















Apache Sparkで始めるお手軽リアルタイムウインドウ集計
Tweet

ソリューション事業部
ビッグデータ基盤ビジネスユニット
主任エンジニア
小山 哲平

ソリューション事業部
ビッグデータ基盤ビジネスユニット
主任エンジニア
川﨑 寛文
バッチを高速にした後はリアルタイムの世界へ!
現在、さまざまな業種の企業でビッグデータ分析の取り組みが行われている。ビッグデータへの最初の取っ掛かりは、既存のバッチ処理の高速化や、大量の業務データを用いた分析レポートの作成という企業が多いことだろう。そして、バッチ処理の高速化が一段落した次のステップとして、「リアルタイム処理」をテーマに掲げる企業も多いかと思われる。具体的には、
- 直近10秒間のトラフィックを集計したい。
- 直近10分間で自社商品がTwitterで話題になった回数を知りたい。
- 直近10時間での全店舗での来客数を集計したい。
といったリアルタイムなモニタリングを実現したくなるのではないだろうか?こういったモニタリング用の集計は、技術的には「ウインドウ集計(Time-Window Operation)」と呼ばれる。そこで本コラムでは、近頃、「ポストHadoop」として話題のApache Sparkを用いて、お手軽にリアルタイムなウインドウ集計を実現してみたので紹介する。
ウインドウ集計とは?
ウインドウ集計とは、前述した通り、「直近の一定時間の集計」を実現することである。単純に「1時間に1回、直近1時間の集計をする」というような、時間的重なりのない集計が条件であれば難易度は高くないが、「リアルタイム(毎秒、毎分)に、直近1時間の集計をする」という場合は、各集計に時間的重なりが発生する移動合計・移動平均になるため、集計の難易度が格段に上がる。 このようなウインドウ集計のイメージを下図に示す。
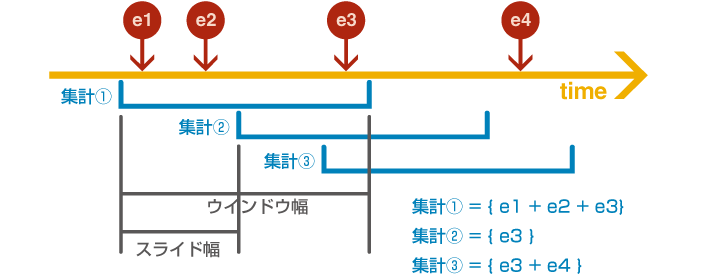
ここで、一回のウインドウ集計の集計範囲を「ウインドウ幅」、次のウインドウ集計が開始するまでの時間差を「スライド幅」として説明を進めることにする。
Apache Sparkとは?
本コラムでは、「ポストHadoop」の最右翼と言われているApache Sparkの一機能である、Spark Streamingを用いてウインドウ集計を実現する。Apache Sparkは2014年2月にApacheのトップレベル・プロジェクトに昇格すると共に、ビッグデータ分野のリーディングカンパニーであるCloudera社がサポートを開始しており、安定的な発展が見込まれている。
Apache Sparkは、Hadoopと同じく、計算処理を分散環境にて並列実行するための基盤である。RDDという独自のキャッシュ機構を持っていることが特徴であり、機械学習のような、特定のデータに対して繰り返しアクセスするような処理に対してはHadoopよりも優れているとうたわれている。
Apache Sparkには、Spark Streamingというリアルタイム処理を実現するためのフレームワークも備わっている。リアルタイム処理と言えば、2014年9月に同じくApacheトップレベル・プロジェクトに昇格したStormが有名だが、Stormとの最も大きな違いの一つは、Apache SparkにはRDDを用いたウインドウ集計がフレームワークの機能としてあらかじめ実装されていることが挙げられる。
本コラムでは、実際にそのSpark Streamingのウインドウ集計機能を試用してみる。
Twitterのツイートを集計してみる!
みなさん、ソーシャルデータの活用には興味があると思うので、本コラムではソーシャルデータに対するリアルタイムモニタリングを実現したいと思う。少し時期は逃してしまったが、「iPhone6」と一緒につぶやかれる頻度の高い単語をモニタリングするサンプルプログラムを実装してみたので、それを動かしてみる。
| 入力 | Twitter(公式API) |
|---|---|
| 出力 | 「iPhone6」が含まれるTweet中に出現する単語とその頻度 |
| ウインドウ幅 | 1時間 |
| スライド幅 | 1分 |
Apache Spark(および、サンプルプログラムを動かすための周辺ライブラリ)のインストール
まずはApache Sparkをインストールする。複数マシンでクラスタを組む場合は、Linux系のマシンを用いた方が都合は良いのだが、ここではお手軽に実行するためにWindows PC1台で実行する手順を紹介する。
- Oracle Java SEをインストールする。
一般的なため詳細な手順は割愛する。本コラムのこれ以降の手順は、「Oracle Java SE 1.6.0_45」、および、「Oracle Java SE 1.7.0_67」にて動作確認をしている。 - Apache Sparkをダウンロードする。
Apache Sparkの最新版は1.1.0だが、今回は私たちが使い慣れている1.0.2を使う。また、簡単のため、あらかじめコンパイルされている「Pre-build for CDH 4」をダウンロードして使用することにする。
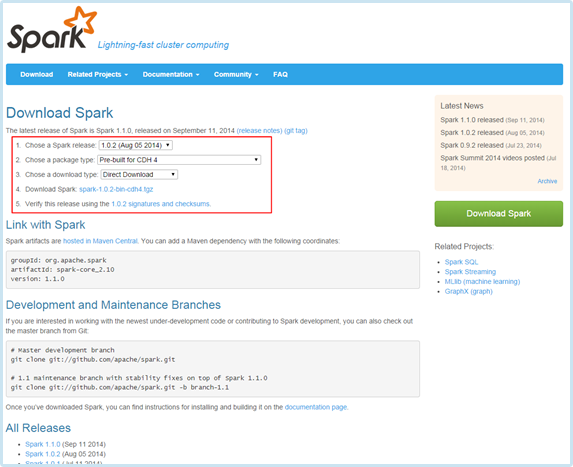
URL : https://spark.apache.org/downloads.html- ダウンロード手順1 : 「Chose a Spark release」で「1.0.2 (Aug 05 2014)」を選択。
- ダウンロード手順2 : 「Chose a package type」で「Pre-build for CDH 4」を選択。
- ダウンロード手順3 : 「spark-1.0.2-bin-cdh4.tgz」をクリックしてダウンロードする。
- ダウンロードした圧縮ファイルを展開する。
ダウンロードしたtgzファイルを展開し、任意のディレクトリへ配置する。(なお本手順では、c:\sparkとして配置する。別のディレクトリに配置した場合は、以降の手順はディレクトリ名を読み替えて作業を進めて欲しい。) - Spark-Shellを起動して、インストール成功可否を確認する。
Sparkには、Spark-Shellという、対話的にSparkを使うためのツールが備わっている。そのツールを用いて、Sparkのインストール成功可否を確認する。- インストールの確認手順1 : 「Windowsキー」+「R」を押下する。
- インストールの確認手順2 : 「cmd /c c:\spark\bin\spark-shell.cmd 2> nul」を入力し、「Enterキー」を押下する。
- インストールの確認手順3 : Sparkが起動した後に、「scala >」とコマンドプロンプトが表示されることを確認する。
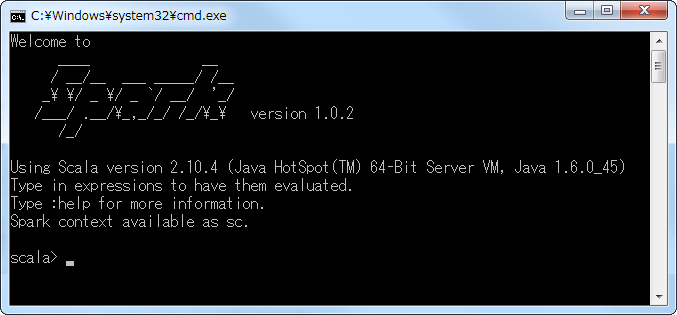
- インストールの確認手順4 : 動作確認のため、READMEの文字数をカウントしてみる。「sc.textFile("c:\\spark\\README.md").count()」を入力し、「Enterキー」を押下する。以下の出力結果のように「res0: Long = 127」等が表示されれば、正常に動作している。

- インストールの確認手順5 : 「exit」を入力後、「Enterキー」を押下し、Spark-Shellを終了する。
- 形態素解析エンジンのkuromojiをインストールする。
私たちのサンプルプログラムでは、Tweet本文を解析するため、オープンソースの形態素解析エンジンであるkuromojiを利用する。そのため、まずはkuromojiのライブラリを取得する。- 手順1: https://github.com/atilika/kuromoji/downloadsにアクセスし、kuromoji-0.7.7.zipをダウンロードする。
- 手順2: ダウンロードしたzip内に存在する、「kuromoji-0.7.7/lib/kuromoji-0.7.7.jar」を「c:\spark\lib」の中にコピーする。
- Spark Streamingで利用する外部ライブラリを設定する。
Spark-Shellは、デフォルトではSpark Streamingは利用できるが、Twitter等の外部からの入力は受け付けないため、外部入力を使用できるように設定を変更する必要がある。また、5にて配備したkuromojiもSpark Streamingから読めるように設定する必要がある。
※Linuxでは「--jars」で外部ライブラリを渡せるが、Windowsでは動作確認が取れなかったため、Spark-Shellの起動スクリプトを変更する手順となっている。- 変更手順1: 「c:\spark\bin\spark-class2.cmd」をエディタで開く。(メモ帳は不可)
- 変更手順2: 最下部から2行目の「"%RUNNER%" -cp "%CLASSPATH%" %JAVA_OPTS% %*」の上に「set CLASSPATH=%CLASSPATH%;%SPARK_HOME%\lib\spark-examples-1.0.2-hadoop2.0.0-mr1-cdh4.2.0.jar;%SPARK_HOME%\lib\kuromoji-0.7.7.jar」を追加する。(spark-examplesに、Spark Streamingの外部入力用のライブラリが含まれている。)
- 変更手順3: 保存して、エディタを閉じる。
- 再度Spark-Shellで動作確認する。
4にて設定した項目が正常に反映されていることを確認する。- インストールの確認手順1: 「Windowsキー」+「R」を押下する。
- インストールの確認手順2: 「cmd /c c:\spark\bin\spark-shell.cmd 2> nul」を入力し、「Enterキー」を押下する。
- インストールの確認手順3: 「scala >」と表示されることを確認する。
- インストールの確認手順4: 「import org.apache.spark.streaming.twitter._」を入力し、「Enterキー」を押下する。以下のように「import org.apache.spark.streaming.twitter._」とメッセージが表示されれば正常である。表示されなかった場合は、上記で実施したクラスパスの指定が誤っている可能性がある。

- インストールの確認手順5: 「import org.atilika.kuromoji._」を入力し、「Enterキー」を押下する。以下のように「import org.atilika.kuromoji._」とメッセージが表示されれば正常である。表示されなかった場合は、上記で実施したクラスパスの指定が誤っている可能性がある。

- インストールの確認手順6: 「exit」を入力後、「Enterキー」を押下し、Spark-Shellを終了する。
これでSpark Streamingのインストールは完了である。次に、リアルタイムなウインドウ集計を実際に実行してみよう。
ウインドウ集計の実行!
ウインドウ集計を実行する手順を以下に記載する。ここでは、簡単のため、Spark StreamingのスクリプトをSpark-Shellのコマンドライン上で直接実行する手順となっている。
- Spark-Shellを起動する。
以下の手順で、再度Spark-Shellを立ち上げる。- 起動手順1: 「Windowsキー」+「R」を押下する。
- 起動手順2: 「cmd /c c:\spark\bin\spark-shell.cmd 2> nul」を入力し、「Enterキー」を押下する。
- 起動手順3: 「scala >」と表示されることを確認する。
- ウインドウ集計スクリプトを実行する。
以下のScalaスクリプト内のTwitterアカウント情報を更新した上で、そのままSpark-Shellコマンドラインにコピペしてもらいたい。import org.apache.spark.streaming._ import org.apache.spark.streaming.twitter._ import org.apache.spark.streaming.StreamingContext._ import org.atilika.kuromoji._ import org.atilika.kuromoji.Tokenizer._ import java.util.regex._ // Twitterへのアクセスアカウント情報を定義する System.setProperty("twitter4j.oauth.consumerKey", "xxxxxxxxxxxxxxxxxxxxxxxxxxxx") System.setProperty("twitter4j.oauth.consumerSecret", "xxxxxxxxxxxxxxxxxxxxxxxxxxxx") System.setProperty("twitter4j.oauth.accessToken", "xxxxxxxxxxxxxxxxxxxxxxxxxxxx") System.setProperty("twitter4j.oauth.accessTokenSecret", "xxxxxxxxxxxxxxxxxxxxxxxxxxxx") // プロキシ環境の場合は、ここでプロキシの設定をする // Spark Streaming本体(Spark Streaming Context)の定義 val ssc = new StreamingContext(sc, Seconds(60)) // スライド幅60秒 // 「iPhone6」のキーワードにて検索したTwitter入力ストリーム val stream = TwitterUtils.createStream(ssc, None, Array("iPhone6")) // Twitterから取得したツイートを処理する val tweetStream = stream.flatMap(status => { val tokenizer : Tokenizer = Tokenizer.builder().build() // kuromojiの分析器 val features : scala.collection.mutable.ArrayBuffer[String] = new collection.mutable.ArrayBuffer[String]() //解析結果を保持するための入れ物 var tweetText : String = status.getText() //ツイート本文の取得 val japanese_pattern : Pattern = Pattern.compile("[¥¥u3040-¥¥u309F]+") //「ひらがなが含まれているか?」の正規表現 if(japanese_pattern.matcher(tweetText).find()) { // ひらがなが含まれているツイートのみ処理 // 不要な文字列の削除 tweetText = tweetText.replaceAll("http(s*)://(.*)/", "").replaceAll("¥¥uff57", "") // 全角の「w」は邪魔www // ツイート本文の解析 val tokens : java.util.List[Token] = tokenizer.tokenize(tweetText) // 形態素解析 val pattern : Pattern = Pattern.compile("^[a-zA-Z]+$|^[0-9]+$") //「英数字か?」の正規表現 for(index <- 0 to tokens.size()-1) { //各形態素に対して。。。 val token = tokens.get(index) val matcher : Matcher = pattern.matcher(token.getSurfaceForm()) // 文字数が3文字以上で、かつ、英数字のみではない単語を検索 if(token.getSurfaceForm().length() >= 3 && !matcher.find()) { // 条件に一致した形態素解析の結果を登録 features += (token.getSurfaceForm() + "-" + token.getAllFeatures()) } } } (features) }) // ウインドウ集計(行末の括弧の位置はコメントを入れるためです、気にしないで下さい。) val topCounts60 = tweetStream.map((_, 1) // 出現回数をカウントするために各単語に「1」を付与 ).reduceByKeyAndWindow(_+_, Seconds(60*60) // ウインドウ幅(60*60sec)に含まれる単語を集める ).map{case (topic, count) => (count, topic) // 単語の出現回数を集計 }.transform(_.sortByKey(false)) // ソート // 出力 topCounts60.foreachRDD(rdd => { // 出現回数上位20単語を取得 val topList = rdd.take(20) // コマンドラインに出力 println("¥n Popular topics in last 60*60 seconds (%s words):".format(rdd.count())) topList.foreach{case (count, tag) => println("%s (%s tweets)".format(tag, count))} }) // 定義した処理を実行するSpark Streamingを起動! ssc.start() ssc.awaitTermination() - 実行を確認する。
以下のような内容が表示されれば、ウインドウ集計が正常に動作している。終了するには、コマンドプロンプトウインドウの閉じるボタンを使用する。
# 「曲がっ」が上位にくるあたりがiPhone6ならではだろう。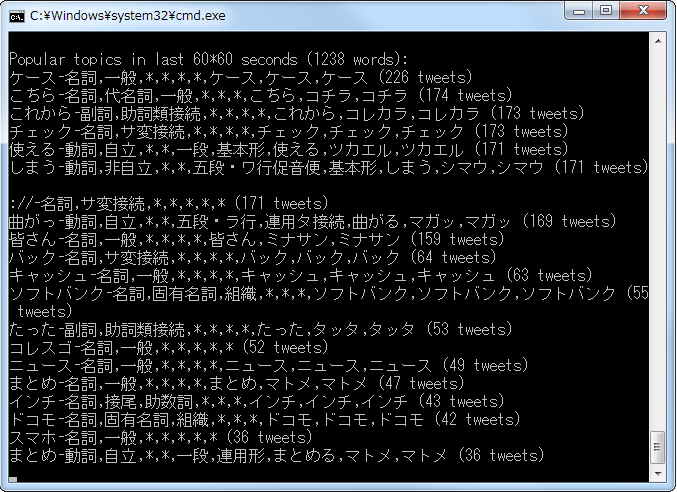
Spark Streamingのウインドウ集計の仕組み
Spark Streamingを用いて、実際にウインドウ集計の実行を試してみた。ここで、Spark Streamingが内部的にどのような仕組みでウインドウ集計を実現しているかを簡単に説明しておこう。
先ほど実行したサンプルプログラムの内部的な動作は以下の図のようになる。
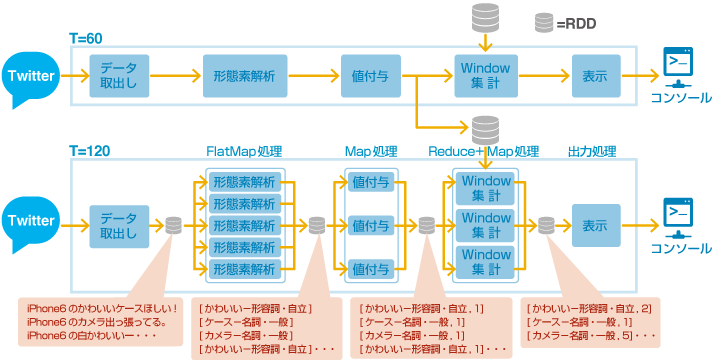
枠線で囲んだ「データ取り出し」から「表示」までの一連の処理が、一つのショートバッチ(ウインドウ集計の実行単位)となる。Spark Streamingでは、このショートバッチをスライド幅(今回は60秒)毎に起動することでリアルタイムなウインドウ集計を実現する。
ショートバッチの内部としては、まずはTwitterからデータを取り出す処理が存在する。この処理は、実際はスライド幅とは別の「batchInterval」という設定値毎に区切り、RDDに書き出す。Apache SparkはRDDのデータを変換して新しいRDDを作る処理として実装されるもので、Spark Streamingもその枠組みから外れていない。従って、これ以降の処理は、このRDDを変換していく作業となる。
Twitterから取り出したRDDに対して、次は形態素解析処理を実施する。サンプルプログラムでは、この処理についてFlatMapメソッドを利用して実現している。HadoopのMapとは異なり、SparkのMapでは、1つのMap処理あたりの出力が1つであるものはMap、複数の値を出力するものはFlatMapを利用する。形態素解析は1文あたりに複数の単語を出力するので、FlatMapを利用する。
各単語に対して、Map処理で集計用に「1」を付与した後、ウインドウ集計処理を実施する。このサンプルプログラムでは、reduceByKeyAndWindowというメソッドを用いてウインドウ幅分の単語が記録されたRDDを集め、Map処理で単語の出現回数を求めている。より複雑なロジックのウインドウ集計を実現したい場合は、定義した関数をreduceByKeyAndWindowに渡すことで実現することもできる。
最後に、takeメソッドで上位20件を切り出し、それをforeachメソッドで読み込んでコマンドラインに出力している。
実運用化を検討するためには?
本コラムでは、WindowsのPC1台を用いて、リアルタイムにウインドウ集計を実施するサンプルを実行した。SparkではRDDというキャッシュ機構があり、このRDDによって過去の情報を保持できるため、Spark の一機能であるSpark Streaming単体でウインドウ集計を実現することができた。ただ、この程度の処理量、この程度の入力データ量の場合は、Esperなどのより実績のあるフレームワークを使っても十分に対応できる。Spark Streamingはクラスタ構成を採ることができ、入力データがビッグデータとなった場合にも対応できることが利点であるので、そういった処理で試した上で、Spark Streamingの実用性を評価してもらいたい。
また、実務でリアルタイムモニタリングを用いる場合には、その技術的な問題に加えて、入力データと出力データを最初にしっかりと設計をする必要がある。「とりあえず集計してみる」では効果がなく、「このような施策を効果的に実施するためにはこのような集計が必要だ」というはっきりした目的を持つことで、その効果がより大きくなる。これは当たり前のことであるが、当たり前のことを実施することが一番難しいので、よく認識しておく必要がある。
リアルタイムモニタリングについて、どのような技術を用いたら良いのか、または、どのように役立てたら良いのか、お悩みの場合は、是非、お気軽にご相談いただきたい。
Tweet