















ビッグデータ分析の意義と、分析のためのシステム基盤

ソリューション事業部 副事業部長
田中 一男
ビッグデータによってビジネスも市場も社会も、そのあり方が一変すると言われております。そのような変革の中、企業にとっては新しい価値を創出するためのデータ分析力こそが競争優位の源泉となります。ビッグデータ分析の意義と、分析力を実現するためのシステム基盤について解説します。
Tweet
ビッグデータとマネーボール
たった今、われわれ人類はビッグデータという大きなトレンドの渦の中にいます。ビッグデータという情報革命が我々の生き方、働き方、そして、考え方を変革していくと言われています。このようにビッグデータというトレンドは、ITの単なる一分野というような技術的な観点では正しくとらえることができません。むしろ、ビジネスに直結しています。
最近では、「その数字が戦略を決める」や「統計学が最高の学問である」などのデータ分析に関するビジネス書が注目を浴び、「マネーボール」にいたってはブラッド・ピット主演の映画にまでなっています。そういう意味ではマネーボールはデータ分析の最も有名な具体例と言えるかもしれません。マネーボールというのは、メジャーリーグベースボールの世界においてオークランド・アスレチックスが採用した、データ分析を活用して少ない投資で勝率の高いチーム作りをする戦略のことを指しています。2002年当時で選手の年俸総額が、1位のニューヨーク・ヤンキースの1/3程度だったにもかかわらず、全球団で最高の勝率を記録したことでこの戦略の有効性が実証されました。
それ以外の戦略としては、選手の才能に頼って一発長打攻勢で大量得点をあげる「ビッグボール」や、ベンチの采配により小技や足技を仕掛ける機動力野球の「スモールボール」があります。マネーボールにおいては、選手の類稀なる才能や監督の優れた采配に頼るのではなく、ベースボールというゲームで勝利するためにフロントがどのようにデータを分析し、その分析結果をどのように活用して無駄な要素を極力省いて低予算でチームを強くしていくかが語られています。また、この言葉は現在では一般化され、「moneyballing: データ分析による意思決定」という意味で使われています。
マネーボールの別の例を見てみましょう。2002年に会計事務所に勤務中にメジャーリーグ野球選手の統計的評価システムを開発していたNate Silverが、New York Timesの選挙予測専門家に転身し、2008年のオバマ対マケインの大統領選で50州中49州の勝敗を的中、2012年のオバマ対ロムニーの大統領選の勝敗を全50州で的中させて注目されています。一方、永年の勘や経験に頼った政治専門家たちの予想はほとんどが外れました。
新しい価値の創出こそがビッグデータ分析の目的
現代のような熾烈な競争社会においてビジネスを営む企業においては、環境の変化への俊敏な対応、コストの削減、コンプライアンスへの対応、さらに、顧客の好みや価値観の多様化への対応などが求められています。また、新たな成長に向けて内部で新規ビジネスを立ち上げるにあたってはリーンなスタートアップが要求されます。
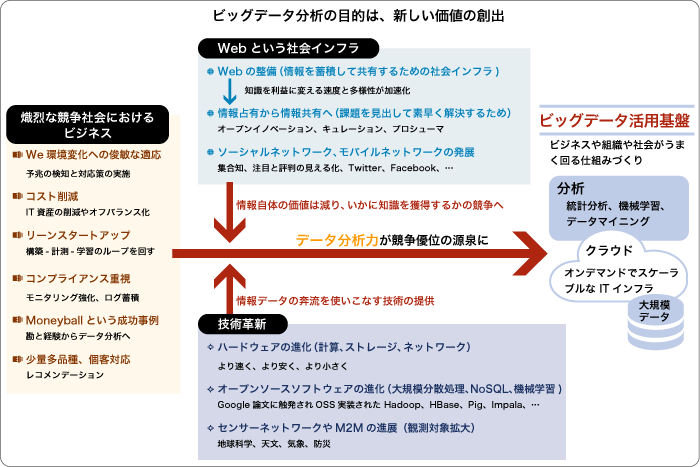
一方、我々の社会における変革として、Webという社会インフラは無視できません。情報を蓄積して共有するための社会インフラとしてのWebが整備され、知識を利益に変える速度と多様性が加速化されたことにより、情報が一部の人たちによって占有されていた状態から、情報をみんなで共有する世界に転換し始めました。その中でオープンイノベーションが叫ばれ、あるいはキュレーションの必要性が高まってきています。キュレーションというのは、何らかの観点によって情報を収集し、選別してまとめ上げ、意味付けを与えて、共有することです。情報を発信するのは簡単になりましたが、それを聞き入れてもらうことはますます難しくなってきています。情報があふれているからこそ、そこから重要なものを嗅ぎ分ける能力が一層重要になってきています。さらに、ソーシャルネットワークやモバイルネットワークがソーシャルデータの大量発信を加速させています。すなわち、ビッグデータの世界では情報自体がもつ価値は以前に比べると減ってしまい、そこからいかに知識を獲得するかについての競争になってきています。
このような社会的な変革に対して、技術革新、特にITの技術革新はどうなっているでしょうか。ITの世界ではハードウェアの進化が目覚ましく、サーバーもストレージもネットワークも、より速く、より安く、より小さくという方向に進化しました。また、Googleが発表した数々の論文に触発されて、そのオープンソースソフトウェアによる実装が盛んになり、HadoopやHBase、Pig、Hive、Impalaなど、大規模な分散処理プラットフォームから、NoSQL、あるいは、機械学習ライブラリなどが開発され、盛んに活用されています。さらには、センサーネットワークやモノのインターネット(Internet of Things)の進展により、様々なモノからの情報がネットワークを通じてやり取りされることによってますます観測対象が拡がり、地球科学、天文学、気象、防災などの用途の分析に使われていきます。そこでこれらのデータの奔流を使いこなす技術がますます必要となってきます。
そのような変革の中で企業にとっては、新しい価値を創出するためのデータ分析力こそが競争優位の源泉となります。その分析力を獲得し、磨き上げるためには、ビジネスや組織や社会がうまく回る仕組みをつくり上げるためのビッグデータの活用基盤というものが必要です。それには、大量のデータを蓄積する大規模データウェアハウス、オンデマンドでスケーラブルなITインフラであるクラウド、そして、それらの基盤の上で分析を行うための統計分析や機械学習やデータマイニングの技術が必要になるのです。
2つのタイプのビッグデータ分析アーキテクチャ
企業はビッグデータ以前の世界において、たとえば表の形式に構造化されたデータをリレーショナル・データベースに蓄積し、その構造化データを使ってビジネスを判断してきました。しかし、テキスト・音声・音・画像・動画などの、前もって定義されたデータモデルをもたない非構造化データや、XMLやEDIなどのようにリレーショナル・データベースのデータモデルとは異なった形式の半構造化データという、今までは捨てられたり、うまく活用されてこなかったデータが、ストレージや計算パワーのコスト削減によって蓄積したり処理したり分析することができるようになりました。また、非構造化や半構造化データの処理に向いた、Hadoopなどの新しいスケーラブルな分散処理方式がオープンソースソフトウェアとして開発されたことによって、この動きに拍車がかかりました。
Webのログ、ソーシャルメディアデータ、メール、センサーデータ、写真、ビデオなどの、手垢のついていない非構造化データや半構造化データという潜在的な宝の山を前にして、多くの企業が従来から取り扱ってきた構造化されたビジネスデータと一緒に分析することによって新しい価値を創造しようとしています。
データを加工して蓄積するのか、あるいはデータは生のまま蓄積しておくのかという違いによって、ビッグデータを分析するための基盤アーキテクチャには大きく2つのタイプに分けることができます。従来からのDWH/BIの流れを汲むものとHadoopを中心にしたものです。データウェアハウス(DWH)中心のアーキテクチャでは、業務データベースからのデータはETLツールによって変換され、DWHに蓄積されます。また、時系列データはCEPエンジンなどにより、そのまま処理されて活用されることもありますが、CEPエンジンによって収集されたデータをDWHに蓄積することもあります。そして、非構造化および半構造化データに対してはHadoopをETLツールのように使って、生のデータから意味付けすることにより構造化してから、DWHに蓄積します。こうすると、すべてのタイプのデータはDWHの中に構造化されて蓄積されるため、OLAPやデータマイニングやテキストマイニングなど従来のBIツール群を使って、データアナリストによる従来通りの分析が可能になります。
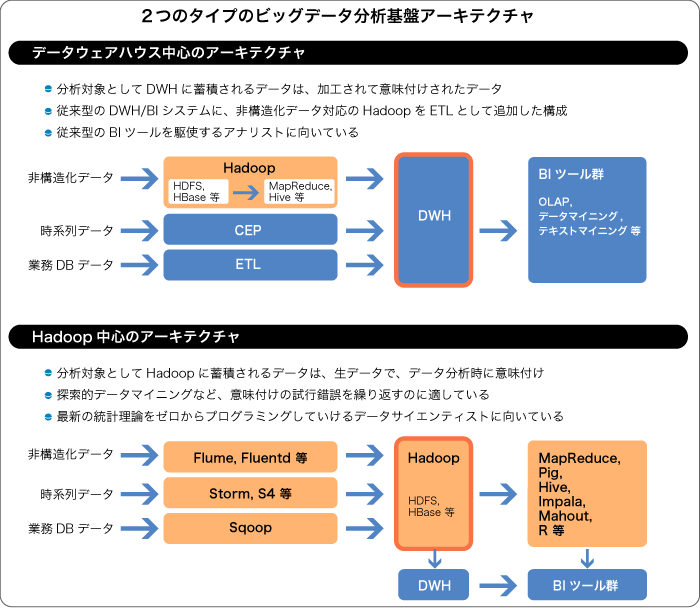
一方、Hadoop中心のアーキテクチャでは、業務データベースからのデータはSqoopなどを使って、時系列データはStormやS4などを使って、非構造化データはFlumeやfluentdなどを使って、HDFS(Hadoop分散ファイルシステム)やHBaseなどに、前もって意味付けせずに生のまま蓄積できます。使っているソフトウェアはすべてオープンソースですので経済的なアーキテクチャと言えます。この方式の最大の特長は、生のままのデータが蓄積されているので、データ分析時にいろいろな意味付けを試してみる探索的なデータマイニングができるところにあります。また、従来のBIツールで用意されているアルゴリズムだけではなく、最新の統計理論をベースにゼロからプログラミングできる自由度をもっています。そのため、データアナリストというよりデータサイエンティストに向いたアーキテクチャと言えます。また、必要ならば、HDFSやHBaseから何らかの意味付けをした後のデータをDWHにロードすることによって、従来タイプのBIツール群も使うこともできます。
以上のように大きく見ると2つのアーキテクチャがありますが、実際にはこれらを組み合わせたアーキテクチャをとる場合があります。
ビッグデータ分析基盤構築をトータルにサポート
当社では、ベンダー製品とオープンソースソフトウェアそれぞれのシステム基盤に精通した技術者と、それぞれのアーキテクチャ上での分析手法に精通したデータアナリストとデータサイエンティストによって、お客さまのビッグデータ活用に最適なビッグデータ分析基盤を提案し、構築できる体制を整えています。ベンダー製品ではOracle社のDBサーバー専用マシン Oracle Exadata Database Machine、同社のBIサーバー専用マシン Oracle Exalytics In-Memory Machineや、IBM社のデータ・アプライアンスIBM PureData System for Analytics (Netezza) など、オープンソースソフトウェアではHadoopなどに関して、お客さまの最適なシステム選定を支援するPoC (Proof of Concept: 導入前の実機検証)のためのラボ施設を開設しています。
ビッグデータを保有されているお客さま、あるいはビッグデータの活用アイデアをお持ちのお客さまにおいては、分析基盤に対する要求もさまざまです。たとえば、マシンから吐き出されるログを検索したり分析するには、前述のDWHアプライアンスやHadoop基盤を使わなくとも、Splunkというソフトウェアで充分な場合もあります。また、ビッグデータの保管に関しては、スケーラブルな分散ストレージが必要でしょう。その場合には、圧倒的な信頼性をもつ秘密分散方式のCleversafeというベンダー製品や、オープンソースソフトウェアのOpenStack Swiftがあります。また、データストア間をつなぐETLツールにおいてもオープンソースソフトウェアのTalendというものがあり、経済的にシステム基盤を構築できます。以上のように、当社は、お客さまにとって最適なビッグデータ分析基盤の提案と構築で必ずお役に立てると自負しています。
Tweet