
















続・AI入門 第2回 AIリスクとその対策を考えてみよう
1. はじめに
人工知能(AI)技術が日々進化しています。情報通信社会=デジタル社会において、この技術を利活用するメリットは計り知れません。さまざまな業務の効率化・自律的な推進に寄与し、我々人間をサポートしているからです。ただし、この技術の利活用には注意する点があります。本コラムではこのAI技術を利活用する際の注意点、“AIリスク(AIの利用・運用・出力に伴って生じる情報管理、品質、コスト等の問題)”について考えてみたいと思います。
2. AIリスク「学習データの取り扱い」
人工知能技術の特徴は、一言で言えば「経験に基づく予測」です。過去のさまざまな出来事をデジタルデータとして蓄積し、その膨大なデータからある特徴を見つけ出し、その特徴に基づいて未来を予測します。天気予報業務などが分かりやすい例となります。また、人間との対話においても、膨大な過去の会話データから、即座に受け答えを推測し、言葉を選んで出力します。また出力の音声化においても、最適なイントネーションを含めた流ちょうな音声を予測し、出力することが可能です。
従って、“AIリスク”というと、第一には、この膨大な「学習のためのデータ」について注意を払う必要がある点が挙げられることになります。この学習データの中に、注意を払う必要があるデータが含まれていると、人工知能の予測結果にも、このデータやデータの特徴が含まれてくる可能性があるからです。例えば、企業にとっての機密情報や、あるいは個人情報が含まれていないか?他者の著作権が含まれていないか?また、反社会的な情報が偏って蓄積されていないか?などとなります。これらのデータが含まれていると、情報漏洩事故や著作権の侵害、社会的扇動などの原因を作ってしまうことになるからです。
人工知能技術の発展には、この膨大な学習のためのデータが実は大きく寄与してきました。人間で言ってみれば、経験・知見が豊富な人ほど的確な未来予測や判断を成し遂げられることと同等です。従って、注意を払う必要のある機密情報、個人情報やさまざまな社会的な意見を、AIリスクを考えて学習データから除外するのではなく、積極的に取り込むことが、利活用の幅を広げることにもつながります。ただし、そのままでよいわけではなく、適法性・本人保護・目的限定・安全管理が前提で、匿名加工・仮名加工・統計化などの工夫が必要となるような倫理的な観点にも配慮する必要があるため、利活用に特化するだけではなく、幅広くその必要性を考えてみる必要があります。
例えば、生活習慣病について考えてみると、個人情報を除いた診断結果だけでは、その病気の特徴を捕まえ難くなります。しかし、患者の方がどのように生活してきたか?性別や年齢だけでなく住所や職業などさまざまなデータが組み合わさることにより、その病気の特徴を深く捕まえることが可能となります。つまり、将来の生活習慣病に罹患する人数を抑え込むことにつながるような社会的意義を見出すこともできるようになります。この議論については、個人情報保護法に一石を投じており、利活用と人権保護などの社会的なコンセンサスとのバランスが重要となります。
人工知能の高度な予測に寄与する膨大な学習データを可能な限り用意し、そのデータをどう保護していくかを考えることがAIリスクへの対応策となるのです。
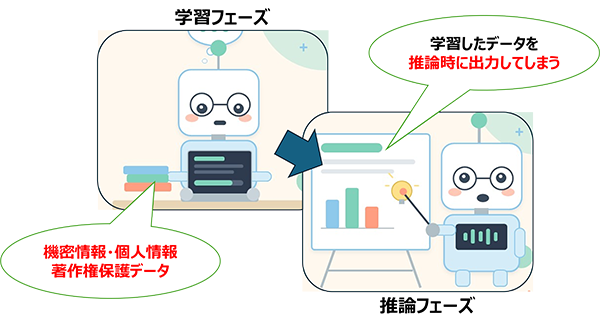
AIリスク:学習データの取り扱い
3. 具体的なリスク対策
現在の人工知能技術の活用に際しては、手元で初めから巨大なニューラルネットを組み上げ、膨大な学習データを用意して、ニューラルネットを学習させ、推論に用いることは現実的ではありません。莫大な費用が掛かるため、ChatGPTやGemini、Claudeなどをはじめ、一部の企業が提供する人工知能サービスを利用することになります。これらのサービスについては、ある程度のAIリスクの考え方が浸透しており、各サービスの提供形態にもよりますが、例えば有料で提供されるサービスでは、人工知能による予測結果を出力した際における入力したデータを、学習済み人工知能への再学習には使わないとの取り決めがあるサービスがあります。利活用に際しては、「サービスごとの利用規約・データ利用条件の確認が必要」であり、取り決めをしっかりと把握する必要があるとともに、技術の更新も頻繁に行われるため、取り決めについては利用時に逐次確認することが求められます。
また著作権についても、著作権を持つ個人団体との取り決めがなされているところや、著作権データを自動で照合し、入力させない機能を持つサービスもあります。さらに、社会的なデータの偏向(バイアス)についても、国際的なAIガバナンス基準に沿った評価を受け、対策を講じるなどの防止措置が取られているものもあります。
従って、利用する人工知能サービスの取り決めについては、逐次しっかりと把握することが大事になります。またシステム的な観点としては、オンプレミスなどによる閉じた基盤環境での利活用も対策として有効となります。
4. もう一つのAIリスク「ハルシネーション」
よく言われているように、AIはもっともらしいが不正確な出力を生成することがあります。これは現在の人工知能技術の基本となるニューラルネットのディープラーニングに基づく現象であり、何らかの算出結果を統計処理で出力することによるものです。つまり、例えば人工知能が学習していないデータについても、「分かりません」と言うことはなく、(適当に)答えを出してしまいます。学習データが膨大になるにしたがって、学習していないデータが少なくなるので、ハルシネーションは少なくなると考えられますが、人類の知識は時とともに増え続けるので、ハルシネーションが完全になくなることはありません。
このハルシネーションの対策としては、RAG技術(あらかじめ正確に決められたデータを参照する仕組み)を使うか、あるいは人工知能の結果を今一度、検証する作業を織り込むことで対策としての可能性を高めることができます。もちろん、この検証をさらに人工知能自身で実施することも考えられています。
それでも検証から漏れる場合があると考えられるので、人工知能サービスを利用する場合には、ハルシネーションを取り除ききれないと、利活用者全員で認識をすることが必要となります。
5. さらにもう一つのAIリスク「利用料金」
人工知能サービスは、一部のサービス提供者を利用することが前提となることは前述しました。その際には利用料金が掛かることになります。昨今、この利用料金が大きな問題となってきています。当初、サービス提供者は利用価値の浸透を目的に、無料開放を進めていましたが、やがて営利目的の企業向けに有料サービスを始め、価値を認めた利用者が、更なる高度なサービス利用を要求するに従い、その高額な費用が顕在化してきています。これは、高度な推論の要求になるほど、プロンプトのトークン(AIが文章を処理するための最小単位(文字や単語の断片))数が増え、それぞれのトークンの相関関係より推論計算が実施されることに起因するものです。これにより推論コストが大幅に増えていく構造になっているのです。したがって、この構造を理解した上で、トークン数を制限するなどの対策が必要になってきます。プロンプトの書き方も工夫するとともに、もし高額になった場合には途中で計算を止めるなどサービスを利用することで対処する必要があります。

AIリスク:ハルシネーションとサービス利用料金
6. まとめ
これまでAIリスクとその対策について述べました。再掲すると以下を考えることが必要となります。
- 1.膨大な学習データの保護(機密情報・個人情報・著作権情報)方策
- 2.ハルシネーションの理解と利用者全員による認識
- 3.利用料金の構造把握
学習データについては、入力してよい情報/ダメな情報を確認すること、ハルシネーションについては、何らかの別観点で確認すること、 利用料金についてサービス利用時のコスト管理ルールなどを設けることなどが必要になります。
人工知能の利活用はこれからのデジタル社会には必須の技術となりますが、そのためにはメリットと共に、しっかりとデメリットをヘッジしながらの利活用が重要となります。人工知能の構造をよく理解した上でリスク対処を行い、メリットを十分に生かすことが肝心となります。
AI利活用の際の機密データの漏洩リスクに対して、ZDR(Zero Data Retention)契約という仕組みがOpenAIやAnthropicなどのAIサービス会社より提供されています。これは、プロンプト等の推論入力データに対して、再学習に使わないだけでなく、サーバー内に一切保存しないという契約です。AIサービス提供者としては、不正利用の検知やサービス改善のために入力データをある一定期間保存しておく措置が取られていますが、ZDR契約においては、入力データはどこにも保存されることなくGPU上に展開され、推論結果が出力される仕組みになります。これにより、情報漏洩のリスクを大きく下げることができます。AIサービスを利用する際は、サービスを提供している会社に問い合わせてください。
- ※文中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。