















まずやってみる機械学習 ~AWS SAGEMAKER/REKOGNITIONとVUEで作る画像判定WEBアプリケーション(前編)
概要
本コラムでは、機械学習を利用した画像判定Webアプリケーションの作成をゴールとします。
最初に作成するアプリケーションの完成形イメージとそれを実現するアーキテクチャ、および、この後の大まかな手順を共有したいと思います。
ゴール
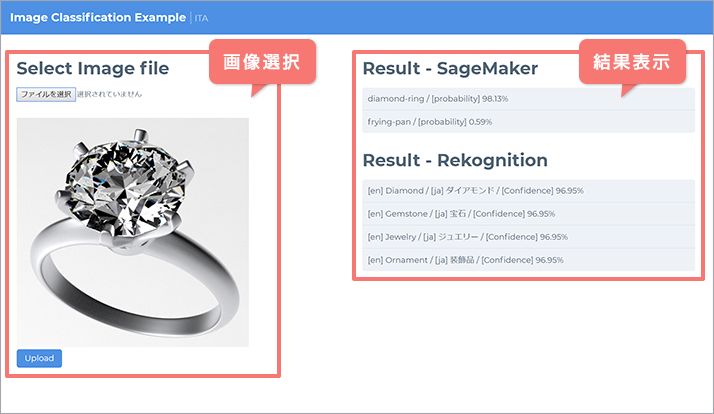
開発するWebアプリケーションの完成形イメージです。
画面左側で判定したい画像を選択し、画像に何が写っているかの判定結果を画面右側に表示します。
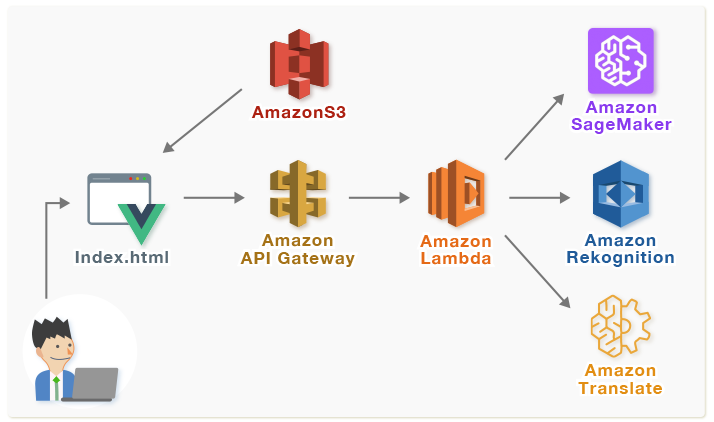
アーキテクチャ
Webアプリケーションは以下に示す構成で実行されます。ブラウザに表示するHTML, JavaScriptはS3に配置し、ブラウザからアップロードされた画像に対し画像判定を行います(アップロードした画像ファイルのS3などへの保存は行いません)。画像判定にはSageMakerにて機械学習した結果とRekognitionサービスを利用し、判定結果の日本語訳にTranslateサービスを利用しています。
手順
次節より順に作業を行います。各AWSサービスの設定方法にも触れていますが、すでにAWSを利用されている方は適宜読み飛ばしていただければと思います。
- 前編: 機械学習 (設定~学習~モデル~エンドポイント)
- 後編: Webアプリケーション開発 (設定~コーディング~配置)
なお、開発するWebアプリケーションのソースコードを先に確認したい方は以下のURLか、または、後編をご参照ください。
リージョン選択
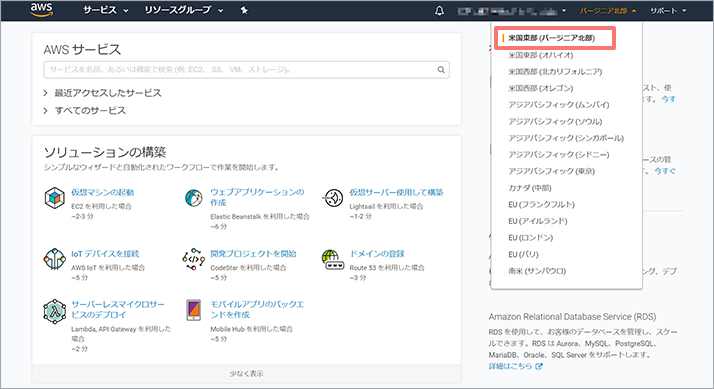
本コラムで使用するAWSのサービスには特定のリージョンでのみ提供されているサービスが含まれているため、使用するサービスが提供されている「米国東部 (バージニア北部)」リージョンにて以降の作業を行います。
ログイン後、ナビゲーションバーのアカウント情報の右側にあるリージョンリストから、「米国東部 (バージニア北部)」を選択します。
参考)AWS アカウント作成の流れ
AWSアカウントの作成方法は以下のURLを参考にしてください。
※ご注意
- 本コラムの内容については細心の注意を払って情報を掲載していますが、その正確性、完全性について保証するものではありません。本コラムの内容の利用により損害が発生した場合でも、当社は損害等の責任を一切負うものではありません。
- 本コラムにて使用するSageMakerのサンプルでは機械学習のトレーニングやエンドポイントのデプロイに関して、AWS無料利用枠の対象外であるml.p2.xlargeインスタンスが使用されているため当該手順を実施した場合は費用が発生します。ml.p2.xlargeインスタンスは$1.26/1時間のため、トレーニング時間が約30分で$0.63、加えてエンドポイントはインスタンスを起動している時間に応じて課金されます。エンドポイントは検証用としては無料利用枠のインスタンスでも問題ないため、記事内で変更の案内を示します。
- 参考)Amazon SageMaker の料金
https://aws.amazon.com/jp/sagemaker/pricing/
機械学習 (設定~学習~モデル~エンドポイント作成)
それでは機械学習を行いたいと思いますが、先ずはそのための準備をします。
1-1. 機械学習に使用するデータおよび結果の格納場所を確保 (AMAZON S3)
機械学習をはじめる前に、機械学習に使用するデータ、および、学習結果(モデル)を格納するための場所(バケット)を決めます。既存のバケットを利用することもできますが、ここでは新規にバケットを作成します。バケット作成に関する手順の詳細は以下のURLを参照してください。
参考)S3バケットを作成する方法
AWSへログイン後、S3を開きます。続いて「バケットを作成する」ボタンを押下します。
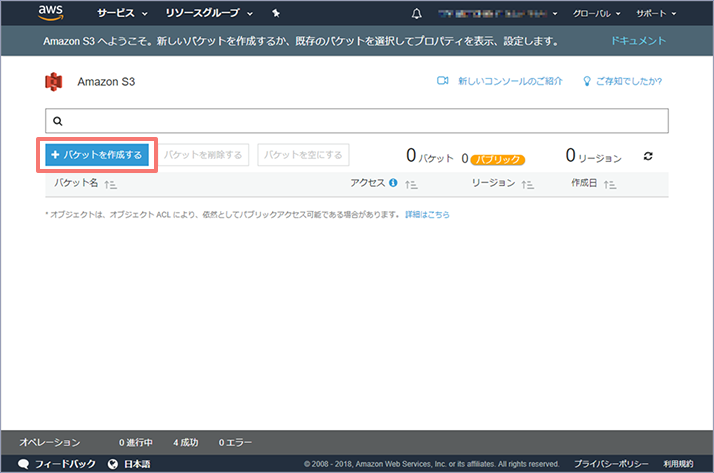
| バケットの作成: ①名前とリージョン |
画面にて以下の情報を入力し、「次へ」ボタンを押下します。なお、バケット名はリージョン内においてユニークである必要があります。使えない名前を入力したらエラーが表示されるため適宜修正してください。 |
| バケット名: | リージョン内でユニークな任意のバケット名を入力 [入力例:ita-sagemaker] このバケット名は次節にて使用します。 |
| リージョン: | 米国東部 (バージニア北部) |
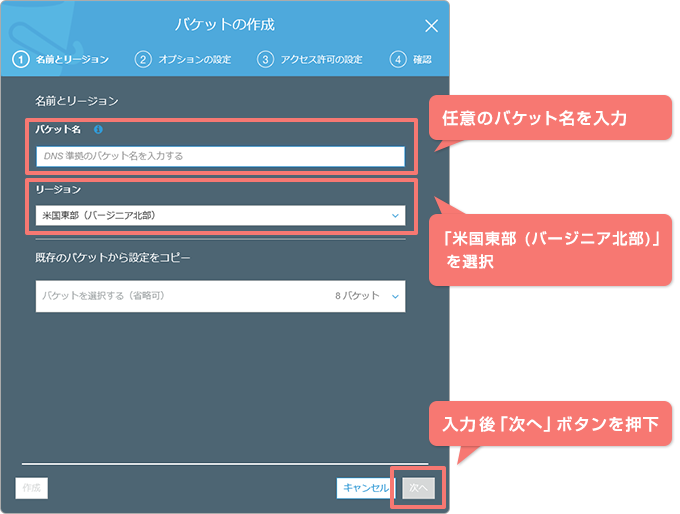
「バケットの作成: ②オプションの設定」画面、「バケットの作成: ③アクセス許可の設定」、「バケットの作成: ④確認」画面では値を変更せず「バケットを作成」ボタンを押下し、バケットの作成を完了させます。
バケット作成完了後、SageMakerを開きます。
1-2. SAGEMAKERによる機械学習の実施
SageMakerでは機械学習の実施と学習結果の保存、および、学習結果を呼び出すためのエンドポイントの作成&削除などをSageMaker内に用意されているjupyter notebookをフロントエンドとして実行することが可能です。
そのため、先ずjupyter notebookを使用するためのノートブックインスタンスを作成します。
「ノートブックインスタンスの作成」ボタンを押下します。
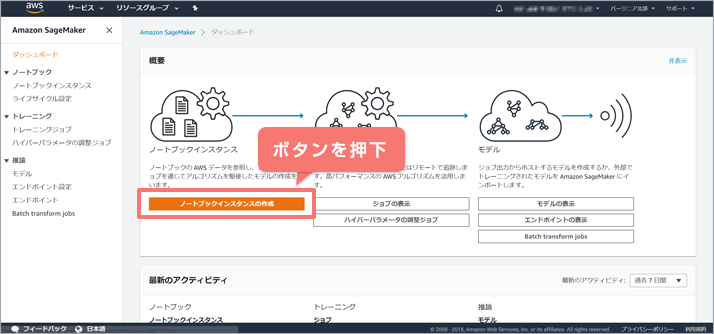
1-2-1. ノートブックインスタンスの作成
「ノートブックインスタンスの作成」画面にて、次の情報を入力します。
| ノートブックインスタンス名: | 任意の名称を入力します。[入力例:ExampleNotebookInstance] |
| インスタンスタイプ: | ml.t2.medium を選択します。 |
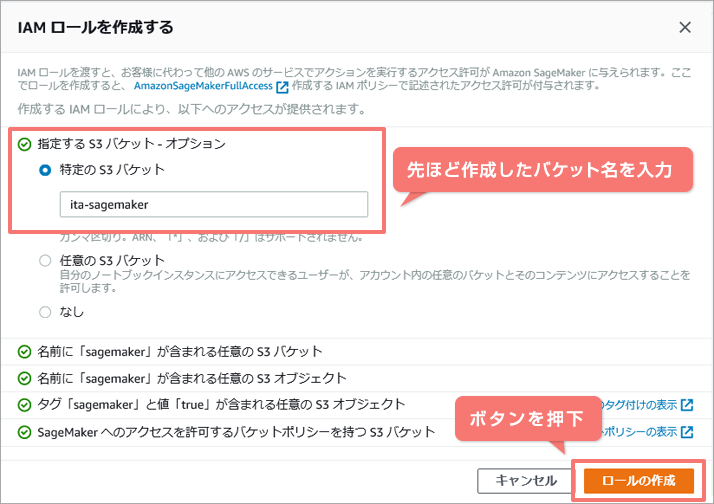
| IAM ロール: | IAM ロールを作成します。 |
[新しいロールの作成] を選択します。
特定のS3バケットに先ほど作成したバケット名を入力し、「ロールの作成」ボタンを押下。
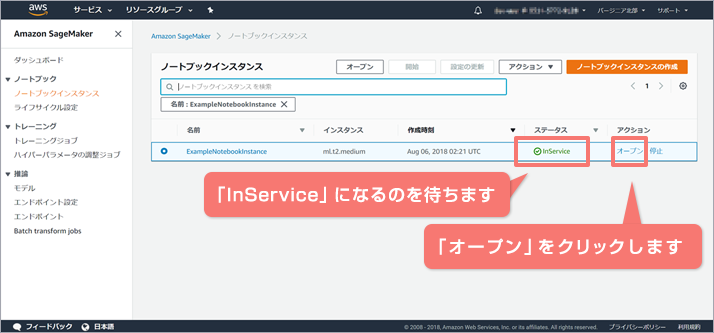
情報入力後、画面下部の「ノートブックインスタンスの作成」ボタンを押下します。ノートブックインスタンスの作成が完了したら、ステータスが「InService」になるのを待ち、アクションから「オープン」をクリックします。
1-2-2. JUPYTER上から機械学習~エンドポイント作成まで実施
jupyterのHOME画面
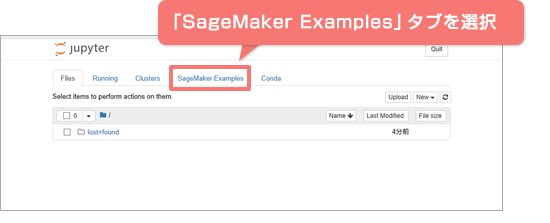
「SageMaker Examples」タブを選択し、「Introduction to Amazon algorithms」から「Image-classification-lst-format.ipynb」の「Use」ボタンを押下します。
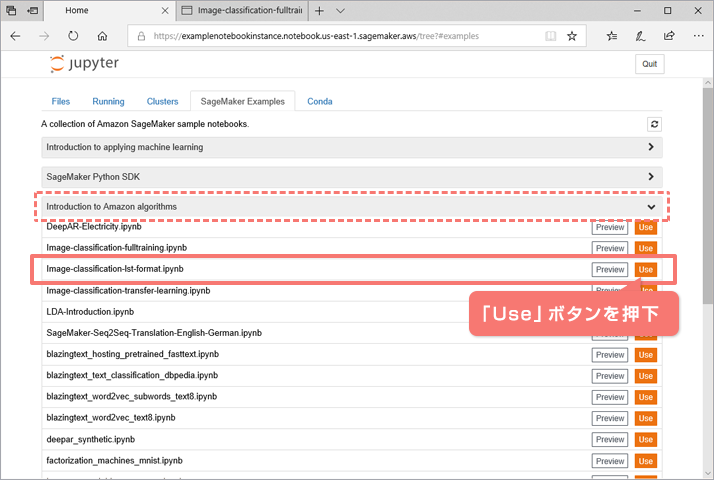
確認画面が表示されるため、「Create copy」ボタンを押下します。
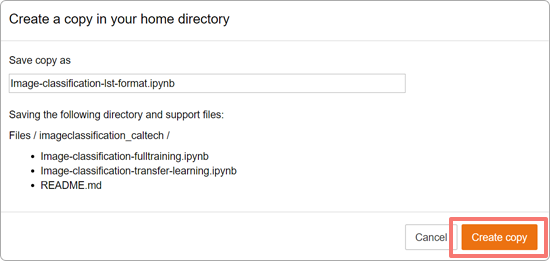
ノートブック「Image-classification-lst-format.ipynb」画面が表示されます。
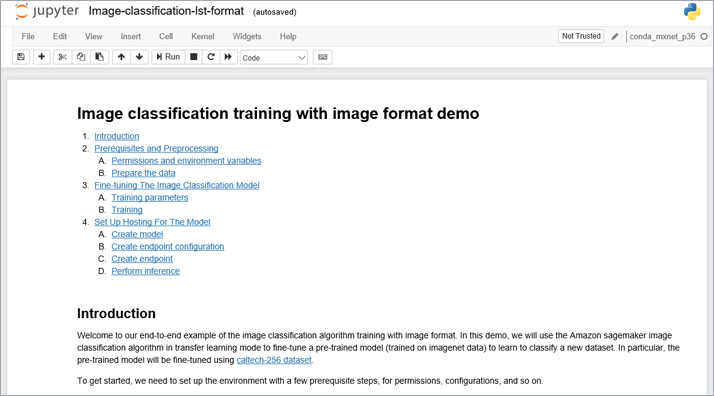
jupyterの詳細は割愛しますが、jupyterではMarkdownでメモを記述したり、pythonのコードを対話的に実行したりすることが可能です。 なお、今回使用するノートブックと同一のファイルがGitHubにて公開されています。こちらはどなたでも閲覧可能ですので、コードの実行が不要な場合などはこちらをご参照ください。
1-2-3. コードの実行
jupyter notebook上で順次コードを実行していきますが、実行する前に1か所変更する必要があります。Pythonコードの最初のセルにおける、以下のコード内の「<<bucket-name>>」を手順1-1にて作成したバケット名へ修正します。
%%time import boto3 from sagemaker import get_execution_role from sagemaker.amazon.amazon_estimator import get_image_uri role = get_execution_role() bucket='<<bucket-name>>' # customize to your bucket training_image = get_image_uri(boto3.Session().region_name, 'image-classification')
修正後のコードは以下のとおりです。
%%time import boto3 from sagemaker import get_execution_role from sagemaker.amazon.amazon_estimator import get_image_uri role = get_execution_role() bucket='ita-sagemaker' # customize to your bucket training_image = get_image_uri(boto3.Session().region_name, 'image-classification')
修正後はコードを順に実行します。コードの実行は[Shift]キー+[Enter]キー、または、画面上部のメニューから ボタンを押下します。コードはセル単位に実行されるため、実行したら当該セルの処理終了を待ち、終了後に次のセルの処理を実行します。処理実行中は画面右上の○が●になります。

また、コードを実行すると、セルの左側の「In[]」の[]内に処理中は「*」が、処理が終了すると実行された処理を実行した順番が表示されます。最初のpythonコードのセルを実行すると以下のような状態になります。
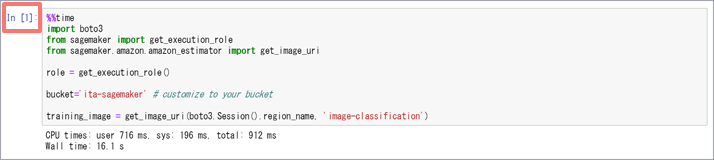
最後のセルの手前まで順に実行します(最後のセルは実行しません)。データのダウンロードやトレーニングの実施などで時間を要する箇所もあり、ネットワークの速度などにもよりますがトータルで40分前後かかります。
このノートブックでどのような処理を行っているのか、その概略を以下に記載します。
- A) 機械学習に使用するデータをダウンロードし学習用データと検証用データを準備
- このノートブックのトレーニングに使用されるデータセットはcaltech-256(http://www.vision.caltech.edu/Image_Datasets/Caltech256/)です。
caltech-256にはトータル30,607個の画像ファイルが含まれており、アメリカ国旗、バスタブ、サボテン、ダイアモンドリングなどのカテゴリーがあります。 - B) バケットへデータをコピー
- 手順1-1にて作成したバケットへデータがコピーされます。
- C) トレーニングに関するパラメータを設定
- 各パラメータの説明は以下のURLから確認できます。
https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg/IC-Hyperparameter.html - D) トレーニングを実施
- デフォルト設定で約30分前後かかります。
- E) トレーニング結果からモデルを作成
-
モデル名やロールを指定し、モデルを作成します。その後、エンドポイントを実行するインスタンスなどを設定してエンドポイント用の設定を作成します。
エンドポイントはトレーニングを行ったインスタンスとは別のインスタンスで実行されます。今回は検証のみでそれほどパフォーマンスが必要ないため、エンドポイントを実行するインスタンスを「ml.p2.xlarge」から「ml.m4.xlarge」に変更します。
「ml.m4.xlarge」に変更
endpoint_config_response = sage.create_endpoint_config( EndpointConfigName = endpoint_config_name, ProductionVariants=[{ 'InstanceType':'ml.p2.xlarge', 'InitialInstanceCount':1, 'ModelName':model_name, 'VariantName':'AllTraffic'}]) - F) モデルを使用して、エンドポイントを作成
- SageMakerでは学習済みモデルを利用してエンドポイント(API)を作成してくれるため、利用者はこのエンドポイントを呼び出すだけで機械学習した結果を利用した予測が可能になります。本コラムではこのエンドポイントにブラウザ経由でアクセスしますが、Curlなどから直接呼び出すことも可能です。
なお、作成したエンドポイントの名前はコラム後編にて使用するため留意してください(SageMakerのトップページから遷移できる「エンドポイント」画面にていつでも確認可能です)。ノートブック上ではエンドポイント名は以下のように表示されます。
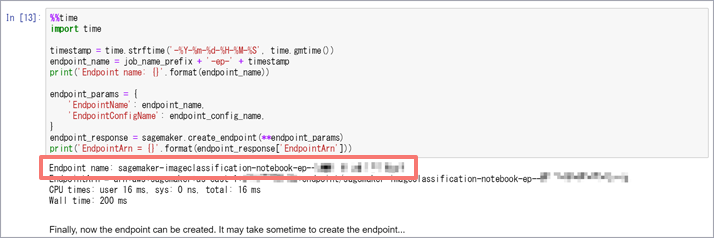
- G) テストデータを用いてトレーニング結果を検証
- テスト用の画像をダウンロードし、実際にエンドポイントを呼び出して正常に実行されることを確認します。当方の環境では以下のような実行結果となりました。
テスト画像がちゃんとバスタブと判定されたようです!
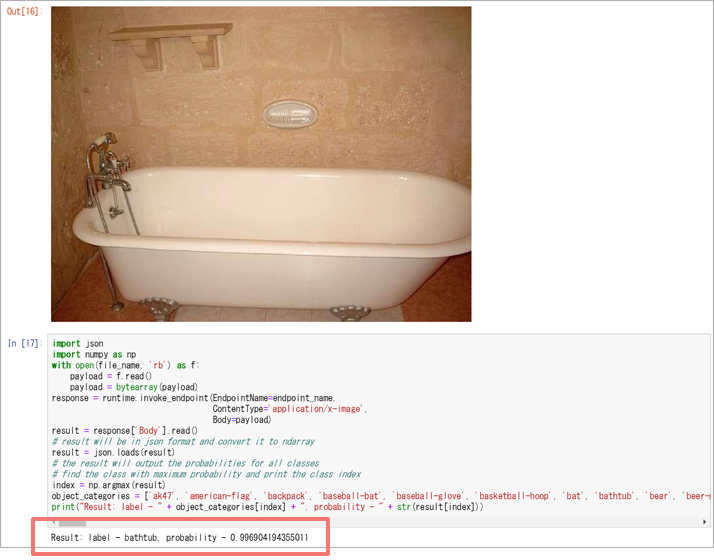
後編ではこのコードのエンドポイント呼び出し部分を参考にコーディングを行います。 - H) エンドポイントの削除
- 本コラムではエンドポイントの削除は最後に行うため、このタイミングでは実行しません。
なお、エンドポイントは起動している間は課金対象になるため、普段必要がない場合は削除しておきます。エンドポイントは削除しても学習済みモデルやエンドポイント設定があればすぐに再作成できます。
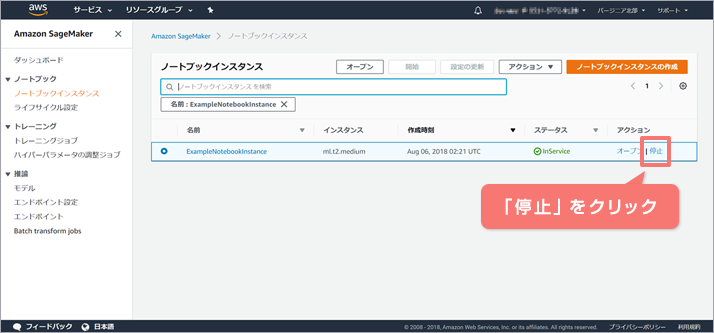
1-2-4. ノートブックインスタンスの停止
実行中のノートブックはjupyterの「Running」タブから確認できます。終了したいノートブックの「Shutdown」ボタンを押下します。
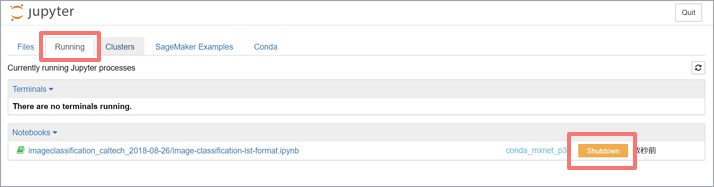
jupyterでの作業は終了したため、ノートブックインスタンスを停止させます。「ノートブックインスタンス」画面にて「停止」をクリックします。
以上で機械学習に関する作業は完了です。
後編では、この結果を利用するWebアプリケーションの開発を行います。
(田川 浩史)
Tweet