
















チーム開発の視点が変わる アジャイル開発の新常識 第16回 SREで実践する、インフラを巻き込んだDevOps
*本コラムは、技術評論社「Software Design」2022年3月号に寄稿したコラムを掲載しています。
はじめに
開発の現場では、アプリケーション開発(プロダクトの機能要件を担当)とインフラ構築(プロダクトの非機能要件を担当)でチームを分ける場合があるかと思います。アプリケーション開発チームはアジャイル開発を採用し、インフラ構築チームはウォーターフォール開発を採用するというケースをよく見ますが、果たしてそれで本当に継続的な改善を実現できるのでしょうか。本稿では、アプリケーションのリリース後も、インフラを含めて継続的に改善を行っていくためにはどうすればよいかを解説します。
なぜインフラはウォーターフォールで作りがちなのか
インフラ構築をウォーターフォールで行う理由は、そのプロジェクトの背景、制約などさまざまかと思いますが、次の理由が多いのではないでしょうか。
文化・組織(人)の問題
従来のシステム開発では、要件を抜け漏れなく最初に定義し、納期厳守でリリースすることが当たり前とされてきました。また、リリース後は安定運用が求められ、インフラに起因する障害は徹底的に排除すべき悪者とみなされてきました。稼働率やバグ件数が安定運用の指標として評価される組織も多いかと思います。
障害を起こさないために、本番環境障害の原因となり得るリリースや環境変更作業をそもそも実施しない、もしくは必要最低限とするという発想に至り、インフラ構成をまったく変えずに運用するような方針のプロジェクトもあるかもしれません。そのような開発・運用が長年にわたって行われている場合、継続的にシステムを改善するというマインドへの切り替えが難しくなります。とくにインフラ部分は、安定運用の土台ですので、インフラエンジニアにその傾向が強いと思います。
さらに、内部統制の観点で、開発チームと運用チームを分離しなければならない組織が多いことも継続的な改善が浸透しない大きな理由の1つです。開発と運用の分離が前提の場合、開発チームは期限内のリリースに注力し、運用については運用チームに任せるべく、運用チームへの引き継ぎを行うのが通例です。しかしその後、運用チームはマニュアルをもとに定常作業や障害発生時の対応しか行わない、そのようなケースも見てきました。この場合、開発しながら運用するDevOpsの思想は採用されることはなく、ウォーターフォールでの開発となります。
技術の問題
たとえ、文化・組織の壁を突破したとしても越えなければならない壁はまだまだあります。アプリケーションだけでなくインフラを継続的に改善させるためには、インフラを含めたCI/CDが必要です。
パブリッククラウドやInfrastructure as Code(以下IaC)が普及し、インフラをソフトウェアで技術的に制御可能となりましたが、アプリケーションだけでなくインフラにもCI/CDのしくみを実装するには、下記のようなインフラレイヤのCI/CDも検討する必要があります。
- ・ミドルウェアレイヤ:Apache HTTP ServerやApache Tomcat、PostgreSQLといったミドルウェアの設定
- ・クラウドリソースレイヤ:OSやネットワークの設定
検討の範囲が広くなり、どこから手を付ければいいかわからないというケースも多いでしょう。また、インフラ含めたCI/CDの前提となるIaCについて検索すると、2番めのキーワードに「疲れた」がサジェストされます(図1)注1。
チームが自ら改善するモチベーションを維持・向上させるためにも、現場の技術者が疲弊することは避けなければなりません。

図1 キーワード「Infrastructure as Code」をGoogle検索したときのサジェスト
ウォーターフォールが技術的負債を生む
では、インフラをウォーターフォールで開発するとどんなデメリットがあるのでしょうか。デメリットを一言で表すと「技術的負債がもたらす弊害」です。
技術的負債とは?
技術的負債とは、その名のとおり技術的な借金のことです。アメリカのプログラマーであるウォード・カニンガム氏が1992年に提唱注2した概念です。銀行からお金を借りると利子付きで返済しなければならないのと同様に、技術的負債を抱えるとそのツケを払わないといけなくなります。リリース期限に間に合わせるために妥協したシステムアーキテクチャ設計や消化しきれなかったテストケース、誰もメンテナンスできないスパゲッティ化したソースコードなどさまざまなものが技術的負債と世の中では言われていますが、本記事では、「設計時は最適とされた設計が時間の経過により最適ではなくなったもの」を技術的負債と定義します。時間の経過によって、開発チームメンバーのスキル向上や、ベータ版だった新しい技術が正式リリース版になるといった技術の進化が起こり、求められる設計も変化します。
インフラの技術的負債がもたらす弊害
● インフラの塩漬けによるリリース速度低下
OSやミドルウェアのバージョンアップを行わない方針の場合、安定運用の名の下にインフラの構成は変更されず、インフラは塩漬けされます。いったん塩漬けされるとベンダー製品のライフサイクル終了までずっとそのバージョンで使い続けることになります。2021年12月に発見されたlog4jの深刻な脆弱性といった対応が必須な場合のみ、パッチ適用作業が行われます。
インフラが塩漬けされると、エンドユーザーに提供する価値向上や運用作業の負荷低減といった目的での改善は行われにくくなります。最適ではなくなった処理方式やインフラ構成が足かせとなり、エンドユーザーからの要求の変化に迅速に対応できません。従来のウォーターフォール開発では、要件変更という扱いで追加予算を取り、別プロジェクトとして対応してきました。しかし、それでは組織内の予算承認から新機能リリースまでどうしてもリードタイムがかかってしまいます。
● 技術者のエンゲージメントや生産性の低下
「最適ではなくなった」インフラの保守・運用作業は、しだいに属人化していきます。また、塩漬けされたインフラを保守できる技術者は次第に高齢化します。技術者は、新しい技術の習得に高いモチベーションで挑めますが、古い技術を学びたがる人は多くないでしょう。
仮に保守・運用作業の要員が新しく参加したとしても、古い技術を一から勉強しなくてはならない場合、時間がかかります。本来学ぶべき技術、学びたい技術に時間をかけられず、インフラチームの生産性が低下します。
技術的負債を解消するSREの考え方
それでは、技術的負債を作らないようにするにはどうすればよいのでしょうか。
前述した、本稿における技術的負債の定義は、「設計時は最適とされた設計が、時間の経過により最適ではなくなったもの」でした。
つまり、設計時点でどんなに最適なアーキテクチャを設計したとしても、一度プロダクトをリリースすれば、プロダクトすべてが技術的負債になり得ます。「最適な設計の変化」に適応するには、技術の進歩や外部環境の変化に追随していくしか方法はありません。そのためには、インフラを含めた継続的な改善として、DevOpsの実践が必須です。
ウォーターフォール開発では、開発チームと運用チームが分かれており、期限内にリリース、障害発生0といった別々の目標で各チームが活動することが多いでしょう。しかし、リリース後に継続的な改善を実践するには開発チームと運用チームの壁を壊し、1つの目標に向かって活動しなければなりません。その実践方法の1つが本節で解説するSite Reliability Engineering(SRE)です。
SREとは?
SREとは、Google社が提唱した概念/方法論です。2016 年に『Site Reliability Engineering』という書籍がGoogle社のエンジニアによって執筆されました注3。Google Cloudの公式サイトでは、以下のようにSREが定義されています注4。
Site Reliability Engineering(SRE)は、運用上の問題をソフトウェア的に解決するためのエンジニアリングであり、Google におけるエンジニアリングの本質的な部分を占めています。
SREは考え方であり、一連のプラクティスやメトリクスであり、システムの信頼性を保証するための処方箋でもあります。SREのモデルを構築すれば、サービスの信頼性が向上し、運用コストが下がり、人間が行う作業の価値が高くなって、サービスとチームの双方で大きなメリットが得られます。
障害に対する考え方と目標の定量化
SREを実践するためには、「本番環境の障害=徹底的に排除すべき悪者」ではなく、「本番環境の障害=許容範囲内でコントロールすべきもの」という考えにまず改めなければなりません。
具体的には、プロダクトに応じてService level indicators(SLI)を定義します。たとえば、障害発生件数、正常レスポンス率、システム稼働率などが挙げられます。このSLIは、エンドユーザーやビジネス側の視点で検討することがポイントです。SLIを定義したうえで、Service Level Objectives(SLO)としてSLIの目標値を設定します。たとえば、SLOとして正常レスポンス率96.5%としたとき(図2)、残りの3.5%は異常なレスポンスをエンドユーザーに返す(プロダクトをエンドユーザーが利用できない)ことを許容するのです。この割合をエラーバジェットとよびます。
エンドユーザーがプロダクトを利用できない割合がエラーバジェットを超えていなければ、チームは新機能のリリースに注力します。しかし、エンドユーザーがプロダクトを利用できない割合がエラーバジェットを超えていればプロダクトの安定運用に注力します。エンドユーザーがプロダクトを3.5%利用できないことを受容することで、SLOの達成度合いをもとにプロダクトの継続的な改善を行います。
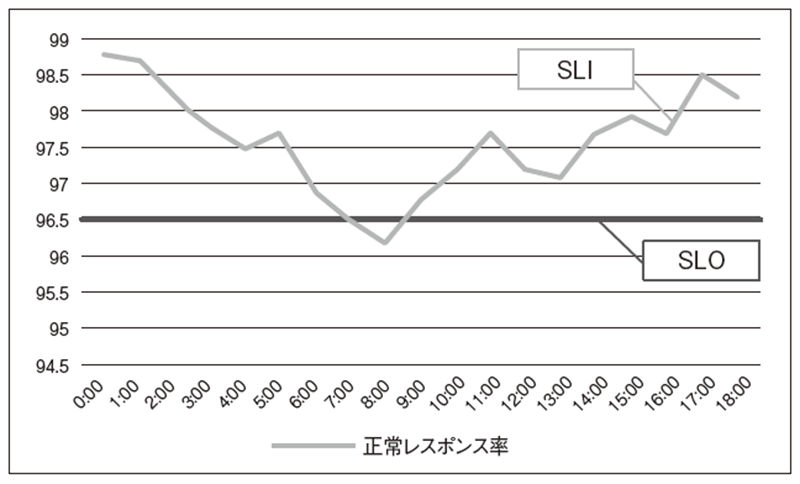
図2 SLIとSLOの例
誰がSREを実践するか?
SREにおける、開発と運用の壁を壊す(組織のサイロを削減する)考えや、障害は発生するものであるという前提はDevOpsの思想・概念に非常に近いものです。DevOpsと何が違うのかと疑問に思った方もいるかもしれません。Google社は、DevOpsとSREの違いを次のように表現しています注5。
class SRE implements interface DevOps
直訳すると、「クラスSREは、インターフェースDevOpsの実装である」という文です。DevOpsは思想や概念であり、DevOpsの具体的な実践方法の1つがSREといえそうです。アジャイル開発を採用しDevOpsを実践中の組織は、SREを導入しやすいかと思います。
また、第7回(本誌2021年6月号)では、「インフラは、特定のインフラエンジニアだけの仕事ではなく、スクラムチームが自分事として考えないといけない重要なテーマなのです」とお伝えしました。そのため、SREを実践するためには、インフラエンジニアを集めて個別にインフラチームを立ち上げる(開発チームとインフラチームを分ける)のではなく、現在のスクラムチーム全体でSREを実践することを推奨します。
プロダクトのSLOを担保するためには、アプリケーションからインフラまでの幅広い知識、経験が必要となります。しかしチームの状況によっては、インフラエンジニアの増員が必要かもしれません。アプリケーションに特化したチームだとインフラまで手が回らないかもしれません。
そのような状況を打破するために、ここからはインフラを含めて開発と運用を同時並行するためのポイントやSRE実践を下支えする技術、ツールについて紹介します。
開発と運用を同時並行するためのトイル削減
開発と運用を同時並行して実施するために、Google社ではチームの運用作業を50%以内に抑えるという目標を設けているそうです注6。残りの50%の時間は、新機能リリースやプロダクトのスケーリング、自動化の実装など開発の作業に割り当てます。運用作業を削減するためには、退屈な手作業(トイル)を徹底的に自動化します。運用作業が50%を超えたら、運用作業の削減を第一に改善計画を立案します。
しかし、作業頻度の少ないタスクの自動化は難しい場合もあるでしょう。また、再度同じタスクを行うころには、自動化したときの手順や前提が変化している可能性があります。このようなトイルに多大な時間を費やしている場合は、システムアーキテクチャを変更することでトイルを減らせないか検討しましょう。
たとえば、Amazon Web Servicesなどのパブリッククラウドベンダーが提供しているマネージドサービスを利用できないかなどです。各パブリッククラウドベンダーは毎年新しいサービスを提供しています。サービスのアップデートに個人で追随していくことは非常に大変ですが、チーム内で勉強会を開催したり、社内外のコミュニティを活用したりするなど工夫して効率良く実践しましょう。
トイル削減に資する技術とCI/CDの活用
SREは、運用上の問題をソフトウェアエンジニアリングで解決することであり、運用作業の割合を抑える必要があることから、インフラを含めたCI/CDの導入は必須と言えるでしょう。CI/CDの導入には、IaCが前提となります。サーバ台数や環境の数が増えれば増えるほど、IaCによる自動化が構築工数の削減に寄与します。
その一方で、先述したようにGoogle検索では、IaCについてネガティブなキーワードがサジェストされる現状もあります。チームが疲弊せず、モチベーションを維持しつつインフラを含めたCI/CDを実現するために、Kubernetes Nativeな技術の採用が重要なポイントの1つです。
Kubernetes(K8s)は一般的に学習コストが高いと言われていますが、第2回(本誌2021年1月号)で紹介したとおり、アジャイル開発の大規模化を下支えする技術として有用であり、K8sのコンテナオーケストレーション機能による自律的なシステム運用がトイル削減に寄与するため、学習コストをかける価値はあると思います。
チームを疲弊させないCI/CDを実現するために、Kubernetes Nativeな技術がなぜ必要かと言うと、K8sがインフラレイヤのリソースを抽象化してくれるからです。インフラを含めたCI/CDを実現するためには、アプリケーションレイヤだけでなく、ミドルウェアレイヤとクラウドリソースレイヤの検討が必要です。たとえば、warファイルのデプロイ・アンデプロイ時にTomcatを再起動するようにパイプラインを組んだり、TomcatのDB設定ファイルを差し替えたりする場合、作業をどう自動化するか検討する必要があります。
K8sを活用することで、これらのリソースはK8sのリソース定義ファイル(K8sのマニフェスト)に抽象化され、CI部分はコンテナ、CDはコンテナとK8sのマニフェストに集約されます(図3)。クラウドリソースのすべてがK8sのマニフェストに集約されるとは言い切れませんが、従来より検討対象が減り、CI/CDが簡単に実現できます。今まではJenkinsのようなCIツールでパイプラインを組み、コンテナイメージのビルド、テスト、デプロイを自動化することが多かったと思いますが、最近はGitOpsというしくみが取り入れられ始め、CIツールによる自動化はCIのみに集中し、GitOpsツールがCDの自動化を担うようになってきています。
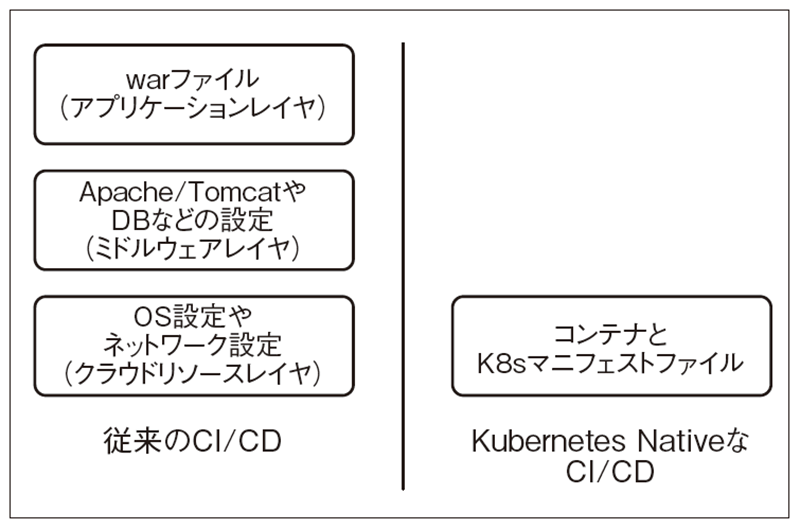
図3 従来のCI/CDとKubernetes NativeなCI/CD
GitOpsとは?
GitLab社では、GitOpsを次のとおり定義しています注7。GitOpsは、バージョン管理、コラボレーション、コンプライアンス、CI/CDなど、アプリケーション開発で使われているDevOpsのベストプラクティスを、インフラの自動化に適用した運用フレームワークです。
GitOpsによるCI/CD(図4)では、Jenkins などのCI ツールがCI を行い、ArgoCDなどのGitOpsツールがCDを行います。開発メンバーによるGitへのソースコードのPush(またはマージの承認)をトリガーにCIツールがコンテナイメージのビルドを行い、コンテナレジストリにコンテナイメージをPushします。この一連のパイプラインにソースコードの静的解析や単体テストを組み込む場合もあります。
GitOpsツールは、Gitリポジトリ上のK8sマニフェストとK8sクラスタ上のK8sマニフェストを定期的に確認し、差分を検知すれば、Gitリポジトリ上のK8sマニフェストを「正」として同期させます。たとえば、開発メンバーがGitリポジトリ上のK8sマニフェストを更新した場合、GitOpsツールがK8sクラスタ上のK8sマニフェストとの差分を検知し、Gitリポジトリ上のK8sマニフェストをK8sクラスタにリリースします。コンテナイメージがバージョンアップされていれば、コンテナイメージもK8sクラスタにリリースします。
ソースコードのビルドやアプリケーションのリリースに関する人手の作業がGit操作で完結するため、運用者がkubectl apply -fmanifest.yamlといったK8sクラスタの操作方法を学習したり、手順書を用意したりする必要がありません。
何よりのGitOps導入メリットは、SRE実践に必要なトイル削減と親和性が高いことです。
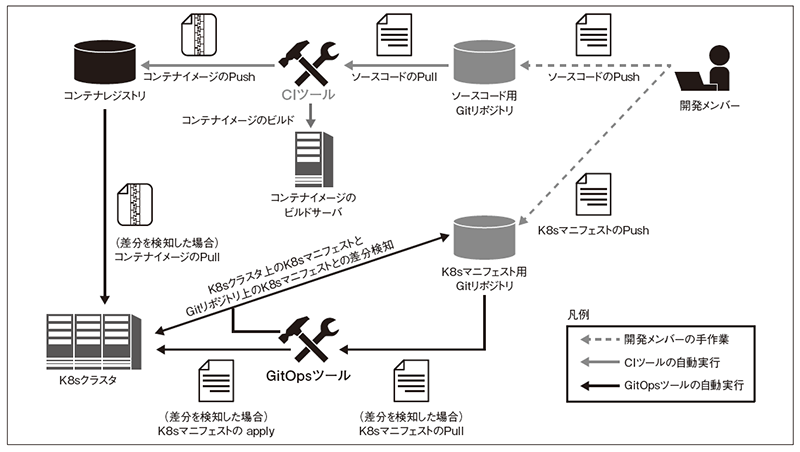
図4 GitOpsを導入したCI/CDの全体像
トイル削減とGitOpsの親和性
● 複雑性の回避
アプリケーションのデプロイ先は、本番環境だけではなく、性能試験をするための環境や機能試験をするための環境など複数の環境にデプロイする必要があります。この場合、JenkinsなどのCIツールのみでCI/CDを設定しようとすると設定が複雑になりがちです。たとえば、特定ブランチへのpushをトリガーにビルド、試験、デプロイするパイプラインを環境ごとに用意する必要があります。また、環境が増えるほどメンテナンスが大変です。
一方、GitOpsでは、各環境のGitOpsツールが対象のGitリポジトリを監視するよう設定すればよいので簡単です。しかも、GitOpsでは、複数環境にデプロイが必要でもGitリポジトリは1つで済みます。
また、K8sマニフェストに環境差分が発生する場合でも、Kustomizeというツールを使うことで、ベースとなるマニフェストと、そのマニフェストに対する環境差分を簡単にGit上で管理できます。CIツールのメンテナンス、環境差分の管理といったトイルが従来のCI/CDに比べ低減されます。
● Single Source of Truthの実現
Single Source of Truthとは、直訳すると「信頼できる唯一の情報源」のことです。GitOpsでは、K8sのマニフェストをGitリポジトリで管理します。このGitリポジトリで管理されたK8sマニフェストが「Single Source of Truth」です。図4に示したとおり、GitOpsツールが、Gitリポジトリ上のK8sマニフェストとK8sクラスタ上のK8sマニフェストの差分をチェックし、差分を検知すれば自動で同期させます。
このため、運用作業の一部をGitOpsツールが自動で実行してくれます。たとえば、K8sクラスタ上のK8sマニフェストやコンテナイメージが破損したとしても、Gitリポジトリ上にSingle Source of TruthのK8sマニフェストが存在するため、GitOpsツールが自動復旧してくれます。
また、IaCを導入済みの環境で自動構築したリソースに対し、一時的に手作業で修正を行い元に戻し忘れたという経験はないでしょうか。IaCが導入された環境では、いわゆるConfiguration Drift(構成の逸脱)と呼ばれるものが人為的ミスで発生する恐れがあります。しかし、GitOpsツールでは、Gitリポジトリ上のマニフェストと環境を常に同期させるため、Configuration Driftを防止できます。
K8sはコンテナオーケストレーション機能を持ち、自律性の高いプラットフォームですが、GitOpsのしくみを導入することでさらに自律的な運用が可能になります。各レイヤのリソースがK8sで抽象化され、CI/CD対象のリソースが減るため、運用作業の量を一定に抑える効果があります。
おわりに
インフラは、プロダクトの非機能要件を実現する重要な要素です。本稿では、インフラを含めたDevOpsを実践するための方法論(SRE)や技術・ツール(K8s、GitOps)を説明しました。
しかし、非機能要求はプロダクトの機能要求とは違い、Minimum Viable Product(MVP)の定義が難しいとされています。これは、非機能要求の分割の難しさと非機能要件の多さに起因するものです。たとえば、誰がいつ何のデータにアクセスしたかの監査ログを1年間保存するというセキュリティ要件に対し、何か問題が起きたときに、誰がいつその監査ログをチェックするか、という運用要件も関わってきます。
また、IPA発行の「非機能要求グレード」注8で定義された非機能要件は200を超える重厚長大なものです。残念ながら、アジャイル開発を前提とした非機能要求グレード相当のものは世の中に広く普及していません。だからこそインフラを含めた真のDevOpsを実現するには、方法論と技術・ツールだけでなくプロダクトオーナーやステークホルダとの対話も重要です。
※図は技術評論社の許諾を得て掲載しています。
- 注1)本稿執筆時の2021年12月時点の検索結果。
- 注2)Ward Cunningham, "The WyCash Portfolio Management System", OOPSLA '92 Experience Report, March 26, 1992
- 注3)Betsy Beyer, Chris Jones, Jennifer Petoff, Niall Richard Murphy 編、澤田 武男、関根 達夫、細川 一茂、矢吹 大輔 監訳、Sky株式会社 玉川 竜司 訳、オライリー・ジャパン、2017年8月
- 注4)https://cloud.google.com/blog/ja/products/gcp/howto-start-and-assess-your-sre-journey
- 注5)https://sre.google/workbook/how-sre-relates/
- 注6)https://cloud.google.com/blog/ja/products/gcp/identifying-and-tracking-toil-using-sre-principles
- 注7)https://www.gitlab.jp/blog/2020/09/03/is-gitops-thenext-big-thing-in-automation/
- 注8)https://www.ipa.go.jp/sec/softwareengineering/std/ent03-b.html