
















続・AI入門 第1回 生成AIの仕組みを知ろう
1. はじめに
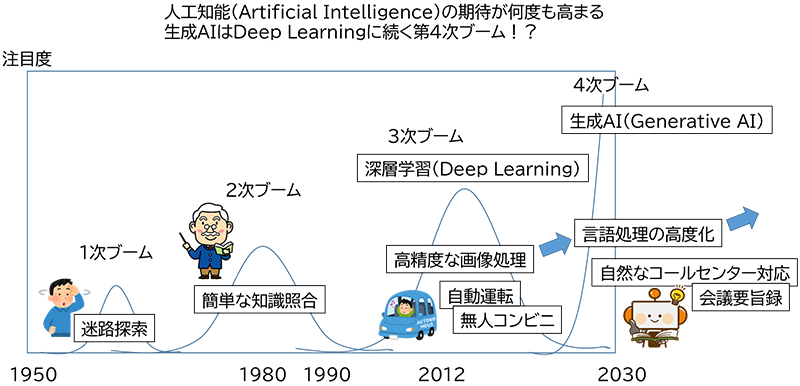
2018~2019年に、本コラムの旧シリーズとなる全5回のAI入門コラムを書かせていただきました。それ以降、この人工知能に関しては、皆さんもご存じの通り、2022年の中旬以降に大きな進展がありました。当時のコラムでは深層学習(Deep Learning)は人工知能の3次ブームだ!という表現をしましたが、今回解説する生成AI(Generative AI)は、さらに第3.5次ブームとか、第4次ブームともいわれるほどの大きな進展です。この技術は進展が速く、本コラムはすぐに陳腐化してしまうかもしれませんが、できるだけ普遍的な基礎理解のための続編の位置付けとして投稿します。既に沢山の解説記事や書籍が存在しますが、私なりの視点で生成AIについて、分かりやすく解説してみたいと思います。今回も数式は使いませんので、ご安心を。
2. 人工知能への期待と挑戦
さて、深層学習(Deep Learning)で代表される人工知能の第3次ブームが進展するにつれ、世の中には様々な活用例が出てきました。代表的なものは自動運転や、無人コンビニや監視カメラによる人物特定や行動解析などの画像処理が主なものです。それまでの検出精度を高めて、様々な画像認識が可能になり、作業の効率化、省人化が進んでいます。そのような中、少しずつですが音声認識における、高精度化の挑戦が始まりました。これまでにもApple SiriやGoogle Home、Amazon Echoなどの実用化例がありましたが、ほぼ単語命令に対応するというような低い精度でしたので、活用範囲が狭かったようです。そこで、高精度化によって会議の議事録を自動作成したいとか、コールセンターの自然な受け答えを自動でできないか?などへの活用の挑戦が進められました。
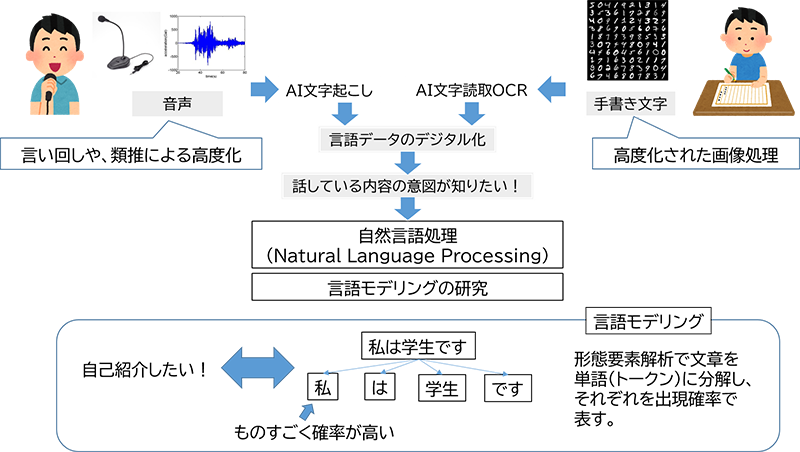
音声認識の方法は、マイクなどで取り込んだ音波波形から、何の音(「あ」とか「い」とか単音節という)が出ているのか?を認識することが始まりとなります。人間も、この音波を耳の鼓膜でキャッチして脳に伝えますね。しかし、周囲の雑音や、雑音がなくてもそれぞれの人の話し方や、前後の音との重なり具合などで、場合によっては「え?」「何?」というような聴きづらいことがあります。これを手助けするには音波波形だけではなく、慣用句などよく使われる言葉や言い回し、あるいは文法知識などを参考に、発音を類推すると認識精度が上がりますね。音声が聴き取りづらくても、こんなことを言っているんだろうなという感じで言葉を認識している場面です。特に外国語などを耳にすると、音だけでなく想像力を働かせて、何を話しているのかを理解しようとしますよね。アレです。このようにして音声を識別することが出来れば、音声波形と想像力から高精度な文字起こしが可能になりますね。文字起こしが出来ればテキストデータとなり、例えば打ち合わせのメモなどが作成できたり、コンピュータに動作命令を下したりすることができるようになります。
ここまでくると、単にどんな発音があったのかではなく、話の中身を認識したくなります。何の話?なのか、話されている内容の“意図を読み取る”(本当は“意味を理解する”と言いたいのですが、言い過ぎの感がある)ことで、返答できるようにしたい、また話されている内容を別の言語に置き換える機械翻訳がしたい。音声認識技術に対する要求がどんどん高まっていきました。
この要求に応えるために、自然言語処理(Neural Language Processing)技術の研究が進みました。人間が話す言葉のモデルをあらかじめ用意しておき、話されている内容と照らし合わせて、その言葉の“意図を読み取る”ことを目指し、言語モデリング(Language modeling)が研究されるようになったのです。
3. 自然言語処理の研究
言語モデリングとは、人が、ある意図を持って言葉を話す時に、どう話すか?をモデル化するもので、分かりやすく言うと、はじめの言葉に続いて、次に続く言葉の出てくる確率を次々と定義し、“意図を伝える言葉の連なり”をモデルで表現するものです。例えば、自己紹介の意図を持って話す場合には、まず「私」という言葉が高い確率で出てきて、次には「は」「が」「も」などが高い確率を持つ言葉となります。さらに次に続く言葉として、例えば「男性です」とかが高い確率を持って続くことになります。また状況を伝えたいときには「お腹が空いています」などの言葉が続くことになります。言語モデルとは、意図と言葉の出現確率を定義したモデルとなります。もちろん出現確率は言語文法にも沿っています。
しかし、人間が自然に話す際の「意図」も「言葉」も多様で、その伝え方のパターンは千差万別。以前は代表的なモデルを人間が手作業で構築していましたが、普段の会話で使われるパターンをカバーしきれずに有効活用ができませんでした。文法あるいは構文のルールを使った様々な処理方法も考えられ、またコンピュータの性能向上に伴って大量の言語データ(例えば書籍やSNSで交わされる言葉)に基づく大規模言語モデル(LLM:Large Language Models)も登場し、なんとか「意図と言葉の出現確率の組み合わせパターン」をすべてカバーしようと試みましたが、自然で実用的な言語処理をカバーするまでには届きませんでした。
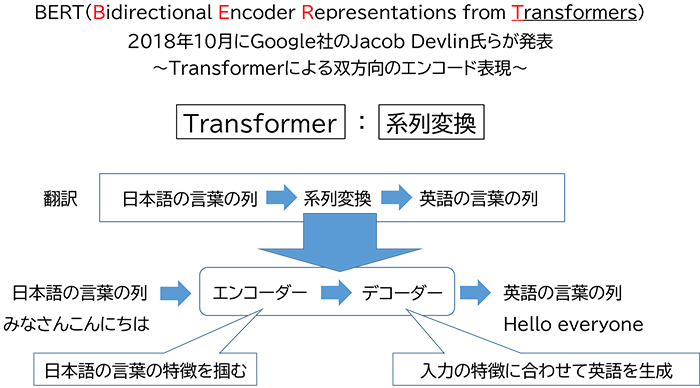
状況を一変したのは、2018年10月にGoogle社のJacob Devlin氏らが発表した研究成果になります。BERT(Bidirectional Encoder Representations from Transformers)という自然言語処理モデルの発表であり、“Transformerによる双方向のエンコード表現”と訳すことが出来ます。これだけでは、ちょっと難しいですね。どうやって高精度な言語処理を実現したのか、この技術を紐解いていきましょう。
4. Transformerによる双方向のエンコード表現
まず、Transformer って何?から始まりますが、Transformerはニューラルネットワークの一種で、“系列変換”と言って、言葉のような順に続いているもの(系列)を別の系列に置き換えていく仕組みを表しており、機械翻訳などが良い例となります。このTransformerは、当初は機械翻訳を目的として研究されていましたが、BERTやGPTなどの各種の言語処理でも広く活用されるようになり、現在のAI処理では、なくてはならない仕組みとなっています。
このTransformerはどのようにして“系列変換”をしているのでしょうか?その仕組みを見ていきます。まず中身の構造はエンコーダーとデコーダーと呼ばれる2つの部品から構成されています。初めの系列がエンコーダーに入り、エンコーダーで何らかの処理がされた信号が、デコーダーに受け渡され、別の系列に置き換えられて出力される構造となります。日本語から英語への機械翻訳の場合には、日本語がエンコーダーに入力され、何らかの処理後にデコーダーに引き渡され、デコーダーで英語に置き換えられて出力されるということになります。
では、エンコーダー、デコーダーはどんな処理をしているのでしょうか?日本語文から英語文に機械翻訳する場合を例に考えてみます。
エンコーダーの役割(入力文の特徴を掴む)
まず、入力された日本語文をトークンと呼ばれる言葉の単位に分割します(これは形態要素解析と呼ばれ、様々な手法がありますが、割と簡単にトークンに分割することが出来ます)。そして、このトークン一つ一つが、他のトークンとどれほどの強度で関係性を持っているかを、このエンコーダーで検出し、日本語文の特徴を掴むのです。難しいですね。こんな感じというところまで説明します。実はそれぞれのトークン(言葉の単位)の特徴は、数値の列(埋め込みベクトルという)で表すことが出来ます。例えば、動詞とか名詞とかを表す数値であったり、文中での出現確率でであったり、数値の列でトークンの様々な特徴を表します。列の長さが長い高次元ベクトルほど高精度にトークンの特徴が表されることになります。このトークン一つ一つの高次元ベクトルに、さらに文全体の他のトークンからの関係性の強さを(自己注意機構 self-attention mechanism という仕組みを使って)検出し、掛け合わせます。これで日本語文の特徴が、トークン一つ一つを表す、長い長い数字の列、つまり高次元ベクトルで表されることになり、これがエンコーダーの出力となります。
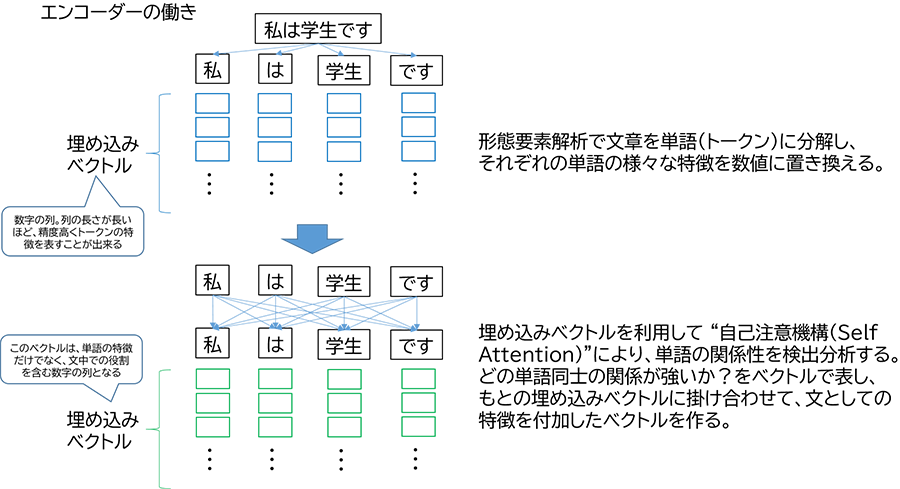
ここで、実はBERTの最初の「B(Bidirectional)」の意味が出てきます。以前の言語認識においては、出てくる言葉を順に、逐次処理を行っていて、言ってみれば一方向の処理となっていました。ところが、このBERTでは、個々のトークンを文全体(全トークン)で見渡して、その特徴を表すため、“前後双方向からの特徴を掴むことが出来る”ということで、「B」が付いているのです。
デコーダーの役割(入力文の特徴から出力文を生成する)※あ、「生成」という文字が出てきた!
エンコーダーの出力である、(日本語入力文の特徴を表した)高次元ベクトルデータから、英語文を生成します。どうやるのでしょうか?デコーダーは基本動作として、英語文となるトークンを一つ一つ順に生成します。順に一つずつ増えるトークン列の高次元ベクトルから、更に次のトークンを生成し、これを繰り返すことにより英語文を完成させていくのです。この際、エンコーダーの出力を、順に生成される英語文トークンの高次元ベクトルに掛け合わせることで、日本語文の特徴に合わせた英語文のトークン列、すなわち英語文を生成するのです。
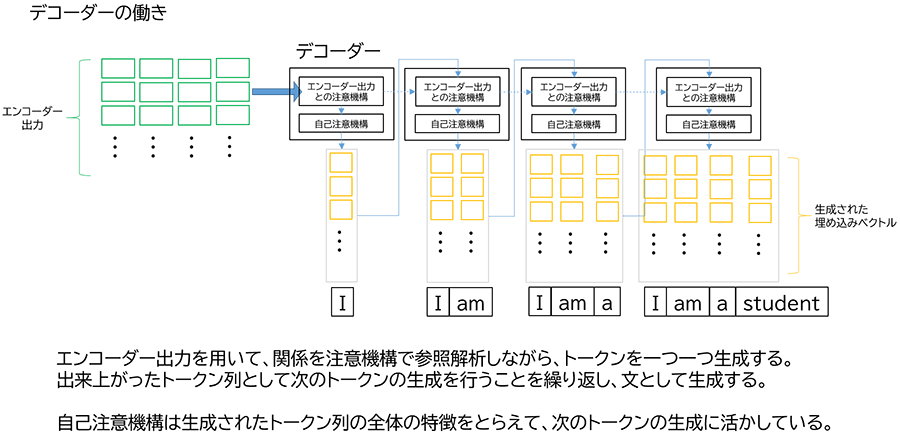
難しいですが、基本的には以下のように理解すると良いでしょう。まず、日本語文の一つ一つの単語(トークン)を高次元ベクトルで表し、さらに文全体における関係性までも高次元ベクトルに反映させ、文章としての特徴を数列に置き換える動作(エンコーダー)と、エンコーダーの出力からデコードのきっかけ(“英語に翻訳する”)を読み取った上で、最も注目されている単語(ここでは「私」=「I」)を出力し、エンコーダーの出力を参照しながら、次々と英単語をつなげていく動作(デコーダー)という流れになります。とくに、日本語文・英語文ともに“文全体”を見渡して、特徴を掴んだり生成したりするところが、今までの自然言語処理には見られない大きな特徴となります。
5. 生成AIの学習
さて、では生成AIは、どうやって学習させるのでしょうか?文章力を養うにはどうしたらよいのでしょうか?人間と同じように、まず大量の本や論文、すなわち文章を読み込むことです。生成AIは膨大な文章を読み込むことで、単語の組み合わせや文脈上のパターンを学習していきます。代表的な学習方法の一つに、BERTでも採用されている「マスク言語モデル」があります。これは、読み込んだ文章の一部の単語をランダムに隠し、その隠された部分に当てはまる単語を予測させる方法です。
例えば「友達と(隠した単語)へ行く」という文章の(隠した単語)には、正解として(買い物)、他の候補として(カフェ)や(図書館)などが挙げられたとします。このような問題を大量に解くことで、前後の文脈から適切な単語を推測する力を学習していきます。このようにして文章力を養い、ベクトル化するのです。
6. 生成AIの発展
生成AIは、はじめは言葉の翻訳として発展してきました。しかし、よく考えてみると、“系列変換”ということは、単に「異なる言語間の系列変換」と捉えるだけでなく、同一言語の系列変換、すなわちQ&Aでもよいことに気が付きます。質問文の特徴を読み取って答えを返すのでもよいのです。皆さんも情報検索に使っていることでしょう。
また、さらに考えてみると、デジタルデータの系列変換ということであれば、テキストだけでなく画像や音もデジタルデータ系列で表せるので、これを変換することも、膨大な学習をすれば可能になると類推できます。もちろんコンピュータプログラムも系列ですね。縦横無尽にデジタルデータの系列変換を考えることができます。
実は、生成AIを以上のように理解すると、活用の幅が広がります。テキストデータから画像を生成し、イラストを描かせたり音声を発生させたり、また画像データから何が映っているか説明させたりすることができます。これらはマルチモーダルと言われています。
7. おわりに
以上、生成AIの基礎的な仕組みについて述べました。少し難しかったでしょうか?興味を持たれたらさらに深く技術を学んでいただければと思います。まだまだ深く技術を追求することが可能です。
ご存じのように生成AIは、AIエージェントやPhysical AIといったキーワードとして現在も技術発展を続けており、最近では社会に大きな影響を与える存在にまで成長しています。AIコラム入門編としては、残る2回で、この生成AIを利活用する際の注意点(AIリスク)と、さらにAIを社会に浸透させるための人権問題やサステナビリティについて考えて、締めくくりたいと思います。
更新履歴
- 2024.07.04 初版
- 2026.07.06 更新
関連情報
電子情報通信学会 ジュニアWebinar ~人工知能技術とは?~
- 第1回 その歴史と原理 (外部リンク) ※動画内3番目の講演「人工知能技術とは?」をご覧ください
- 第2回 人工知能技術の活用と課題(外部リンク)
- 第3回 進展する人工知能技術(外部リンク)
- 第4回 生成AIへの道のりとその仕組み(外部リンク)
- 第5回 生成AIの課題と克服に向けて~みんなで考えよう~(外部リンク)
- 総集編 人工知能"AI"技術~人工知能技術の変遷と仕組みの概要を知る、課題を考える~(外部リンク)
- ※文中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。