















Big Data + Fast Data = ラムダアーキテクチャー!
Tweet

ソリューション事業部
ビッグデータ基盤ビジネスユニット 主任エンジニア
小山 哲平
はじめに
本コラムでは、ビッグデータ分析とファストデータ分析を組み合わせるための仕組みである「ラムダアーキテクチャー」の紹介をする。私どもは現在、Apache Sparkを最大限に活用したラムダアーキテクチャーの構想を練っており、その実現方式が固まった際は、コラムにてサンプルを紹介しようと考えている。ただ、「ラムダアーキテクチャー」という言葉に耳慣れない人もまだ多いかと思い、まずはラムダアーキテクチャーについての説明から始めることとする。
ビッグデータ、ファストデータ関連の潮流
まずは、ビッグデータとファストデータ(≒リアルタイム、≒ストリーミング)の世間の潮流について復習する。ここでの「世間の潮流」とは、あくまで、筆者の個人的な感覚をもとにして記載している。エンジニア視点で書いているため、経営者支援やマーケッター視点とは異なると思われるが、その点はご容赦頂きたい。
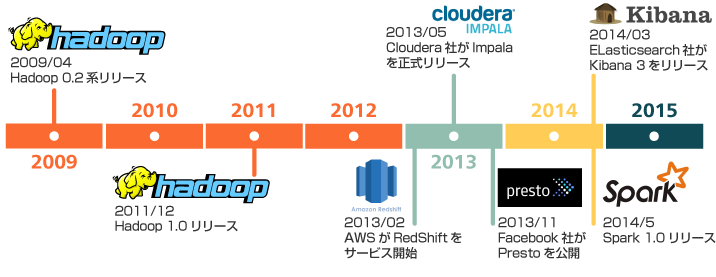
Hadoopの登場により、2009年頃から2012年に掛けて、「ビッグデータ」という言葉がかなり世間をにぎわせた。当初のビッグデータは、これまで扱えなかった規模の多量のデータを蓄積し、そのデータに対してバッチ処理を施すことにより、何らかの知見を得るというものが主であった。
当初はバッチ的にビッグデータを扱っていたが、2013年頃には、ビッグデータに対してインタラクティブに分析・集計処理を実施することも可能になり、その流れが一気に進んだ。その目的で、Apache DrillやCloudera Impala、PrestoやTezなど、Hadoop界隈だけでもインタラクティブに分析できる製品が群雄割拠状態となった。また、AmazonがRedShiftをリリースしたのもこの時期である。
2014年には、今度はリアルタイム系技術が日の目を見ることになる。それまでもStormが流行しており、先進企業やR&Dの分野では利用されていたが、Cloudera社がApache Sparkをサポート対象に加えたこともあり、リアルタイム処理を強みの一つとして持つApache Sparkが一気にブレークしたことで、リアルタイム技術の分野が身近なものとなった。また、Elasticsearch+Logstash+Kibanaで構成されるELKスタックが広まり、一般企業でもリアルタイムにログを可視化運用することが流行した。
そして、2015年、恐らく、「バッチ処理とリアルタイム処理のマージ」である「ラムダアーキテクチャー」が来ると予想する。(インタラクティブツールやELKスタックが進化し、特別なアーキテクチャーも組まずともBigData+FastDataにて分析対応できるようになってしまえば、「ラムダアーキテクチャー」という言葉は死語になるだろうが。。。)
ラムダアーキテクチャーとは?
前置きが長くなったが、ここで、ラムダアーキテクチャーの基本について説明する。
ラムダアーキテクチャーは、2012年にStorm の作者である Nathan Marz氏が最初に提唱した(http://www.databasetube.com/database/big-data-lambda-architecture/ )。
まずは、その構成を簡単に図示しよう。
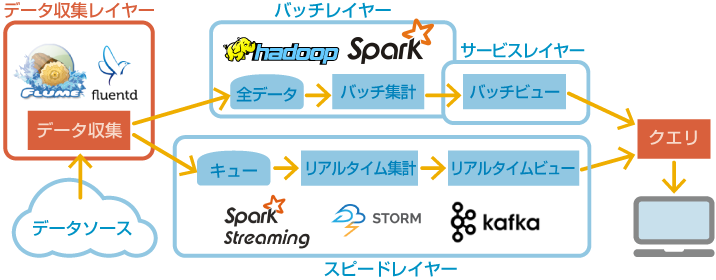
図の通り、Marz氏の提唱したアーキテクチャーでは、バッチレイヤー、サービスレイヤー、スピードレイヤーの3つの層から構成される。
- バッチレイヤーは、全量データに対するバッチ処理を担当する。精度の高い集計や、ロングテールをつかむ細かな集計が向く。
- サービスレイヤーは、バッチレイヤーの集計結果を提供する層である。例えば、専用インターフェースを用意する場合もあるだろうし、HbaseやHiveをインターフェースとして利用する場合もあるだろう。
- スピードレイヤーは、リアルタイム処理の結果を提供する層である。直近数秒、数分、数十分のイベントの集計結果を提供することになる。
そして、サービスレイヤーとスピードレイヤーの双方に対して問合せをし、その結果をマージしてユーザーに提供するようなクエリ機構を構築することで、バッチ処理の細やかな集計結果も、スピードレイヤーの最新の集計結果も、分析に反映させることができるものである。
ラムダアーキテクチャーの利用価値
ラムダアーキテクチャーの思想により、過去のデータとリアルタイムなデータを区別することなく、集計・分析することができる。例えばTwitterでは、ハッシュタグの集計にラムダアーキテクチャーを利用できる。あるハッシュタグについて、過去のツイート数のみならず、直近数秒・数分のツイート数も同時に把握できるような仕組みとなっており、より詳細なトレンドを把握できるようになる。
また、身近な例を挙げれば、マーケティングの分野への活用が考えられよう。ユーザーのアクションを検知した際、そのユーザーの過去と直近の双方の動向を理解した上で、そのユーザーのアクションに対するリアクションを決定する・・・といったことがリアルタイムに実現可能となる。
もちろん、これらのことはAmazonやGoogleといった大規模サービスでは既に行われていることである。ただ、オープンソースソフトウェアを組み合わせることでスモールスタートが可能となり、一般企業でもその仕組み構築が身近なものとなることに意味がある。
「ラムダアーキテクチャー」という言葉が広まるかどうかは正直怪しいだろう。ただ、言葉は広がらなくとも、「ビッグデータ」と「ファストデータ」を組み合わせて施策を実現するという流れは2015年度の本流になるのではないかと考えている。
ラムダアーキテクチャーへのアプローチ
Twitter社は、SummngBirdというソフトウェアを開発し、ラムダアーキテクチャーへとアプローチしている(https://blog.twitter.com/2013/streaming-mapreduce-with-summingbird )。SummngBird上で作成したジョブは、HadoopとStormの双方で動作し、その結果をマージすることができる。言うならば、HadoopとStormから構成されたラムダアーキテクチャーの「クエリ」に相当する機能を提供するソフトウェアである。
また、Bigdata関連技術を売りにしているDataSalt社は、新たにSploutSQLというソフトウェアを提供し、StormのTrident APIと組み合わせることでラムダアーキテクチャーの実現を目指している。(http://www.datasalt.com/2013/01/an-example-lambda-architecture-using-trident-hadoop-and-splout-sql/ )。
その他にも、Amazon KinesisとAmazon RedShiftを組み合わせてAWSで完結するラムダアーキテクチャーを検討している企業もあり、デファクトスタンダードはまだ存在しない状況である。
NTTデータ先端技術のラムダアーキテクチャーへのアプローチ
先述したように、既にラムダアーキテクチャーを実現している先人は存在する。ただ、それらのアーキテクチャーは、HadoopやHBase、Storm等の複数の製品を組み合わせたものとなっており、実現するならば少々複雑である。
しかしながら、今日では、バッチ処理とリアルタイム処理の双方の機能をもつApache Sparkが実用段階に入っている。Apache Sparkを用いることで、より容易にラムダアーキテクチャーが実現できるのではないかと考え、構想を練っているところである。
なお、Hadoopの両リーディングカンパニーである、Cloudera社とMapR社が共にApache Sparkでのラムダアーキテクチャー実現の検討をしているようであり(http://blog.cloudera.com/blog/2014/08/building-lambda-architecture-with-spark-streaming/ , http://spark-summit.org/2014/talk/applying-the-lambda-architecture-with-spark )、彼らがベストプラクティスを発表してしまう前に、Apache Sparkを最大限に活用したラムダアーキテクチャーの次回コラムを書きたいところである・・・。
Tweet