
















SRv6をもう少し深堀してみよう。
2021.04.27
はじめに
前回のコラムでは、「セグメントルーティング(Segment routing)」の基本的な概要について説明しました。今回のコラムでは、IPv6ネットワークの上で構成されるSRv6(Segment Routing IPv6)について、少し詳しく内容を解説します。
今回は、SRv6サービスを実現するパケットヘッダーについて、詳しく観察してみます。ここでは、簡単のため、Ubuntu上にNetwork Namespaceを用いてモデルネットワークを構成し、SRv6処理を行うノードにおいて、ネットワーク処理スタックにおけるさまざまなNetfilter hookポイントで、Python Scapyパッケージを用いて、疎通するパケットを取得、そのヘッダーについて、観察します。また、参考として、MPLS IPv6トンネルとの比較もします。
次に、SRv6を用いてVPNを構成するために必要な設定を実行するためのControl Planeについて、簡単に触れます。VPNのようなアプリケーションでは、IPv6アンダーレイネットワークの両端で、VPNユーザーのLAN Segmentに設置する、SRv6のSRv6トンネルの始点(Head End)、終点(Tail End)としてENCAP/DECAP処理を行うルーター機器(CPE(Customer Premises Equipment))を用いて、SRv6トンネルの設定に必要な通信先CPEのインターフェースアドレスやCPE配下のLAN SegmentのPREFIX情報を必要とします。これらの情報交換方法について、簡単に述べます。
SRv6とは?
前回のコラムで説明したとり、SRv6とは、IPv6の拡張ヘッダーを利用したセグメントルーティングです。送信先で作成した、経由するノード、パケット処理を定義した識別子(SID)(IPv6アドレス形式)を順番に、SRH(Segment Routing Extension Header)に格納します。Outer IPv6ヘッダーのDestination IPアドレスには、SRHで定義された、次に経由するノード、または、パケット処理を定義したアドレスが設定されます。ノードを経由するごとに、これは、順次変更されていきます。つまり、SRHに定義されたアドレスの中からOuter IPv6ヘッダーのDestination IPアドレスに相当する、SRv6機能が有効化されたインターフェースにパケットが到着すると、そこで定義された処理が実行され、SRHにおいて、その次に定義されたアドレスを、Outer IPv6ヘッダーのDestination IP アドレスとして設定し、パケットがフォワーディングされます。この処理を繰り返し、SRHで定義されたアドレスとそこで行われる処理が実行されたあと、最終的なオリジナルの着側ノードにパケットがフォワーディングされるものです。そのため、ネットワークリソースを有効に利用することを目的に、送信元で、経由するノード、処理に関するルーティングポリシーを適切に作成することで、より柔軟なルーティングを可能にします。
SRv6のパケットをのぞいてみると...
ここでは、図1に示すような説明用のネットワークモデルを構成します。簡単に検証できる環境として、ここでは、Linux(Ubuntu)上にNetwork Namespaceを用いて構成しました。図1にあるように、CPE間では、SRv6トンネルが設定されています。ここでは、さっそく、図中のhost4からhost1に向けて、Ping処理を行い、Namespaceで構築されたノードにおいて、パケットを取得、パケットヘッダーを観察します。
■ Pingの実行
hiroshi@hiroshi-VBox:~$ sudo ip netns exec host4 ping6 -c 1 1::1
PING 1::1(1::1) 56 data bytes
64 bytes from 1::1: icmp_seq=1 ttl=63 time=13.6 ms
--- 1::1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 13.624/13.624/13.624/0.000 ms
host4から送信されたICMPv6 Echo Requestパケットは、host1に到着、処理して、host1からhost4に向けて、ICMPv6 Echo Replyパケットが送信されています。CPE1において、このパケットを取得し、観察します。
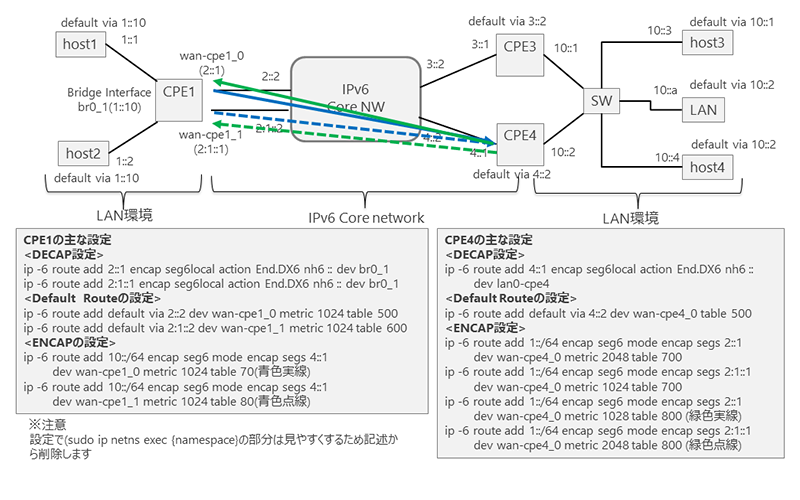
図1. Network namespaceで構成された説明用ネットワークモデル
図1のネットワークモデルは、アンダーレイネットワークとなるIPv6が動作するIPv6 Core Networkの両端に位置するLAN SegmentをSRv6トンネルで結ぶことで、VPNを構成したモデルです。両端のLAN Segment間を接続するために、Core Networkの両端では、SRv6機能を有するルーター端末(CPE)を設置します。
左側のLAN Segment (1::/64) は、1つのCPE(CPE1)で、SRv6のENCAP/DECAP処理を行います。Core Networkに対して、CPE1は、2つのインターフェースで接続をすることで、信頼性を向上させるとともに、設定したルーティングポリシーに従い、トラフィックフローが疎通するインターフェースを使い分けることを想定しています。
一方、右側のLAN Segment (10::/64)は、SRv6のENCAP/DECAP処理をおこなう2台のCPE (CPE3, CPE4)を用意しています。LAN Segmentから利用するCPEを選択することができます。また、2台のCPEでは、CPE1の2つのインターフェースに向けたSRv6トンネルを2つ用意し、ルーティングポリシーに基づき、使用するSRv6トンネルを選択することができる設定を入れています。説明用のネットワークモデルにおける具体的なルーティングポリシーの設定の詳細は、ここでは説明を省略します。機会があれば、次回のコラムで説明します。
パケットの取得は、以下の要領で行います。
CPE1内部の以下の2つのnetfilter hook ポイント[1]、NF_IF_PRE_ROUTING (Prerouting Chain) とNP_IP_FORWARD(Forward Chain)において、パケットを取得、ヘッダー内容を観察します。CPE1では、nftablesサービスを動作させます。inet mangle テーブルには、Prerouting ChainとForward Chainにルールを設定します。図2のように、上記2つのnetfilter hookポイントに、netfilter-Queue[2]を設定し、CPE1のネットワーク処理スタックの中で、取得したパケットのヘッダー内容を観察します。nftablesで設定された具体的なルールは下記のようになります。★印部分が、netfilter-Queueの設定になります。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec CPE1 nft list table inet mangle
table inet mangle {
chain prerouting {
type filter hook prerouting priority mangle; policy accept;
iifname "br0_1" counter packets 11 bytes 872 meta mark set ct mark
ip6 saddr 4::1 iifname "wan-cpe1_0" counter packets 3 bytes 504 meta mark set 0x0000000a
ip6 saddr 3::1 iifname "wan-cpe1_0" counter packets 0 bytes 0 meta mark set 0x0000000a
meta mark 0x0000000a counter packets 9 bytes 1128 ct mark set meta mark
ip6 saddr 4::1 iifname "wan-cpe1_1" counter packets 0 bytes 0 meta mark set 0x00000014
ip6 saddr 3::1 iifname "wan-cpe1_1" counter packets 0 bytes 0 meta mark set 0x00000014
meta mark 0x00000014 counter packets 0 bytes 0 ct mark set meta mark
ip6 saddr 1::/64 counter packets 7 bytes 600 queue num 1 (★Netfilter-Queue(1))
}
chain input {
type filter hook input priority mangle; policy accept;
}
chain forward {
type filter hook forward priority mangle; policy accept;
ip6 daddr 4::/64 counter packets 3 bytes 504 queue num 1 (★Netfilter-Queue(2))
}
chain output {
type filter hook output priority mangle; policy accept;
}
chain postrouting {
type filter hook postrouting priority mangle; policy accept;
}
}
Prerouting Chainのnetfilter hookポイントでは、netfilter-Queueにパケットを挿入(Enqueue)するための条件として、「CPE1のネットワーク処理スタックに入ったパケットのうち、Source Addressが、1::/64に所属するものをQueueに導く」設定をしています。このため、host4からhost1に対してPingを行った場合、図1のhost1からhost4に向けて疎通するIPv6 Echo Replyパケットが取得されます。Prerouting Chainで取得されるパケットは、CPE1のネットワーク処理スタックに入ったパケットが、CPE1で設定されたルーティング判断処理が実行される前段階におけるパケットになります。(★netfilter-Queue(1))
また、CPE1では、図2で示すようにForward Chainのnetfilter hookポイントで設定されたnetfilter-Queueにパケットを挿入(Enqueue)するための条件として、「CPE1のネットワーク処理スタックに入り、ルーティング判断が実行され、転送されるパケットのうち、Destination Addressが、4::/64に所属するものをQueueに導く」設定をしています。(★Netfilter-Queue(2))
CPE1では、CPE4のWANアドレス(4::1)に向けてSRv6トンネルを設定し、パケットが疎通できるように、ENCAPを行う設定をしています。そのため、ルーティング処理判断後のパケットは、Forward Chainにおいて、Outer IPv6 ヘッダーのDestination Addressが4::1となるため、netfilter-Queueに挿入される条件を満たします。従って、ENCAP処理されたSRv6パケットが取得できます。
Prerouting Chainで取得されたパケットのヘッダースタックは、LAN Segmentから送信されたICMPv6 Echo ReplyパケットにIPv6のヘッダーがついたオリジナルのパケットのヘッダースタックとなります。一方、CPE1の各インターフェースでは、システム制御コマンドで、seg6_enabled = 1, ipv6.forwarding = 1と、それぞれ、SRv6処理とIPv6パケット転送処理を有効化しています。また、CPE1では、ENCAP設定を行うルーティングエントリーがルーティングテーブルに設定されています。そのため、ルーティング判断処理を経て、Forward Chainで取得したパケットには、Prerouting Chainで取得したオリジナルパケットのヘッダースタックの上に、新たに、SRH( IPv6 Option Header Segment Routing)とこれらを合わせた全体のOuter IPv6 ヘッダーが追加されたヘッダースタックになります。
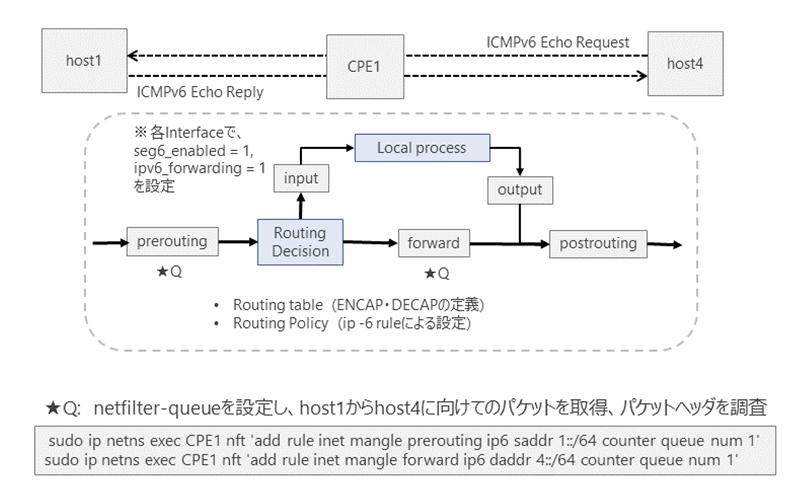
図2. Netfilter hookポイントとNetfilter-Queueの設定地点
では、モデルネットワークで取得したパケットの内容を観察してみます。
Prerouting ChainとForward Chainの2つのnetfilter hookポイントで用意したnetfilter-Queueから、パケットを取り出し、ヘッダーの中身を確認するPython Program(※ここでは、詳細は省略します) を作成し、パケットヘッダーの内容を観察します。ここでは、Python のScapyパッケージ[3]を利用して、パケットヘッダー情報の内容を表示します。Scapyを使って、netfilter-Queueで取得したパケットのパケットヘッダーを操作し、パケットのPayloadをコピーし、Destination Addressなどを変更して、その先へ代行転送することも可能となります。
まず、Prerouting Chainで設定したnetfilter-Queueで取得したパケットについて、その内容を見てみましょう。ネットワーク処理スタックで、ルーティング判断処理が実行される前の状態のパケットになります。以下のように、IPv6パケットのヘッダーの下に、ICMPv6 Echo Replyパケットが格納されています。ここでは、もっとも外側にあるIPv6 ヘッダーのSource Address, Destination Addressは、SRv6トンネルの両端の、VPNを構成するLAN Segmentのアドレスに所属する、Pingコマンドを行ったホストの具体的なアドレスになっていることが確認されます。
なお、以下のScapyの出力形式についてです。出力データの中の###[パケットヘッダー名]###で、各パケットヘッダーを区別しています。
hiroshi@hiroshi-VBox:~/column$ sudo ip netns exec CPE1 python3 check_packet_mark_x.py
ICMP packet, 104 bytes
###[ IPv6 ]###
version = 6
tc = 0
fl = 106558
plen = 64
nh = ICMPv6 # Next HeaderはICMPv6を示す
hlim = 64
src = 1::1 # VPNのCPE1配下のLAN SegmentのPrefixに所属するアドレス(host1)
dst = 10::4 # VPNのCPE3,4配下のLAN SegmentのPrefixに所属するアドレス(host4)
###[ ICMPv6 Echo Reply ]###
type = Echo Reply # host1からhost4へ向けたEcho ReplyのTypeであることを示す
code = 0
cksum = 0x6337
id = 0x74fa # ICMP PacketのID番号
seq = 0x1 # ICMPのシーケンス番号
data = (省略)
次に、Forward Chainで設定したnetfilter-Queueで取得したパケットを観察します。Forward Chainのnetfilter hookポイントで取得したパケットは、図2にあるように、ルーティング判断処理が実行された後のパケットになります。先に述べたように、CPE1では、Core Network上に設定したSRv6トンネルの端点であるCPE4のWAN側インターフェースに向けて、ENCAP処理を行う設定をしたルーティングエントリーが設定されています。従って、Prerouting Chainで取得したパケットの上に、さらにSRv6処理に付随するヘッダーが付加され、以下のようなヘッダー構成となっています。
IGMP packet, 168 bytes
###[ IPv6 ]###
version = 6
tc = 0
fl = 106558
plen = 128
nh = Routing Header # Next HeaderはSRv6用のOption Headerであることを示す
hlim = 63
src = 2::1 # CPE1のENCAP設定におけるdevパラメーターのインターフェースのアドレス
dst = 4::1 # ENCAP設定で定義したSegment(CPE4のWAN側インターフェース)のアドレス
###[ IPv6 Option Header Segment Routing ]###
nh = IPv6 # Next HeaderはENCAP前のオリジナルパケットのHeaderを示す
len = 2
type = 4
segleft = 0
lastentry = 0
unused1 = 0
protected = 0
oam = 0
alert = 0
hmac = 0
unused2 = 0
tag = 0
addresses = [ 4::1 ] # ENCAP設定で定義した、経由するSegment ID List
\tlv_objects\
###[ IPv6 ]###
version = 6
tc = 0
fl = 106558
plen = 64
nh = ICMPv6 # Next HeaderはICMPv6を示す
hlim = 64
src = 1::1 # VPNのCPE1配下のLAN SegmentのPrefixに所属するアドレス(host1)
dst = 10::4 # VPNのCPE3,4配下のLAN SegmentのPrefixに所属するアドレス(host4)
###[ ICMPv6 Echo Reply ]###
type = Echo Reply
code = 0
cksum = 0x6337
id = 0x74fa # ICMP PacketのID番号
seq = 0x1 # ICMPのシーケンス番号
data = (省略)
以上、説明用ネットワークモデルにおけるSRv6を利用した場合のフォワーディングプレーンに関して、パケットヘッダーについて観察してみました。
SRv6のEnd Pointの処理(ENCAP/DECAP)
上記のSRv6パケットの観察において述べたように、ネットワーク処理スタックにおいて、Prerouting Chainで取得したパケットとルーティング判断処理のあとのForward Chainで取得したパケットでは、ヘッダー構成が変わっていました。これは、CPE1において、各インターフェースでSeg6_enabed =1として、SRv6の処理を有効化し、SRv6のEnd Point Function処理を定義したルーティングエントリー(ENCAP/DECAP設定)に従い、SRv6の処理が実行され、その結果が反映されたためです。
[4]では、SRv6のEnd Point FunctionのListとその開発状況が整理されています(※この情報は古いです。例えば、End.DT4については、[5]にあるように、Linux Kernel Version 5.11で実現される予定です。)リストに掲載されたEnd Point Functionの仕様は、[6]のDraft資料に明記されていますので、これを参考願います。
今回の説明用モデルネットワークにおいて利用しているEnd Point Functionは、基本的なENCAP設定処理を行う(encap segs)とDECAP設定処理(End.DX6)を行う2つです。CPE1で定義された具体的な一例を下記に記します。
(a) ip netns exec CPE1 ip -6 route add 10::/64 encap seg6 mode encap segs 4::1 dev wan-cpe1_0 metric 1024 table 70
(b) ip netns exec CPE1 ip -6 route add 2::1 encap seg6local action End.DX6 nh6 :: dev br0_1
上記(a)の設定内容は、Prefix 10::/64へ行くための、CPE1のwan-cpe1_0のインターフェース (2::1) から(SRv6トンネルの始点)、CPE4の4::1のアドレス(Segment)(SRv6トンネルの終点)までのSRv6トンネル、を作成することを意味しています。加えて、Metric値を1024とし、このルーティングエントリーを、番号70のルーティングテーブルに設定する、ことを意味します。このように、ルーティングポリシールールとして、さまざまな条件に応じて、Lookupするルーティングテーブルを指定することができます。パケットは、Prerouting Chainを過ぎた後、ネットワーク処理スタックで、ルーティング処理され、転送されます。この時、(a)で設定されたENCAP処理が実行され、その結果、Forward Chainのnetfilter hookポイントで計測されたパケットのように、SRv6に関係するSRH(IPv6 Option Header Segment Routing)などがパケットヘッダーに追加されます。
上記(b)の設定では、Outer IPv6 ヘッダーのDestination Addressが2::1であれば、Outer IPv6 ヘッダーとその下にあるIPv6 Option Header Segment Routingヘッダーを取りさり、VPNとしてLAN間で疎通するオリジナルのパケット(先の観測事例であれば、[IPv6][ICMP]で構成されるパケット)を取り出し、devパラメーターで指定されたインターフェース(br0_1)へ転送します。End.DX6の場合、nh6で定義するnext hopとして、::(Default Route)を指定します。
以下、本章で関連する参考事項を2つ記載します。
参考1 ScapyのSRv6関連Headerについて
説明用のモデルネットワークでは、netfilter-Queueを用いて取得したパケットヘッダー内容の確認、パケットヘッダーフィールド情報の操作をPython Scapyパッケージを用いて操作しました。SRv6に関係するScapyパッケージで用意されているヘッダー定義などについて、参考のために下記に記します。
hiroshi@hiroshi-VBox:~/column$ python3
Python 3.8.6 (default, Sep 25 2020, 09:36:53)
[GCC 10.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from scapy.all import *
>>> ls()
(snip) # IPv6, Scapyに関係するものは下記になります。
IPv6 : IPv6
IPv6ExtHdrDestOpt : IPv6 Extension Header - Destination Options Header
IPv6ExtHdrFragment : IPv6 Extension Header - Fragmentation header
IPv6ExtHdrHopByHop : IPv6 Extension Header - Hop-by-Hop Options Header
IPv6ExtHdrRouting : IPv6 Option Header Routing
IPv6ExtHdrSegmentRouting : IPv6 Option Header Segment Routing
IPv6ExtHdrSegmentRoutingTLV : IPv6 Option Header Segment Routing - Generic TLV
IPv6ExtHdrSegmentRoutingTLVEgressNode : IPv6 Option Header Segment Routing - Egress Node TLV
IPv6ExtHdrSegmentRoutingTLVIngressNode : IPv6 Option Header Segment Routing - Ingress Node TLV
IPv6ExtHdrSegmentRoutingTLVPadding : IPv6 Option Header Segment Routing - Padding TLV
(snip)
今回ヘッダーの内容を観察するにあたり利用した、「IPv6 Option Header Segment Routing」の詳細なフィールド情報は、以下になります。
>>> ls(IPv6ExtHdrSegmentRouting)
nh : ByteEnumField = (59)
len : ByteField = (None)
type : ByteField = (4)
segleft : ByteField = (None)
lastentry : ByteField = (None)
unused1 : BitField (1 bit) = (0)
protected : BitField (1 bit) = (0)
oam : BitField (1 bit) = (0)
alert : BitField (1 bit) = (0)
hmac : BitField (1 bit) = (0)
unused2 : BitField (3 bits) = (0)
tag : ShortField = (0)
addresses : IP6ListField = (['::1']) # ここに疎通するSegmentのアドレスが入る
tlv_objects : PacketListField = ([])
パケットスタックの中のヘッダーフィールド情報の取得は、以下に示す2つの例のように取得します。
>>> packet[0][IPv6ExtHdrSegmentRouting][IPv6].src
'10::4' → ENCAPされたオリジナルIPv6パケットのSource Address
>>> packet[0][IPv6ExtHdrSegmentRouting].addresses
['2:1::1'] → ENCAPされたSegment ListをSRv6ヘッダーから取得。List形式になっている。
参考2 Linux上のMPLS機能を用いたMPLS IP tunnelを用いたVPNとの比較
これまで、IPv6が動作するCore Networkの両端に、CPEとして、Linux(ubuntu)上でSRv6機能が動作するルーター機器を接続し、SRv6トンネルによってLAN Segment間を接続するVPNサービスについて、説明用のネットワークモデルを使いながら、SRv6について説明してきました。
MPLSが動作するCore Networkでも、サービスプロバイダーが提供するCore NetworkのL3VPNサービスがあり、同じようにCore Networkの両端にあるPE(Provider Edge) ルーターに、CE(Customer Edge)ルーターを接続して、Core Networkの両端にあるLAN Segmentを接続することができます。この場合、利用者は、MPLS Providerに対してPEにCEを接続、適切な設定を申し込みます。Provider側は、PE間にMPLS IP/IPv6 Tunnel を設定します。ユーザーのCEを接続するためにVRFを用意し、ユーザー側のCEとの間で、適切な設定を行います。ユーザー(VRF)を識別するLabelとMPLS IP/IPv6トンネルを実現するLabelの2つのLabelをスタックすることで、VPNサービスが提供されます。
これまで、説明してきたSRv6が動作するCPEを用意して、このCPE間でトンネルを用いてVPNを構成する場合と異なり、MPLSL3VPNの場合は、PE間でトンネルを設定します。
Linuxでは、MPLSの動作(LabelのPush/Swap/Pop)ができるので[7]、ENCAP設定の比較のために、MPLS IP/IPv6トンネルの簡単な例も参考として、以下に記します。ここでは、説明のために、Network Namespaceを用いて、Core Networkの両端のLAN SegmentをMPLS IPv6トンネルを作成して接続する簡単なネットワークモデルをもちいて説明します。本来であれば、PE間でMP-BGPでVPNに関係するPREFIX交換や複数ユーザーを意識してVRFなどの設定が必要になりますが、ENCAP設定の比較ですから、これらの設定などは省略した簡単なモデルです。また、Core Network部分でもMPLSの設定を行う必要があるため、ここでは、簡素なCore Networkによる、図3に示すようなネットワークモデルで説明します。
説明用のMPLSネットワークとその設定
図3にNetwork Namespaceを用いた説明用のネットワークモデルを示します。4つのルーター(MPLS_R1,R2, R3, R4)で構成されたMPLSサービスを提供するCore Networkとなります。この両端のMPLSルータ(MPLS_R1, MPLS_R4)は、PEルーターとして機能し、トンネルの始点、終点となります。すなわち、ENCAP/DECAP設定処理を行います。MPLS_R1, R4の配下には、LAN Segment(10::/64と20::/64)が接続されています。MPLSルーター((MPLS_R2, MPLS_R3)は、ラベルの交換を行うPルーターの役割をします。
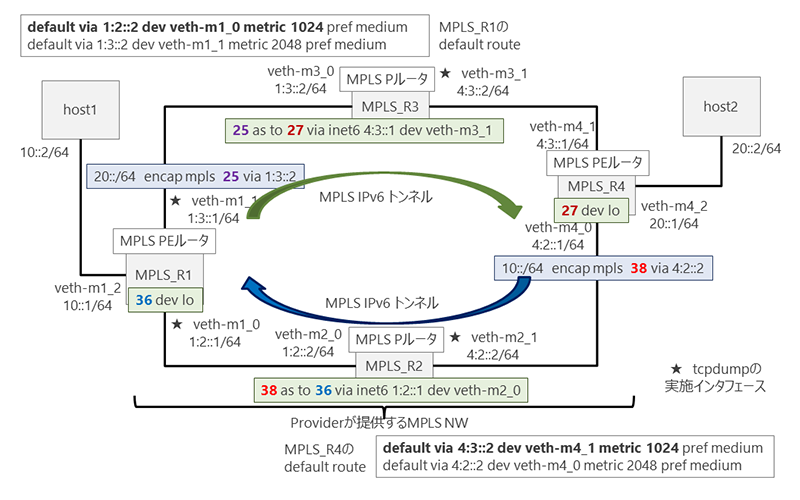
図3. 説明用MPLS IPv6トンネルを用いたネットワークモデル
NamespaceをMPLSルーターとして機能させるため、以下の設定を行います。まず、MPLS Router module[7]をLoadします。次に、使用可能なLabelの最大値を定義し(net.mpls.platform_labels=64)、Namespaceで定義した各ノードのインターフェースでMPLSが機能できるようにアクティベートします(net.mpls.conf.{Interface名}.input=1)。各インターフェースは、IPv6パケットもForwardできるように設定します(net.ipv6.conf.{all, default, インターフェース名}.forwarding=1)。
sudo modprobe mpls_router
sudo sysctl -w net.mpls.platform_labels=64
sudo ip netns exec MPLS_R1 sysctl -w net.mpls.platform_labels=64
sudo ip netns exec MPLS_R2 sysctl -w net.mpls.platform_labels=64
(snip)
sudo ip netns exec MPLS_R1 sysctl -w net.mpls.conf.veth-m1_1.input=1
sudo ip netns exec MPLS_R1 sysctl -w net.mpls.conf.lo.input=1
(snip)
アンダーレイネットワークをIPv6ネットワークとして動作するように設定した後、下記のように、MPLS_R1, R2, R3, R4について、MPLS IPv6 トンネルに必要な設定をおこない、下記のようなLFIB(Label Forwarding Information Base)を構築します。これらの設定に従った場合のMPLS IP トンネルとLabel交換のための設定を図3に図示しました。
なお、説明用モデルでは、IPv6のネットワークにおいて、MPLS_R1, R4では、Default routeを下記のように設定しています。MPLS_R1とMPLS_R4の間のIPv6のルーティングテーブルに従う疎通経路は、図3における反時計回り(R1→R2→R4→R3→R1)となりますが、下記で構築するMPLS IPv6トンネルの場合は、意図的に、図における時計回り(R1→R3→R4→R2→R1)となるように設定しています。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R1 ip -6 route show
(snip)
default via 1:2::2 dev veth-m1_0 metric 1024 pref medium 〇
default via 1:3::2 dev veth-m1_1 metric 2048 pref medium
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R4 ip -6 route show
(snip)
default via 4:3::2 dev veth-m4_1 metric 1024 pref medium 〇
default via 4:2::2 dev veth-m4_0 metric 2048 pref medium
LinuxのMPLS Moduleを用いたENCAP, DECAPの設定は、以下のようなコマンドで実現します。
・ENCAP設定は、以下の例のように設定します。
sudo ip netns exec MPLS_R1 ip -6 route add 20::/64 encap mpls 25 via 1:3::2
dev veth-m1_1
・DECAP設定は、以下の例のように設定します。
sudo ip netns exec MPLS_R1 ip -f mpls route add 36 dev lo
・MPLSにおいて、特徴的なSwapの設定は、以下の例のように設定します。
sudo ip netns exec MPLS_R2 ip -f mpls route add 38 as 36 via inet6 1:2::1 dev veth-m2_0
図3で設定したネットワークモデルのLFIB(Label Forwarding Information Base)、PEにおけるENCAP設定のルーティングエントリーを以下になります。
・MPLS_R1では、20::/64向けのパケットに対して、Label値25を設定し、インターフェースveth-m1_1からパケットを転送します。MPLS IPv6 トンネルのNext Hopは、1:3::2(MPLS_R3ルーター)になります。 SRv6でいえば、CPEで設定するENCAP設定のRouting Entryに相当します。ENCAP設定で定義される経由アドレスリストと同様な役割をはたすものがLabel値の25に相当します。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R1 ip -6 route show | grep mpls
20::/64 encap mpls 25 via 1:3::2 dev veth-m1_1 metric 1024 pref medium
・MPLS_R4では、10::/64向けのパケットに対して、Label値38を設定し、インターフェースveth-m4_0からパケットを転送します。MPLS IPv6 トンネルのNext Hopは、4:2::2(MPLS_R2ルータ)です。この設定が、SRv6でいえば、CPEで設定するENCAP設定のRouting Entryに相当します
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R4 ip -6 route show | grep mpls
10::/64 encap mpls 38 via 4:2::2 dev veth-m4_0 metric 1024 pref medium
・MPLS_R1では、Label値36が設定されたパケットは、LabelをPopして(DECAP)、IPv6パケットを取り出し、loに転送します。次に、ルーターに設定されたルーティングエントリーに従い、DECAPされたパケットをHostノードに転送します。SRv6でいえば、End.DX6のDECAP設定のRouting Entryに相当します。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R1 ip -f mpls route show
36 dev lo
・Core Network内のMPLS Pルーターとして機能するMPLS_R2は、Label値 37をもつパケットのLabelをLabel値36に交換(Swap)します。SRv6の場合、Core Network内のルーターでは、パケットのもっとも外側にあるOuter IPv6 ヘッダーに設定されたDestination Addressに対して、ルーティングテーブルをLookupし、最適な経路を見つけて、パケットを転送します。この処理動作に相当します。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R2 ip -f mpls route show
36 as to 36 via inet6 1:2::1 dev veth-m2_0
・Core Network内のMPLS Pルーターとして機能するMPLS_R3は、Label値 25をもつパケットのLabelをLabel値27に交換(Swap)します。SRv6の場合、Core Network内のルーターでは、パケットのもっとも外側にあるOuter IPv6 ヘッダーに設定されたDestination Addressに対して、ルーティングテーブルをLookupし、最適な経路を見つけて、パケットを転送します。この処理動作に相当します。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R3 ip -f mpls route show
25 as to 27 via inet6 4:3::1 dev veth-m3_1
・MPLS_R4では、Label値27が設定されたパケットは、LabelをPopして(DECAP)、IPv6パケットを取り出し、loに転送します。次に、ルーターに設定されたルーティングエントリーに従い、DECAPされたパケットをHostノードに転送します。SRv6でいえば、End.DX6のDECAP設定のRouting Entryに相当します。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R4 ip -f mpls route show
27 dev lo
LAN Segment間を疎通するパケットの観察
MPLS IPv6トンネルのパケットを観察するため、host1からhost2に向けて、パケットを送信します。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec host1 ping6 -c 2 20::2
PING 20::2(20::2) 56 data bytes
64 bytes from 20::2: icmp_seq=1 ttl=60 time=0.060 ms
64 bytes from 20::2: icmp_seq=2 ttl=60 time=0.154 ms
--- 20::2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.060/0.107/0.154/0.047 ms
ここでは、図3の★印で示したインターフェースにおいて、tcpdumpでパケットを取得します。
・MPLS_R1のveth-m1_1インターフェースでパケット計測します。host2に向けたICMPv6 Request Packetが、Label値25のMPLS shimヘッダーを設定され、MPLS_R3に転送されています。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R1 tcpdump -i veth-m1_1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth-m1_1, link-type EN10MB (Ethernet), capture size 262144 bytes
^C
10:18:08.772842 MPLS (label 25, exp 0, [S], ttl 63) IP6 10::2 > 20::2: ICMP6,
echo request, seq 1, length 64
10:18:09.773123 MPLS (label 25, exp 0, [S], ttl 63) IP6 10::2 > 20::2: ICMP6,
echo request, seq 2, length 64
・MPLS_R3のveth-m3_1インターフェースでパケット計測します。host2に向けたICMPv6 Request Packetが、MPLS_R3でSwapされ、Label値27のMPLS shimヘッダーを設定され、MPLS_R4に転送されています。
hiroshi@hiroshi-VBox:~$ sudo ip netns exec MPLS_R3 tcpdump -i veth-m3_1
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth-m3_1, link-type EN10MB (Ethernet), capture size 262144 bytes
^C
10:18:08.772849 MPLS (label 27, exp 0, [S], ttl 62) IP6 10::2 > 20::2: ICMP6,
echo request, seq 1, length 64
10:18:09.773147 MPLS (label 27, exp 0, [S], ttl 62) IP6 10::2 > 20::2: ICMP6,
echo request, seq 2, length 64
tcpdumpで計測したパケットを観察します。ここでは、MPLS_R1のveth-m1_1で取得したパケットをScapyで読みだして、ヘッダー内容を観察します。MPLSのShimヘッダーを解析するために、mplsのコントリビュートモデル(mpls)をLoadします。
hiroshi@hiroshi-VBox:~/mpls_linux$ python3
Python 3.8.6 (default, Sep 25 2020, 09:36:53)
[GCC 10.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from scapy.all import *
>>> load_contrib("mpls")
>>> pkt = rdpcap("encap_mpls0207.pcap")
>>> pkt[2].show()
###[ Ethernet ]###
dst = 16:cb:97:e6:47:24 # MPLS_R3のveth-m3_0のインターフェース
src = 06:21:2d:67:a9:b5 # MPLS_R1のveth-m1_1のインターフェース
type = MPLS # PayloadにMPLSパケットを持つ
###[ MPLS ]###
label = 25 # MPLS shimヘッダーに、Labelとして25が設定されている
cos = 0
s = 1
ttl = 63
###[ IPv6 ]### # MPLS のPayloadにあるオリジナルのIPv6パケット
version = 6
tc = 0
fl = 485074
plen = 64
nh = ICMPv6 # Next Headerは、ICMPv6
hlim = 63
src = 10::2 # LAN Segment Host1のアドレス
dst = 20::2 # LAN Segment Host2のアドレス
###[ ICMPv6 Echo Request ]###
type = Echo Request
code = 0
cksum = 0xf2f3
id = 0x4682
seq = 0x1
data = (snip)
なお、前回のコラムで述べた、MPLSによるSR-MPLSでは、始点において、終点までに経由する経路上のSIDをMPLS ShimヘッダーのLabel値に設定し、これを定義した分、スタックします。これは、SRv6のIPv6 Option Header Segment Routingヘッダーの中のaddresses フィールドに設定されるアドレスリストに相当します。上記で説明したようなMPLS IPv6トンネルでなく、SR-MPLSによるトンネルで構成することも考えられます。
ここでは、ENCAP設定の参考比較として、SR-MPLSでなく、SRv6と従来のMPLS IPv6 トンネルとの比較をしてみました。
SRv6 VPNにおけるControl Planeの考察
SRv6を用いたVPNを構成では、アンダーレイネットワークであるIPv6 ネットワークの両端に、SRv6トンネルの始点、終点となる、ENCAP設定を行うルーター機器を設置します。VPNを構成する複数のLAN Segment相互間で通信を行うためには、設置されたルーター機器は、Local側からRemote側へSRv6トンネルを設定するとともに、Remote側からLocal側の反対方向のSRv6トンネルを設定する必要があります。
このため、Local側でENCAP設定を行うためには、通信をしたい相手が所属するLAN SegmentのPREFIXと、このLAN Segmentが接続するSRv6トンネルの終点を定義するCPEのアドレス情報が必要になります。加えて、SRv6トンネルの終点となるCPEのアンダーレイネットワークとの接続状況が変わったとき、例えば、CPEのインターフェースがDownする、そのアドレスが変更される、というような状況変化が生じたときには、相互間の疎通を維持するためには、当該LAN Segmentに向けた、Local側で設定したSRv6トンネルの設定内容を適切に変更する必要があります。
例えば、2つのインターフェースによりCPEがアンダーレイネットワークに接続されているような場合に、片側のインターフェースがDownしたとします。Remote側では、Downしたインターフェースに向けてのSRv6トンネルを使うよう、metric値を調整している場合、何もしなければ、RemoteからのLocalに送信されるパケットは、Downしたインターフェースに向けた優先度の高い、SRv6トンネルを使おうとするため、疎通ができなくなります。Remote側では、Local側の状況変化を把握することができないと、UPしているインターフェースに向けたSRv6トンネルを利用するよう、Metric値を調整できません。
つまり、アンダーレイネットワークの両端のLAN SegmentをSRv6トンネルで接続するルーター機器間で、LAN SegmentのPREFIX情報とSRv6トンネルの終端を定義するインターフェースアドレス情報をお互いに交換、何か変化があれば、これを情報共有する必要があります。これを動作させる制御メカニズムが、SRv6VPNにおけるコントロールプレーンで求められる基本機能になります。
図4にまとめたように、この機能を実現する方式としては、(1)例えば、BGPのようなルーティングプロトコルを用いて、PREFIXとNEXT HOP情報の交換を行う方法と、(2)LAN SegmentのPREFIXとNEXT HOPに相当するSRv6トンネルの終端情報をControllerに相当する機器により一元管理し、LAN Segmentのエッジに位置するSRv6トンネルの始点、終点に相当するCPEが、同内容を登録、または、問い合わせできるという方式の2つが考えられます。[6]でも、(1)の方式として、BGP, BGP-LSなどを用いて、SIDを伝搬させる方式に関して述べられています。
構成するVPNの規模、LAN Segmentについて、一度設定されたらそのまま固定的であるか、または、増減や移動が多いか、といったVPNサービスの在り方、使い方に応じて、いずれかの方式を採用することになるものと思われます。
例えば、LAN Segment数が多く、固定的で、CPEに相当するルーター機器の容量、処理性能に余裕があれば、ルーティングプロトコルを動作させ、すべてのLAN Segment間をフルメッシュ(または、ルートリフレクターのような方式)でトンネルを構成することは可能になります。
一方で、LAN Segmentが頻繁にアンダーレイネットワーク上で移動、接続されるLAN Segment数の増減変化が著しく、CPEに相当するルーター機器の処理容量・処理性能に余裕がない場合で、必要なLAN SegmentのみとVPNが構成できればよい、というような場合は、軽量な(2)の方式が好ましいと考えられます。この場合、SRv6トンネルを構成するために必要な情報は、Controllerに集約一元管理され、LAN Segmentを接続するルーター機器は、BGPのようなルーター機器やController間のセッションを維持管理する重いプロトコルではなく、Message QueueやRESTAPIなど、必要な時に情報を交換する転送サービスを用いて、必要な情報の交換を行うことになります。
いずれにせよ、利用形態に応じて、採用する方法を検討することが必要になります。
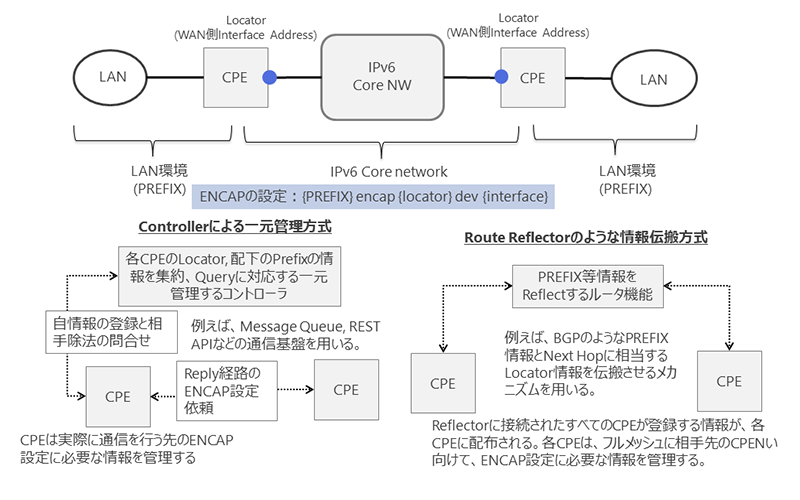
図4. SRv6 VPNサービスを提供するためのControl planeの考え方
まとめ
今回は、前回の技術概要を中心としたコラム記事に引き続き、SRv6について、少しだけ、深堀した内容について、説明しました。
動作を理解するには、パケットを見るのが一番で、説明のためのモデルネットワークを具体的に構築し、パケットのヘッダー情報を観察しました。
最後に、SRv6によるVPNサービスのコントロールプレーンの基本な考え方について、少し説明をしました。
何かの参考になれば、幸いです。
参考URL
- [1]netfilter/iptables project homepage - The netfilter.org project, https://www.netfilter.org/
- [2] GitHub - kti/python-netfilterqueue: Python bindings for libnetfilter_queue, https://github.com/kti/python-netfilterqueue
- [3] Scapy, https://scapy.net/
- [4] Segment Routing - Linux Kernel (segment-routing.net), https://www.segment-routing.net/open-software/linux/
- [5]Linux_5.11 - Linux Kernel Newbies, https://kernelnewbies.org/Linux_5.11
- [6]draft-filsfils-spring-srv6-network-programming, https://tools.ietf.org/pdf/draft-filsfils-spring-srv6-network-programming-07.pdf
- [7]GitHub - i-maravic/MPLS-Linux: MPLS enabled version of Linux kernel. Based on original work of James Leu ( http://sourceforge.net/projects/mpls-linux/ ) but almost completely rewritten!, https://github.com/i-maravic/MPLS-Linux