
















はじめに:生成AIの「第二フェーズ」とPrivate AIの必然性
生成AIの導入は、多くの企業で「第一フェーズ:まずは使ってみる」段階から、「第二フェーズ:ビジネスの前提としてどう組み込むか」を問う段階に移りつつあります。PoCや小規模なチャットボット実験では見えなかった課題が、現場展開・社内横断利用を進めるほどに噴き出してきているのではないでしょうか。例えば、案件で生成AIを活用したいと考えても、顧客との契約や社内ルール上、外部の生成AIサービスに顧客情報を入力できず、利用を断念するケースがあります。また、部署ごとに外部サービスを契約しようとすると、リスク評価や承認プロセスが煩雑で、利用を躊躇してしまうことも少なくありません。こうした「第二フェーズ」のキーワードの一つが、社内ネットワーク内や自社クラウド基盤でAIを安全に動かす「Private AI」です。今回は、DXを推進する情報システム部門の視点から、Private AIをどのように設計・導入し、そしてどのように守っていくのかを整理します。
DX文脈で捉え直す「Private AI」
Private AIという言葉は、しばしば「閉じた環境のAI」と説明されます。しかし、情報システム部門の視点では、それだけでは定義として不十分です。オンプレミス/クラウドを問わず共通して重要となるのは、モデルの配置場所ではなく、データ流通と制御権がどこにあるかです。一般的な外部AIサービスの利用では、外部のAIサービスへデータを送信し、その事業者の仕様や責任分界に依存します。一方でPrivate AIとは、オンプレミスに限らず、クラウド上の専用環境(VPC等)を含め、自社の管理下でデータの扱い、保持、監査、接続方式、ログ保全、さらには推論基盤の更新手順までを統制できる構成を指します。
この違いは、DX推進の現場では極めて大きく、生成AIを業務に深く組み込むほど、扱う情報は社外秘、個人情報、契約情報、設計情報、顧客対応履歴など、機微性の高いものに近づいていきます。その際、単に利用規約上「学習に使われない」と書かれているだけでは足りず、ネットワーク、認証、権限、ログ、データ分離の実装レベルまで説明できなければ、経営層や監査部門を説得しにくくなります。
特に日本企業では、データ主権や管理責任への意識が強く、国内法令への対応、海外リージョンへのデータ送信懸念、日本語業務における精度要件、既存システムとの連携事情などが重なり、Private AIへの関心が高まりやすい土壌があります。日本国内の主要ベンダーが日本語LLMをNutanixなどの環境で展開する方向性を打ち出したのも、こうした企業ニーズの表れといえます。
ただし、Private AIを導入するとすべて解決するわけではありません。データが社内にとどまることは大きな利点ですが、AIは依然として誤った回答や不適切な出力もしますし、悪意のある入力に誘導されることもあります。つまり、Private AIは、リスクを減らす土台にはなりますが、安全性を自動的に保証する技術ではありません。
別の見方をすると、Private AIの本質は「閉じること」ではなく「標準化できること」にあります。社内ナレッジや業務ルールをAIに接続し、回答の基準をそろえ、属人的な判断を減らしていくことで、DXの中核である業務標準化と知識資産化を進められます。その際に必要になるのが、AIのどんな出力を許し、何を禁止し、どの挙動を危険とみなすかを定義・評価・改良していく仕組みと技術的対策です。
企業を悩ませる生成AIリスクの本質
生成AIの導入を巡る議論では、情報漏えいが最もわかりやすいリスクとして語られがちです。確かに、社員が機密情報や個人情報を安易にプロンプトへ入力すれば、外部AIサービスとの契約形態次第では大きな問題になりえますが、情報システム部門が向き合うべきリスクは、それだけではありません。入力、保存、学習、再利用、出力、監査という一連のライフサイクル全体に、従来システムとは異なる性質の不確実性が存在しています。
第一に、AIはもっともらしく間違えます。いわゆる幻覚は、単純な誤変換のような目立つエラーではなく、文脈に沿った自然な文章として現れるため、業務で使うほど危険性が高まります。社内問い合わせ対応で誤った手順を案内したり、調達条件や契約条項を誤解した要約を出したりすれば、業務効率化どころかミスを増幅させる可能性があります。これは「精度が低い」では済まず、誰がどの段階でチェックし、どこまで自動化するかという設計の問題になります。
第二に、生成AIにはAI特有の攻撃面があります。代表的な例がプロンプトインジェクションや脱獄であり、ユーザーや外部文書からの入力によって、想定していない指示へ誘導される危険があります。これは従来のWebアプリケーション脆弱性と似て見える部分もありますが、AIが自然言語を解釈して動く以上、単純な入力検証だけでは防ぎきれません。攻撃シナリオも多様で、隠された命令、役割偽装、出力制約の回避など、従来セキュリティとは異なる発想が必要になっています。
第三に、シャドーAIの問題があります。部門単位で便利なAIサービスを使い始めること自体は自然な流れですが、利用実態が見えないまま拡大すると、どこにどのデータが入り、どんな判断がAIに委ねられているかを情報システム部門が把握できなくなります。シャドーITは以前からありましたが、シャドーAIは「生成された内容がそのまま判断や顧客対応に使われる」「モデルの振る舞いが可変で説明しづらい」という点で、統制の難しさが大きくなります。
そして第四に、既存セキュリティ製品だけでは対応が難しい点が挙げられます。ファイアウォール、WAF、EDR、DLPは依然として重要ですが、それらは主にネットワーク、エンドポイント、既知のデータ流出経路を守る仕組みです。AIシステムで本当に問題になるのは、「AIがこの文脈でどう振る舞うか」であり、その挙動は通信制御だけでは十分に管理できません。だからこそ、AIそのものをテストする「AIレッドチーミング」と、入出力レベルでの制御を担う「AIガードレール」が必要になります。
AIレッドチーミングとは何か(攻撃視点からの検証)
「AIレッドチーミング」は、AIシステムに対して意図的に攻撃的・逸脱的な⼊⼒を行い、どのような挙動を示すかを検証するアプローチで、実運用前にリスクを可視化できます。従来のセキュリティテストがインフラやアプリケーションの脆弱性を対象としていたのに対し、AIレッドチーミングは「モデルの振る舞い」そのものを対象とします。
テスト対象は多岐にわたります。例えば、禁止された出力を回避して生成させられないか、外部文書に埋め込まれた命令でAIの応答方針が乗っ取られないか、学習・登録されている機密情報を推測・再現できないか、AIエージェントが危険な操作を勝手に実行しないかといった観点で実施します。これは、どの脅威が現実の業務に影響しうるかを洗い出す作業です。
ここで重要な点は、すべてを網羅しようとしないことです。AIレッドチーミングは、ビジネス重要度、法的影響、ユーザー影響、露出度を踏まえて優先順位をつけるべきで、例えば、社内文書検索の補助ツールと、顧客へ直接回答するチャットボットでは、許容できる誤動作の幅も、テストの深さも異なります。情報システム部門は、ここで技術チームと業務部門の間に立ち、どのユースケースが高リスクなのかを整理する役割を担います。このときの成果物は、「何件突破できたか」という派手な数字よりも、「どの条件でどのような失敗が起きたか」「それをどう抑止・検知するか」という知見の蓄積となります。
企業によっては、自社のセキュリティチームや開発部門だけでは十分なノウハウを持たない場合もあります。その場合は、AIセキュリティ専業ベンダーや外部レッドチームを活用する選択肢が現実的です。AIレッドチーミングサービスを提供する外部ベンダーは、海外では多数あり日本国内のベンダーでも提供が開始されています。このような状況では、ベンダーの技術レベルなどの選定基準が重要になってきますが、参考情報としてOWASP GenAI Security Projectが公開するベンダー評価基準「OWASP Vendor Evaluation Criteria for AI Red Teaming Providers & Tooling」があります。この文書では確認すべき「グリーンフラグ」と「レッドフラグ」が定義されており、これらの確認項目から、自社に適した現実的な脅威モデル、評価の厳密さ、ツールの品質などを提供するAIレッドチーミングベンダーをピックアップします。
AIガードレールとは何か(運用視点の統制)
一方で、リスクを検出するだけでは不十分です。そこで必要になるのが「AIガードレール」です。これは、AIの入出力や振る舞いを制御する仕組みであり、ポリシーベースのフィルタリング、応答制御、ログ監視などを含みます。ガードレールは単なる制限ではなく、「安全に使うための設計思想」と捉えるべきです。適切に設計されたガードレールは、ユーザー体験を損なうことなく、組織として許容可能な範囲にAIの挙動を収めます。
重要なのは、ガードレールが単純なNGワードフィルタではない点です。企業利用では、同じ単語でも文脈によって許容可否が変わり、例えば、個人名の表示が常に禁止とは限らず、問い合わせ本人への回答では許容されても、別案件への混入は許されないことがあります。従って、実務で必要なのは、文脈、役割、データ分類、操作権限、業務ルールを踏まえた制御であり、ポリシーエンジンとしての設計が求められます。
ガードレールが防ぎたいリスクは大きく四つあります。第一に、機密情報や個人情報の不用意な外部送信や再出力です。第二に、法令や社内ルールに反する提案や表現です。第三に、差別・ハラスメント・不適切助言など、企業ブランドを損なう出力です。第四に、AIエージェントや自動化機能が、権限を超える操作や危険なアクションを実行することです。近年は、F5社やNVIDIA社のように、AIガードレールやエージェント制御を強化する製品・機能を打ち出すベンダーも増えています。これは、AIの安全性がもはやモデル単体の話ではなく、運用基盤として独立した制御レイヤーを必要としていることの表れです。特にPrivate AIでは、このレイヤーを自社ポリシーに合わせて設計しやすく、情報システム部門の価値が出やすくなります。
日本企業で考えるべきポリシーは、抽象論ではなく業務ルールから逆算するのがよいと考えられます。個人情報はどの粒度まで許容するのか、未公表情報はどのように扱うのか、特定業法に触れる助言はどこで止めるのか、どの部門の誰が最終確認を行うのか、といった判断基準を明文化します。それをAIに適用可能なルールへ落とし込むことが、ガードレール導入の出発点となります。
実務でガードレールを検討すると、企業の規模が大きくなるにつれて、全社に適用できるルールなのか、部署やチームごとに適用すべきルールなのか区分けした多層的なガードレール設計が重要な論点になります。全社的ルールの適用時は、専門知識がない担当者でも維持しやすい、汎用的なリスクに対して一定の検知・制御が可能な標準設定を持つ製品が比較的導入しやすいです。開発チームや業務システムごとにマスキングすべき情報は異なるため、個別ルールをどこまで柔軟に追加できるか、検知漏れ・誤検知をどの程度チューニングできるか、さらにルール更新や例外対応にかかる運用コストまで含めて評価する必要があります。特に個人情報については原則としてブロック対象としつつも、表記ゆれや文脈依存による検知漏れ・誤検知が起こりうるため、ガードレールだけで完結させず、ログ確認やルール更新を含めた運用設計が重要になります。
Private AIとレッドチーミング、ガードレールをどう統合するか
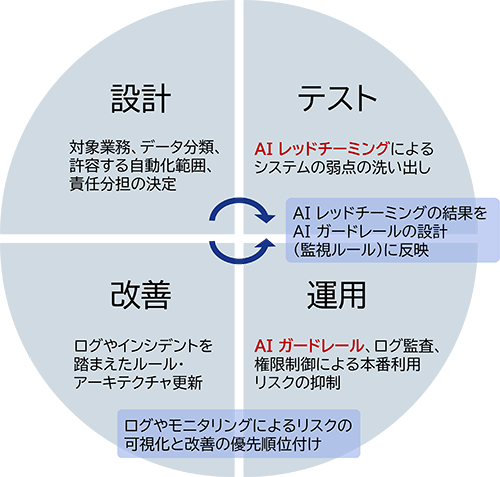
ここまでを別々のテーマとして理解すると、Private AIはインフラ、AIレッドチーミングはセキュリティ診断、AIガードレールは防御フィルタ、という分断した見方になりやすくなります。しかし、実際には、この三つは一つの運用サイクルとして設計した方がうまくいきやすく、Private AIは制御しやすい環境を提供し、AIレッドチーミングはそこに潜む弱点をあぶり出し、AIガードレールは発見された問題を日々の運用で抑え込む役割を担うことになります。
運用モデルとしては、「設計→テスト→運用→改善」の循環を明示することが重要です。設計フェーズでは、対象業務、データ分類、許容する自動化範囲、責任分担を決めます。テストフェーズでは、AIレッドチーミングにより危険な入出力、想定外の応答、越権動作の可能性を洗い出します。運用フェーズでは、AIガードレール、ログ監査、モニタリング、権限制御により、本番利用でのリスクを抑えます。改善フェーズでは、ログとインシデントを踏まえて、ルールやアーキテクチャを更新します。
この中で特に重要なのが、AIレッドチーミングの結果をガードレール設計へ反映する部分です。例えば、特定の回りくどい依頼文で機密情報がにじみ出ることがわかったなら、その条件を抽象化して入出力検査ルールに落とし込みます。外部文書の埋め込み命令にAIが引きずられるなら、入力ソースの信頼性チェックや文書分離ルールを強化します。つまり、AIレッドチーミングは一回限りのイベントではなく、AIガードレールを育てるための学習装置として機能します。
加えて、ログとモニタリングは三者をつなぐ神経系となります。どの入力が拒否されたか、どの出力が警告対象になったか、どの部門で誤用が起きやすいかを見える化しなければ、改善の優先順位が定まらないことになります。情報システム部門にとっては、従来のSIEMや監査ログの考え方をAI利用へ拡張するイメージで捉えると理解しやすく、AI固有の失敗も、結局は観測できる形にしてはじめて管理対象になります。
DX推進担当者が押さえるべき実装ポイント
DX推進担当者が押さえるべきポイントは三つあります。第一に、Private AI導入と同時にAIレッドチーミングを計画すること。後付けではなく、設計段階から組み込むことが重要です。第二に、AIガードレールを「静的なルール」ではなく「継続的に改善する仕組み」として運用すること。AIの利用が広がるほど、新たなリスクシナリオが発生するためです。第三に、技術だけでなく運用プロセス(監査、ログレビュー、インシデント対応)を含めた統合的な管理体制を構築することです。なお、この統合的な管理体制の詳細については、次回の記事「AIガバナンス」にて解説します。
おわりに:安全性が普及を加速させる
Private AIの普及は、単なる技術導入ではなく「信頼できるAI運用」の確立にかかっています。そして、その信頼性を支えるのがAIレッドチーミングとAIガードレールです。安全性と利便性を両立させることで初めて、AIは業務基盤として定着します。DXを加速させるためにも、これらを前提としたAI活用戦略が求められています。
なお、当社では、NTTデータ社と連携して、AIレッドチーミングやAIガードレールを含め安心・安全なAI利用を支援するサービスを提供していますので、お気軽にお問い合わせください。
AIの安心・安全な活用を支援する「Responsible & Secure AI」サービスを本格展開 | 株式会社NTTデータ先端技術
- ※文中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。