















楽しい可視化 : elasticsearchとSpark Streamingの出会い
Tweet

ソリューション事業部
ビッグデータ基盤ビジネスユニット 主任エンジニア
川﨑 寛文
0. ログやデータを取得した後は?
ログやデータの分析には、様々なアプローチが考えられるが、Apache Solrやelasticsearchといった全文検索エンジン製品にデータを蓄積し、その機能を用いて検索・集計・分析を行う方法がある。その際、データをそのまま蓄積するのではなく、各ツイート・各行に属性を付与(エンリッチメント)することにより、分析の幅は大きく広がる。
全文検索エンジンへのデータの投入では、Flume-ngやfluentdといったデータ収集製品を利用する実例が多い。しかし、リアルタイムにデータに対してエンリッチメントの前処理を行おうとした場合、処理が複雑になるにつれ、単体サーバーで動作するFlume-ngやfluentdでは処理能力が頭打ちになってくる。そこで、登場するのが、リアルタイムに大量のデータを処理することができるストリーミング処理系のビッグデータ関連技術である。
今回は、リアルタイムにビッグデータを処理できるApache Sparkにてツイートを収集した上で、それを近年注目されているLuceneベースの全文検索エンジンであるelasticsearchへ投入し、elasticsearch上で集計・分析を行う例を紹介する。
1. elasticsearchの概要
elasticsearchは、Apache Solrなどと同じように検索処理を担い、検索サイト等を実現するための全文検索エンジンである。最近はKibanaという可視化ソフトウェアとセットで用いられることが多く、サーバーのアクセスログの可視化やTwitter等のSNSデータを投入して、簡易な可視化を実現することができる。
elasticsearchには、以下のような特徴がある。
⑴ スケールが容易
elasticsearchはクラスタ構成が前提で、マシン1台の場合でも、1台構成のクラスタとして起動する。そのため、追加でelasticsearchマシンを同一のクラスタ名、かつ、同一ネットワークで起動すれば、既存データの分散やレプリカ等も自動で実行される。
⑵ スキーマレス
最初にテーブルを定義しなくとも、すぐにデータ投入を開始できる。また、後からフィールドの追加が必要となった場合も、問題なく対応できる。当然、定義を明示的に行うことも可能である。
⑶ すべての入出力は、REST & JSONである。
すべての入出力は、RESTインタフェースで行われ、JSON形式のデータにて入出力を行う。そのため、特別な形式変換や接続ライブラリが無くとも、汎用的なHTTPおよびJSONをサポートするライブラリがあれば、開発言語に関わらずデータの入出力が可能である。
⑷ 可視化が容易
elasticsearchは、elasticsearch社が開発した可視化ソフトウェアのKibanaとの連携が優れており、簡単に結果データをグラフなどで閲覧することができる。
⑸ ビッグデータ処理系による分析を行える。
elasticsearchは、ビッグデータ処理基盤であるHadoopに対応しており、ビッグデータ処理によるテキストデータのエンリッチメントやデータ整形処理等を容易に行える。また、現在ベータ版ではあるが、Spark、Storm等でelasticsearchへの入出力が行えるライブラリが用意されている。
上記の特徴により、リアルタイムサーチもビッグデータ解析も同じ環境で実現したい等の要望が有った場合には、データストレージとして、elasticsearchを使用することも検討することをお勧めする。本コラムでは、elasticsearch及びKibanaのセットアップ及び可視化表示の確認と、Sparkからelasticsearchへデータを投入するやり方を記述するので、参考にして頂きたい。
2. elasticsearchとビッグデータ処理技術の組み合わせたアーキテクチャ
Sparkとelasticsearchを使用した場合に考えられるアーキテクチャとして、Twitterを例にすると、オフラインバッチにより一定時間おきに分析・エンリッチメントを行う方式と、リアルタイムにテキスト情報や位置情報等のエンリッチメントを行う方式の2パターンが考えられる。前者はHadoopでも代用できるが、後者がSparkを用いる特に大きな利点であり、今回は後者について実例を示したい。具体的には、Twitterよりリアルタイムにデータを読み込み、必要なデータをフィルターし、elasticsearchへ投入する処理プログラムおよびelasticsearchの構築方法を示す。
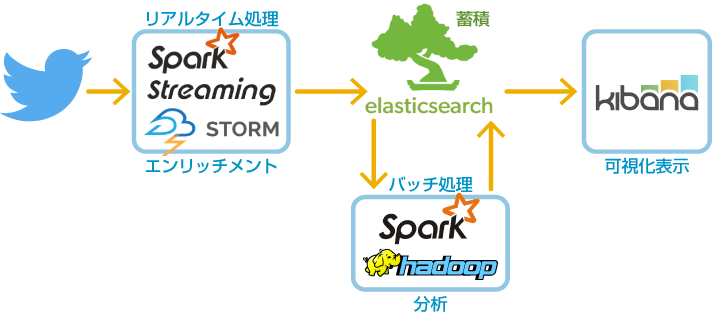
3. 実際にelasticsearchを使ってみる
本節にて、エンリッチメント処理の実装は省略するものの、ビッグデータ処理系のApache Sparkを用いてTwitterのストリームデータをelasticsearchへ実際に投入し、Kibanaにて可視化表示するまでについて、セットアップ、及び、実行の手順を説明する。
3.1. 動作環境
- OS : Windows(Windows 7 64bitで動作確認済)
- Java : 1.7.0以上(1.7.0 Update 25で動作確認済)
- Spark : 1.0.2以上(1.0.2で動作確認済、セットアップ方法については、「Apache Sparkで始めるお手軽リアルタイムウインドウ集計」を参照して頂きたい。)
3.2. 事前準備
elasticsearchの実行のために、JAVA_HOMEの設定が必要である。そのためまず、環境変数にJAVA_HOMEを設定する。
- 「ウィンドウズキー+R」でファイル名を指定して実行を開き、「sysdm.cpl」と入力し、「OK」をクリックする。
- 「詳細設定」タブをクリックして開き、「環境変数」をクリックする。
- 「システム環境変数」の「新規」をクリックする。
- 「変数名」を「JAVA_HOME」、「変数値」を「C:\Program Files\Java\jdk1.7.0_25」と入力する。(jdk1.7.0_25の部分は、インストールされているJavaのバージョンおよびディレクトリ名を使用すること。)
- 「OK」をクリック。(何回か「OK」や「閉じる」をクリックし、「システムのプロパティ」を閉じる。)
3.3. elasticsearchのインストール
- Webブラウザで、 「 https://www.elastic.co/jp/downloads/elasticsearch 」 にアクセスし、elasticsearch1.4.xのzipをダウンロードする。(執筆時点では、1.4.1)
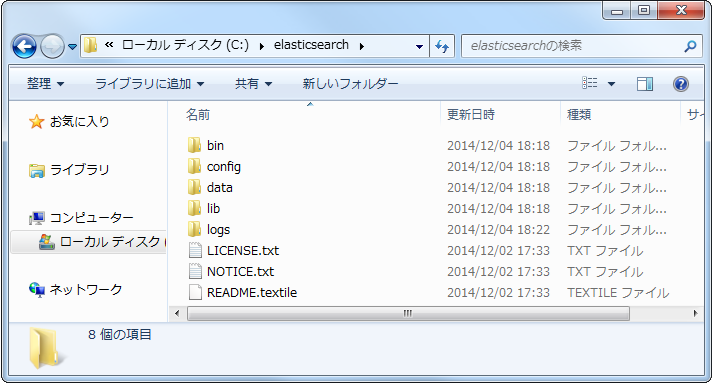
- c:\elasticsearchとして解凍する。
- 解凍後に、c:\elasticsearchを開き、以下の図のようにファイルが展開されていることを確認する。
3.4. Kibanaのインストール
実際に運用する場合には、別途Apache等のWebサーバーをインストールする必要があるが、今回は、elasticsearchを簡易サーバーとして利用する。
- c:\elasticsearchにpluginsというディレクトリを作成する。
- c:\elasticsearch\pluginsにKibanaというディレクトリを作成する。
- c:\elasticsearch\plugins\kibanaに_siteというディレクトリを作成する。
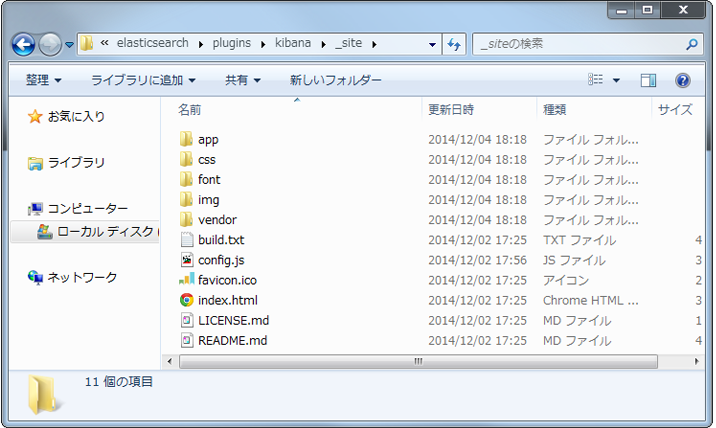
- c:\elasticsearch\plugins\kibana\_siteに、ダウンロードしてきたzipの中身を解凍する。
- 解凍後に、以下の図のようにファイルが展開されていることを確認する。
3.5. elasticsearch on sparkのインストール
Apache Sparkからelasticsearchへデータの読み書きをするには、elasticsearch社が提供しているライブラリが必要となる。そのため、本節では、Sparkへのライブラリのインストールを行う。
- Webブラウザで、 「 https://www.elastic.co/jp/downloads/elasticsearch 」 にアクセスし、elasticsearch-hadoop 2.1.0.beta3のzipをダウンロードする。(執筆時点では、2.1.0 Beta3)
- ダウンロードしてきたzipファイルを展開する。(展開場所は任意)
- elasticsearch-hadoop-2.1.0.Beta3\distディレクトリ内の elasticsearch-spark_2.10-2.1.0.Beta3.jar を c:\spark\lib 内にコピーする。
- エディターで c:\spark\bin\spark-class2.cmd を開く。(メモ帳は不可)
- 「 "%RUNNER%" -cp "%CLASSPATH%" %JAVA_OPTS% %* 」の上に「 set CLASSPATH=%CLASSPATH%;%SPARK_HOME%\lib\elasticsearch-spark_2.10-2.1.0.Beta3.jar 」を追加し、保存する。
3.6. elasticsearch&Kibanaの起動
- 「ウィンドウズキー+R」を押し、「 cmd 」と入力し、「OK」をクリックする。
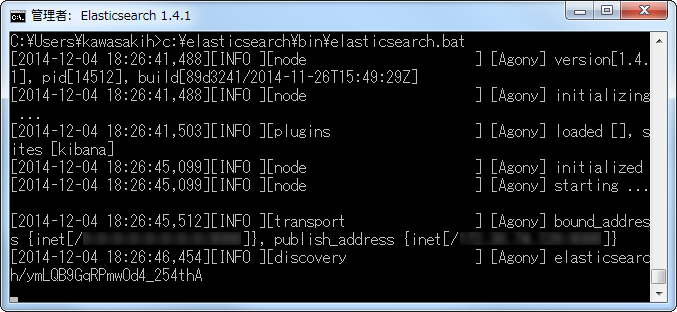
- コマンドプロンプトが表示されたら、「 c:\elasticsearch\bin\elasticsearch.bat 」と入力し、「Enterキー」を押し、elasticsearchを実行する。(実行後した後のコマンドプロンプトは、そのまま表示させておくこと。)
- 実行後に、以下の図のような実行画面が表示されたことを確認する。(もし、「JAVA_HOME environment variable must be set!」等のメッセージが表示された場合、JAVA_HOMEの設定を見直して頂きたい。)
3.7. Sparkの起動
- 「ウィンドウズキー+R」でファイル名を指定して実行を表示させて「 cmd /c c:\spark-1.0.2-bin-cdh4\bin\spark-shell.cmd 2> nul 」と入力し、「OK」を押す。
- 起動したコマンドプロンプトに以下をコピーして貼り付けて実行させる。(実行後、コマンドプロンプトはそのまま表示させておくこと。)
// Twitterからデータを取得し、elasticsearchへ投入するSparkプログラム
import org.elasticsearch.spark._
import org.apache.spark.streaming.dstream._
import org.apache.spark.streaming._
import org.apache.spark.streaming.twitter._
import org.elasticsearch.spark.rdd.EsSpark
System.setProperty("twitter4j.oauth.consumerKey", "xxxxxxxxxxxxxxxxxxxx")
System.setProperty("twitter4j.oauth.consumerSecret", "xxxxxxxxxxxxxxxxxxxx")
System.setProperty("twitter4j.oauth.accessToken", "xxxxxxxxxxxxxxxxxxxx")
System.setProperty("twitter4j.oauth.accessTokenSecret", "xxxxxxxxxxxxxxxxxxxx")
val ssc = new StreamingContext(sc, Seconds(2))
val index_name = "twitter"
val type_name = "iPad" // Search Word
TwitterUtils.createStream(ssc, None, Array(type_name)).
// TwitterのデータをJSON化
map ( status => {
var lonlat : Array[Double] = Array()
val hashmap = new java.util.HashMap[String, Object]()
hashmap.put("user_name", status.getUser().getName())
hashmap.put("user_lang", status.getUser().getLang())
hashmap.put("text", status.getText())
hashmap.put("@create_at", new java.text.SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ssX").format(status.getCreatedAt()))
if(status.getGeoLocation() != null) {
lonlat = Array(status.getGeoLocation().getLongitude(), status.getGeoLocation().getLatitude())
}
hashmap.put("location", lonlat)
(new org.json.JSONObject(hashmap).toString())
}).
// elasticsearchへデータを投入
foreachRDD(jsonRDD => {
EsSpark.saveJsonToEs(jsonRDD, index_name+"/"+type_name)
}
)
ssc.start()
- 上記コードを実行後に、以下の図のような表示がされていることを確認する。
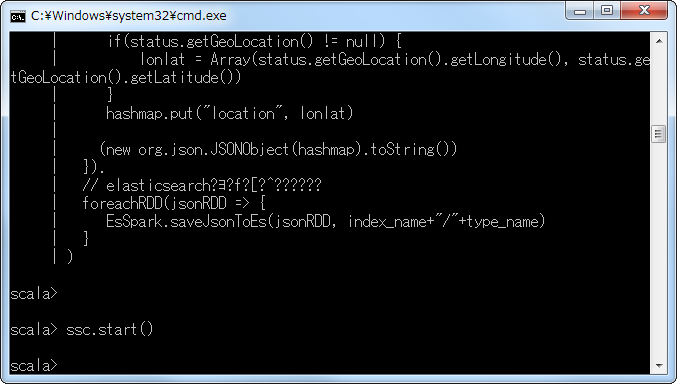
3.8. Kibanaで可視化表示
- Webブラウザで http://localhost:9200/_plugin/kibana にアクセスする。
- 「Simple Dashboard」をクリックする。
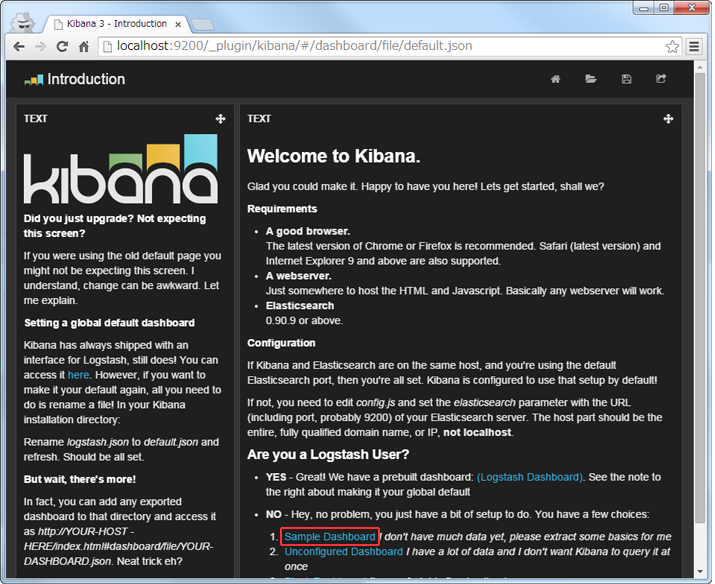
- 以下のような初期画面が表示される。
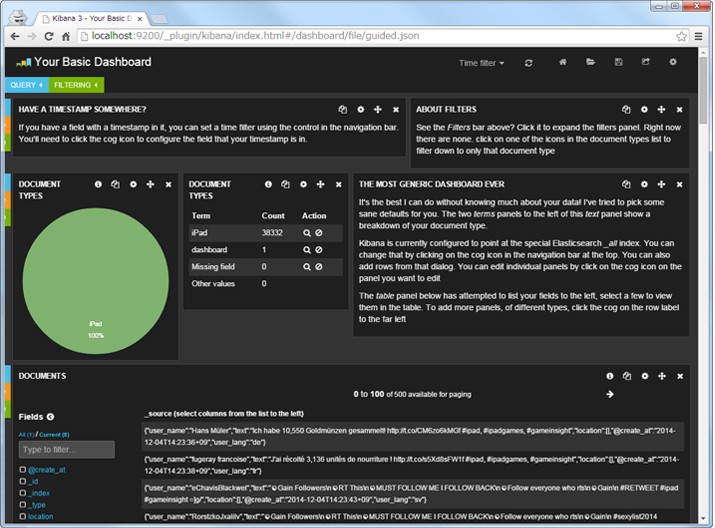
- また、少しビューを整理すると、以下のようにツイートを可視化することができる。
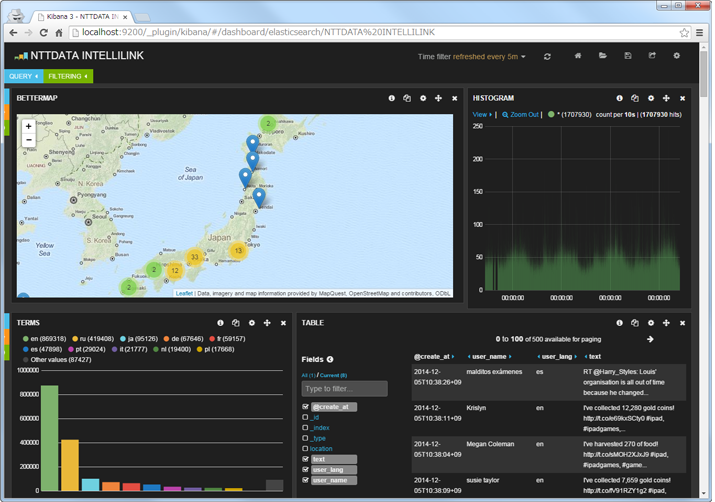
4. Spark Streamingプログラムの仕組み
Spark Streamingを用いて、実際にTwitterのStreaming APIからデータを取得し、elasticsearchに格納するという処理の実行を試みた。ここで、Spark Streamingが内部的にどのような仕組みで処理を実現しているかを説明しておこう。
先ほど実行したサンプルプログラムの内部的な動作は以下の図のようになる。
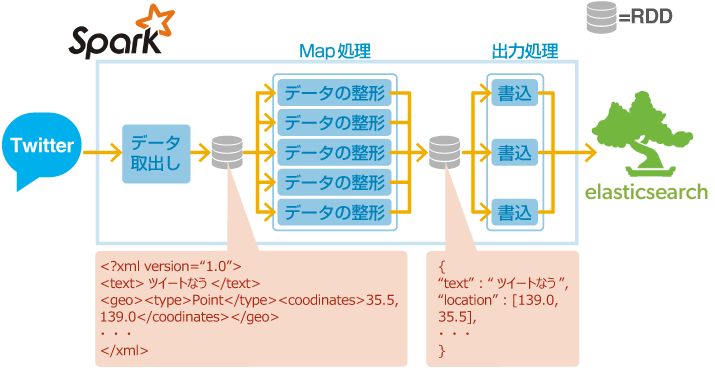
枠で囲んだ「データ取り出し」から「書込」までが、Sparkが実行する処理である。データの整形は、Map処理で実行されているため、並列分散処理が実行される。出力処理は、elasticsearchのSparkライブラリに作成したJSONを渡し、elasticsearchに投入する。
今回は、受け取ったデータの日付や位置情報の形式を変換し、elasticsearch投入用のJSONオブジェクトを生成しただけである。属性付与・エンリッチメント等の処理を実行する場合は、Map処理に記述し、分散処理させることになる。また、前回のSpark Streamingのコラムで用いたウインドウ集計機能を用いることで、単位時間辺りの分析やアラーティング等に活用できる。
5. まとめ
全文検索エンジンであるelasticsearchおよびその可視化ツールであるKibanaをご紹介した。また、リアルタイムにelasticsearchへビッグデータ処理系からの整形したデータの投入プログラムについても一緒にご紹介した。データの可視化は、分析を行う上での第一歩であるが、本コラムで紹介した方法により、非常に容易に分析環境、および、蓄積・可視化環境を構築することができる。
今回用いたKibana 3.1.2については、複数のダッシュボードを作成でき、その際、1つの画面で検索・可視化・ダッシュボード作成を行う。しかし、次期Kibanaの4.0(現在は、ベータバージョン)では、それらが別々の画面となり、よりSplunkなどのBIに近い形でデータの可視化を行うことができるようになる。また、Kibana 4.0では、elasticsearchの機能であるAggregationに対応しており、階層的に集計することができ、多重円グラフ等のより複雑な可視化表示を行うことができるようになる。
ビッグデータ処理技術のSparkについては、上記の通り、比較的簡単なプログラムを記述するだけで、リアルタイムに複数台のマシン上で分散処理を実行することができる。また、Sparkは、多様な入出力をサポートするだけではなく、機械学習ライブラリが標準で組み込まれているため、複雑な分析も行うことができ、高度なエンリッチメント処理も実現可能である。
6. より大きいデータで使用するには
今回のサンプルは1台構成にて実現したが、より多くのデータやより多くの処理を実施する場合は、elasticsearchおよびSparkをおいてクラスタ構成を取り、マシンの台数を増やすことでスケールアウトが可能である。
elasticsearchを使ってデータを柔軟に検索できる環境を構築したい場合やSparkを使ってより複雑な処理をさせたい場合などは、是非お気軽にご相談いただきたい。
Tweet