最小の範囲境界の値が、すべてのパーティション範囲の上限でソートされた配列上をバイナリ検索によって検索されます。
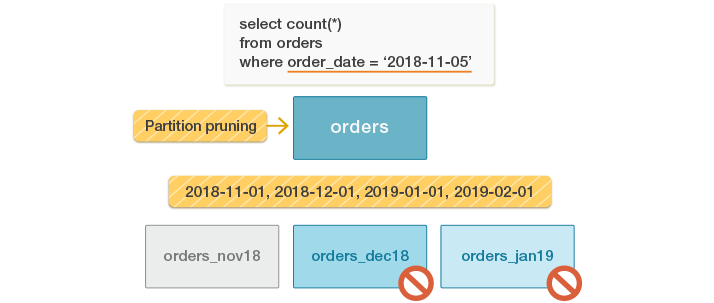
パーティション境界は効率的な内部表現(ソート済み配列)で格納されているため、これらの値の検索も非常に効率的です。特に、新しいアルゴリズムはバイナリ検索を使用するためO(log N)で、より多くのパーティション数にもスケールします。全体として、新しいメカニズムは古いメソッドに比べてオーバーヘッドが少ないので、この最適化の待ち時間が大幅に改善されます。
実行時パーティション・プルーニング
以前のPostgreSQLではプルーニングに利用するパラメーターがクエリテキストに直接書かれていない場合や、キャッシュされた実行計画を利用する際のように、クエリを再プランニングせずに値がエグゼキュータに直接渡された場合では、パーティション・プルーニングが機能しません。例えば、prepared statementを利用した場合、アプリケーションは実際のパラメーターの値を最初に提供しない場合があります。この場合、プランナはパラメーターの値がわからないため、パーティション・プルーニングを実行できません。パラメーターの値がバインドフェーズにて最終的に提供されると、それらはエグゼキュータに直接渡されますが、古いPostgreSQLサーバーではその情報を使ってパーティション・プルーニングは実行できません。
PostgreSQL11では、プランナが、クエリを分析することでそのような未確定なパラメーターを認識し、エグゼキュータがパーティション・プルーニングを実行できるための情報を含む実行計画を作成することにより、エグゼキュータ自身がパーティション・プルーニングをできる新しい機能を実装しています。
以下に説明するように、実行時パラメーターは2つのタイプがあります。クエリは、タイプ1、タイプ2またはその両方のタイプを持つことができます。次の例は、実行時プルーニングが適用可能な場合を示しています。
CREATE TABLE foo (a int); INSERT INTO foo VALUES (2), (3); CREATE TABLE p (a int) PARTITION BY LIST (a); CREATE INDEX ON p (a); CREATE TABLE p1 PARTITION OF p FOR VALUES IN (1); CREATE TABLE p2 PARTITION OF p FOR VALUES IN (2); CREATE TABLE p3 PARTITION OF p FOR VALUES IN (3);
タイプ1 : 実行中に値が変わらないパラメーター
クエリがこのタイプのパラメーターを含む場合、プラン実行前にプルーニングが可能です。そして、プルーニングが成功した場合、「Subplans Removed:」がEXPLAINの出力に表示されます。
例:
PREPARE example_query AS SELECT * FROM p WHERE a = $1;
上記のクエリでは、$1はこのタイプのパラメーターです。まだ何もパラメーターに値が設定されていないことに注意してください。パラメーター値は、上記の名前がついたprepared statementに対するEXECUTEコマンドによって設定されます。
EXPLAIN (costs off, timing off, analyze) EXECUTE example_query (1);
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────
Append
Subplans Removed: 2
-> Bitmap Heap Scan on p1
Recheck Cond: (a = $1)
-> Bitmap Index Scan on p1_a_idx
Index Cond: (a = $1)
Planning Time: 0.019 ms
Execution Time: 0.163 ms
(8 rows)
パラメーター$1には1が設定され、この値はクエリの実行全体で変わりません。そのため、プルーニングはAppendノードの初期化時に行われます。パーティションp2とパーティションp3は1を含まないためこれらは除外され、上記の出力にはSubplan Removed: 2が表示されます。
動的プルーニングはプランナが汎用プラン(EXECUTEによって提供されたパラメーターを無視したプラン)を作成した時にのみ必要とされることに注意してください。現在汎用プランが生成させることを制御する方法はないため、動的パーティション・プルーニングを見るために、プランナが内部のコスト条件に応じで汎用プランに切り替えることを待つ必要があるかもしれません。
タイプ2 : 実行中に変化するパラメーター
もしクエリがこのタイプのパラメーターを持つ場合、クエリの実行中、プルーニングはパラメーター値が変わる度に実行されます。もしパーティションが常に除外された場合、そのサブプランには(never executed)がEXPLAINの出力に表示されます。
例:
SELECT * FROM foo f WHERE EXISTS (SELECT * FROM p WHERE a = f.a);
f.aはpをスキャンするパラメーターです。上記のクエリはテーブルfooとpを結合します。もしpが内部テーブルである場合、a = f.aと条件とした動的パーティション・プルーニングが利用できます。プルーニングはf.aのすべての値に対して実行されるため、テーブルfooのすべての行に対して実行されます。
EXPLAIN (costs off, timing off, analyze) SELECT * FORM foo f WHERE EXISTS
(SELECT * FROM p WHERE a = f.a);
QUERY PLAN
─────────────────────────────────────────────────────────────────────────
Nested Loop Semi Join (actual rows=0 loops=1)
-> Seq Scan on foo f (actual rows=2 loops=1)
-> Append (actual rows=0 loops=2)
-> Bitmap Heap Scan on p1 (never executed)
Recheck Cond: (a = f.a)
-> Bitmap Index Scan on p1_a_idx (never executed)
Index Cond: (a = f.a)
-> Bitmap Heap Scan on p2 (actual rows=0 loops=1)
Recheck Cond: (a = f.a)
-> Bitmap Index Scan on p2_a_idx (actual rows=0 loops=1)
Index Cond: (a = f.a)
-> Bitmap Heap Scan on p3 (actual rows=0 loops=1)
Recheck Cond: (a = f.a)
-> Bitmap Index Scan on p3_a_idx (actual rows=0 loops=1)
Index Cond: (a = f.a)
Planning Time: 3.293 ms
Execution Time: 0.397 ms
(17 rows)
テーブルfooは2と3のみを含むため、p1のサブプランは実行されていません。
タイプ1とタイプ2の両方を持つ場合
次の例のように、クエリに両方のタイプのパラメーターを含めることも出来ます。
PREPARE example_query AS SELECT * FROM foo f WHERE EXISTS (SELECT * FROM p WHERE a = f.a AND a <> $1);
上記のクエリはa = f.aとa <> $1の両方のタイプのパラメーターを持ちます。
EXPLAIN (costs off, timing off, analyze) EXECUTE example_query (2);
QUERY PLAN
─────────────────────────────────────────────────────────────────────────
Nested Loop Semi Join (actual rows=0 loops=1)
-> Seq Scan on foo f (actual rows=2 loops=1)
-> Append (actual rows=0 loops=2)
Subplans Removed: 1
-> Bitmap Heap Scan on p1 (never executed)
Recheck Cond: (a = f.a)
Filter: (a <> $1)
-> Bitmap Index Scan on p1_a_idx (never executed)
Index Cond: (a = f.a)
-> Bitmap Heap Scan on p3 (actual rows=0 loops=1)
Recheck Cond: (a = f.a)
Filter: (a <> $1)
-> Bitmap Index Scan on p3_a_idx (actual rows=0 loops=1)
Index Cond: (a = f.a)
Planning Time: 4.189 ms
Execution Time: 0.331 ms
(16 rows)
Subplans Removed:と(never executed)の両方があることに注意してください。
Subplans Removed:はパラメーター$1があるために表示されます。値2で実行すると、条件がa <> 2になるためパーティションp2のサブプランは除外されます。fooは2と3のみを含むことからf.aが1になることはないため、p1のサブプランが実行されることはなく、(never executed)が表示されます。そのため、パーティションp3のみがスキャンされます。
パーティション・ワイズ結合と集約
結合と集約は複雑なワークロードで広く使われており、その効率は、データセットが大きい時にパフォーマンスに大きな影響を及ぼす可能性があります。PostgreSQL11では、結合または集約される2つのテーブルがパーティション・テーブルである場合に効率的な実行計画を作成する2つの手法が実装されていますが、大規模データセットの一般的なスケーリング手法でなければなりません。
パーティション・ワイズ結合
2つのパーティション・テーブルが共通するパーティション・キーを用いて等価結合を行う場合、それら全体を結合するのではなく、同じデータセットを持つパーティションを結合することは理にかなっています。次の例を考えてみましょう。本記事で以前に利用したordersテーブルがorder_itemsテーブルを伴い、その両方がid列でハッシュ・パーティショニングされています。
CREATE TABLE orders (id int, order_date date) PARTITION BY HASH (id); CREATE TABLE orders_0 PARTITION OF orders FOR VALUES WITH (modulus 3, remainder 0); CREATE TABLE orders_1 PARTITION OF orders FOR VALUES WITH (modulus 3, remainder 1); CREATE TABLE orders_2 PARTITION OF orders FOR VALUES WITH (modulus 3, remainder 2); CREATE TABLE order_items (id int, content text) PARTITION BY HASH (id); CREATE TABLE order_items_0 PARTITION OF order_items FOR VALUES WITH (modulus 3, remainder 0); CREATE TABLE order_items_1 PARTITION OF order_items FOR VALUES WITH (modulus 3, remainder 1); CREATE TABLE order_items_2 PARTITION OF order_items FOR VALUES WITH (modulus 3, remainder 2); SELECT count(*) FROM orders INNER JOIN order_items ON orders.id = order_items.id;
上記のクエリでは、古いPostgreSQLではordersのパーティションとorder_itemsのパーティションをそれぞれ結合し、その後orders.id = order_items.idを使用して結合します。次のようになります。
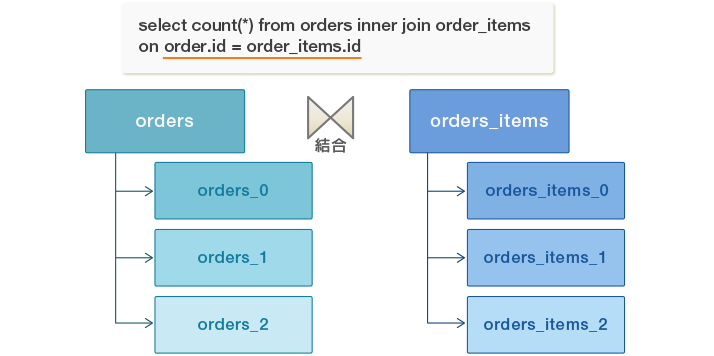
しかし、orders_0の行はorder_items_1とorder_itmes_2の行には一致しないことは明白です。そのため、orders_0はorder_items_0と、orders_1はorder_items_1と、そして、orders_2はorder_items_2と結合することは理にかなっています。次のようになります。
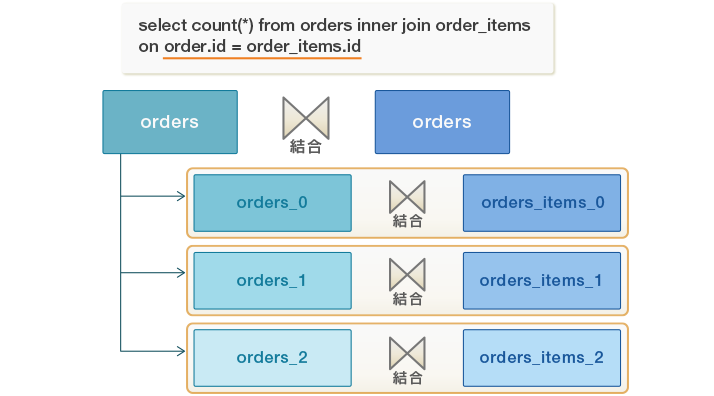
PostgreSQL11はこのような形式の実行計画をパーティション・ワイズ結合と呼ばれる機能を用いることで作成することが出来ます。このような実行計画を作成する主な利点は、プランナがパーティション・テーブル全体に対する結合よりも、それぞれのペアに対してより良い結合アルゴリズムを選択出来き(より小さいパーティションに対する統計情報は、テーブル全体の統計情報よりも正確です)、その結果、よりよい実行計画になります。主な制約の一つは、結合対象のパーティション・テーブルは正確に同じパーティション境界を持つ必要があることです。また、プランニングはO(N)時間かかり、現在の実装ではCPUやメモリーをパーティションのペア毎に消費します。このような非効率性により、パーティション・ワイズ結合はデフォルトで無効になっています。長い実行時間作成時間を許容し、よりよい実行計画のためのメモリーコストを支払うことができるユーザはneable_partitionwise_join GUCパラメーターを有効にすることができます。
パーティション・ワイズ集約
集約は小さな独立した単位に分割するのに役立つ操作です。例えば、パーティション・テーブルに対する集約は、それぞれのパーティション対する集約と、それらを必要に応じて集める、複数の集約手順に分割することができます。
SELECT count(*) FROM orders;
古いPostgreSQLは最初にorderテーブルのすべてのパーティションをスキャンし、その後にカウントを開始するため、以下のような実行計画になります。
EXPLAIN (costs off, verbose) SELECT count(*) FROM orders;
QUERY PLAN
─────────────────────────────────────────────
Aggregate
Output: count(*)
-> Append
-> Seq Scan on public.orders_0
-> Seq Scan on public.orders_dec18
-> Seq Scan on public.orders_jan19
(6 rows)
PostgreSQL11では以下のようになります。
EXPLAIN (costs off, verbose) SELECT count(*) FROM orders;
QUERY PLAN
───────────────────────────────────────────────────
Finalize Aggregate
Output: count(*)
-> Append
-> Partial Aggregate
Output: PARTIAL count(*)
-> Seq Scan on public.orders_0
-> Partial Aggregate
Output: PARTIAL count(*)
-> Seq Scan on public.orders_dec18
-> Partial Aggregate
Output: PARTIAL count(*)
-> Seq Scan on public.orders_jan19
(12 rows)
そのため、最初に各パーティションにて部分的なカウントを行い、すべてのパーティションへの処理が完了した後に最終的な処理を行います。
集約がグループ化され、グループ・キーがパーティション・キーに一致している場合、複数のパーティションに同じキーが存在しないため、各パーティションでの集約結果は特定のグループ・キーの最終的な出力になります。そのため、PostgreSQL11では次のような実行計画を生成出来ます。
EXPALIN (costs off, verbose) SELECT id, count(*) FROM orders GROUP BY id;
QUERY PLAN
─────────────────────────────────────────────
Append
-> HashAggregate
Output: orders_0.id, count(*)
Group Key: orders_0.id
-> Seq Scan on public.orders_0
Output: orders_0.id
-> HashAggregate
Output: orders_dec18.id, count(*)
Group Key: orders_dec18.id
-> Seq Scan on public.orders_dec18
Output: orders_dec18.id
-> HashAggregate
Output: orders_jan19.id, count(*)
Group Key: orders_jan19.id
-> Seq Scan on public.orders_jan19
Output: orders_jan19.id
(16 rows)
結合と同じように、プランナが各パーティションに対して集約を実行する主な利点は、集約で使用するアルゴリズムに関してより良い決定ができるということです。たとえば、ソートベースの集約よりもハッシュベースの集約を優先することができます。これは、前者はより安価ですが、入力サイズが小さい場合にのみ考慮されるためです。
欠点は、パーティション単位の結合手法と同じです。つまり、計画ではパーティション数がO(N)回で、過剰なCPUとメモリーを消費する可能性があります。 したがって、デフォルトでは無効になっています。 より良い計画のためにそれを許容したいユーザは、enable_partitionwise_aggregate GUCパラメーターを使用して有効にすることができます。
まとめ
PostgreSQL11は、パーティションのメタデータに基づく最適化手法を実装することによって、パーティション・テーブルに対するクエリ実行の効率を向上させる方向で重要な一歩を踏み出しました。これらの手法がパーティション数の点でスケーラブルであることを保証するためには、今後より多くの作業を行う必要がありますが、これは良いスタートのように思えます。
(Amit Langote(著)、澤田 雅彦(翻訳))
Tweet