















ブロックチェーン テクノロジーコラム 拡張性とプライバシーを備えたオフチェーンデータの管理(前編)
NTTデータ先端技術株式会社(以下、当社)は、常に最新の情報技術トレンドの最前線に立ち、2016年にはブロックチェーンと関連技術に取り組む専任チームを設立しました。 当チームでは、ブロックチェーンの世界的な最新トレンドを把握して、ブロックチェーン実装の可能性があるさまざまなユースケースを特定し、その最小実行可能製品(Minimum Viable Product: MVP)を実装することに取り組んでいます。
これまで多くのMVP実装を実行し、Ethereum、Hyperledger Fabric、R3 Cordaなど、さまざまなタイプのブロックチェーンプラットフォームにおける技術的専門知識や、「Blockchain + AI」、「Blockchain + IoT」など、テクノロジーの統合に関する技術的な専門知識を獲得しました。 また、デジタル著作権管理、ヘルスケア、サプライチェーンファイナンス、不動産資産管理など、さまざまな業界や機能向けのソリューションを実装しています。
本項では、当社が培ってきたブロックチェーンにおける技術的専門知識のうち、拡張性とプライバシーを備えたオフチェーンデータの管理手法について、前・後編に分けて解説してまいります。
(※執筆協力(敬称略):NTT Data Global Delivery Services Pvt. Ltd. (Pune) Vineet Mago, Deepak Mule)
1. 要約
ブロックチェーン・テクノロジーは、ピアツーピア (P2P) ・ネットワーク上で分散台帳を管理する方法に革命をもたらしました。これにより、すべてのネットワーク・ノードが合意メカニズムに参加してすべての元帳更新を検証し、元帳のコピーを保守できます。すべてのピアに共有元帳の同じコピーがあります。
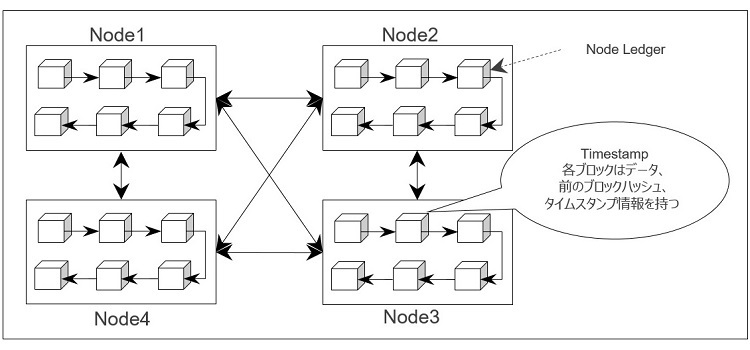
図1 ブロックチェーン - 論理ビュー
ブロックチェーン元帳では「ブロック」と呼ばれる単位で情報が管理され、新たに生成されたブロックは既存のブロックの後続ブロックとして、言わば「チェーン(鎖)」のようにつながった状態で維持されます。各ブロックにはレコード(トランザクションデータ)、アドレス(前のブロックのハッシュ)およびタイムスタンプのリストが含まれます。ブロックチェーンに保存されているデータは簡単には変更できません。必要なデータを更新し、後続のすべてのブロックを更新し、これらの更新をすべてのネットワークノードで実行する必要があります。このプロセスは数学的に非常に複雑なため、ブロックチェーンに保存されたデータを変更することは事実上不可能です。
ブロックチェーンには、従来のデータベースや分散システムに比べていくつかの利点があります。
- 1.ブロックチェーン上の元帳は、仲介者や第三者に依存することなく検証できます。
- 2.資産所有の分散記録を保持することにより、デジタル資産のコピーおよび所有権の主張を解決します。
- 3.独自の設計により、分散型元帳には、資産の移転を記録し、デジタル資産の二重支出という長年の問題を解決します。
- 4.ブロックチェーンでは、スマートコントラクトを使用して、共有資産とその移転に複雑なルールを適用し、オファーとトランスファーに関連する取引の詳細な記録を管理できます。
- 5.上記により、共有情報の透明性、効率性、セキュリティ、トレーサビリティが向上します。
上記の利点を持つブロックチェーンには、いくつかの欠点もあります。
- 1.ブロックチェーン上のすべてのデータが共有されるため、ネットワークのパフォーマンスは、ネットワーク上に高頻度の更新または大量のデータが登録されると低下します。
- 2.記録されたデータはすべて不変であるため、ブロックチェーンネットワークにすでに存在するレコードを変更または削除することはできません。
- 3.ブロックチェーンの性能は、一度にネットワークにアクセスするユーザ数と、ブロックチェーン上にトランザクションデータとしてアップロードされるデータのサイズに依存する。
- 4.一度記録されたコンテンツを削除できないというブロックチェーンの制約により、基盤となるストレージは無限に増加し、いつまでも利用可能である必要があります。
- 5.ブロックチェーンデータはすべてのノードで共有されるため、機密データやドキュメントの内容が明らかになることもあります。これは、機密文書を関係者のみが閲覧できるようにする必要があるビジネス要件には理想的ではありません。
プライバシー保護に対応したブロックチェーンソリューションの採用が増加している一方で、ブロックチェーンはドキュメントや証明書などの大きなオブジェクトを共有する際の課題に直面し続けています。これらの制限を克服するために、企業のブロックチェーンソリューションは混合モデルに移行し始めました。重要なトランザクションデータはブロックチェーンの内部ストレージメカニズムによって管理され、追加情報はオフチェーンデータとして外部ストレージまたはデータベースに記録されるほか、参照整合性を確保するために、メタデータおよびオフチェーンデータへのポインタは、ブロックチェーントランザクションの属性としてオンチェーンに記録される仕組みです。
この記事では、オフチェーンデータ管理の問題と、それに対処するためのアプローチについて、さらに詳しく解説します。
2. オフチェーンデータ・ストレージ・モデル
オフチェーンデータは、本質的に大規模な非トランザクションデータです。取り扱うデータの中には、サイズや将来的に予想される更新の頻度または削除の要件から考慮しますと、ブロックチェーンに保存するには不便なデータも存在します。このようなデータはチェーン外(オフチェーン)に保存する必要があり、必要に応じて権限のある関係者と共有します。ただし、その信頼性を確立するには、オフチェーンデータを何らかの方法でオンチェーンデータと関連付ける必要があります。
ブロックチェーンと同様に、ストレージまたはサーバリソースのネットワークを使用して、このオフチェーンデータを共有できます。このネットワークは、ブロックチェーン・コンソーシアムのメンバーとユーザーに必要なセキュリティとプライバシーを提供できるように設計する必要があります。オフチェーンデータは、一元的にアクセス可能なデータストア・メカニズムまたは分散データストア・メカニズムを使用して管理できます。
これらのアプローチの長所と短所について見ていきましょう。
2.1 オフチェーン・ストレージのタイプ
2.1.1 一元化されたデータストレージ
集中型ストレージでは、ファイルとデータはネットワークを介して共有ストレージ・サーバで管理されます。クライアントまたはユーザーは、一元化されたデータストレージに接続して、データを保存または取得します。この結果、制御の欠如や、この一元化されたデータ・ストアが利用できない場合の単一点障害の可能性に関して深刻な問題が発生します。さらに、すべてのオフチェーンデータはセントラル・リポジトリに格納されるため、プライベートアクセスおよびアクセス制御は、許可およびアクセス制御によってのみ管理できます。このモデルの例としては、クラウドストレージサービス、一元化されたデータセンターで管理されるストレージソリューションなどがあります。
2.1.2 分散データストレージ
分散データストレージでは、データストアネットワーク内のすべてのノードが共有データのコピーを保持します。これにより、データの可用性に関する単一点障害の問題が解決されます。また、関係者間でのみデータを送信できる、より複雑なピアツーピア共有モデルもサポートします。ブロックチェーンは、InterPlanetary File System (IPFS) 、Ethereum Swarm、StorJ、MaidSafe、Siaなど、さまざまなオフチェーンのデータ管理メカニズムをサポートしています(HLF、Cordaでも機能が提供されている)。
2.2 分散ストレージが推奨される理由
分散ストレージ・ネットワークは、ブロックチェーン・ソリューションと同じメリット、つまり、単一点障害のない分散制御を提供します。分散ストレージ・サービス・クライアントは、ストレージ、取得、アクセス制御操作を実行するためのAPIを提供します。使用例の要件に基づいて、これらのストレージネットワークはパブリックネットワークまたはプライベートネットワークでホストできます。
パブリック分散ネットワークでは、強力な暗号化メカニズムによって保存データの機密性を実現できます。また、コンテンツ固有の暗号化キーの共有サービスを使用して、アクセス制御を設計できます。共有サービスは、アクセス制御リストの管理や、要求されたコンテンツ暗号化キーへのアクセス権が特定のユーザーに付与されているかどうかの承認にも使用できます。
以降のセクションでは、いくつかの分散ストレージ・ネットワーク・オプションについて詳しく説明します。
2.2.1 Swarm(スウォーム)ノードクラスタ
Swarmは、ピアツーピア・プロトコルのようなビットトレントを使用して、多数のノードに分散した分散方式でデータを保存します。
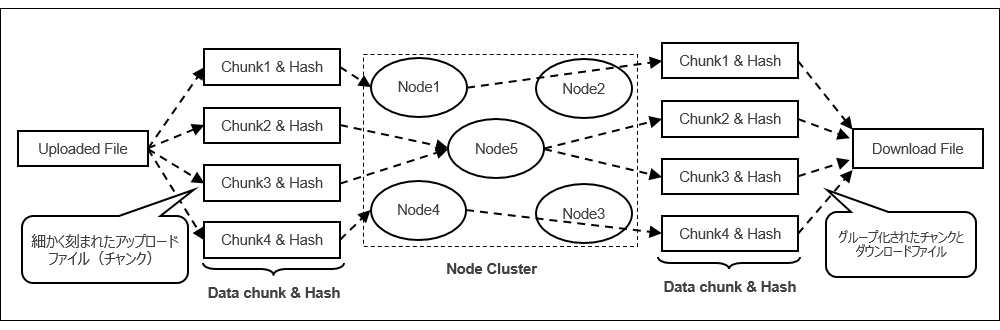
図2 Swarmノードクラスタ及びそのデータ処理機構
コンテンツがSwarmネットワークにアップロードされると、チャンクと呼ばれる均等なサイズの小さなピースに分割されます。これらのチャンクはハッシュとともにノードのクラスタ上に階層的に格納され、ダウンロード中に元のコンテンツに再びアセンブルされます。Ethereum Swarmは、プライベート・ストレージ・ネットワークとしても導入できます。Swarmは、内部暗号化メカニズムと最小限の内部アクセス制御メカニズムもサポートします。
しかし、Swarmは大規模なパブリックデータストレージネットワーク(公開されているEthereumブロックチェーンのストレージ層)用に設計されているため、その機能のいくつかはコンソーシアムベースのブロックチェーンソリューションには、あまりに複雑です。
2.2.2 IPFSクラスタ
IPFS (InterPlanetary File System)は、ファイル、データ、およびWebコンテンツを保存および共有するためのピアツーピア分散「ファイル」システムです。IPFSは、ノードのピアツーピア・ネットワークを介してデータとその参照を格納および追跡することによって、この共有サービスを提供します。また、IPFSは、アップロードされたコンテンツのハッシュアドレスブロックを1つまたは複数のノードに格納します。
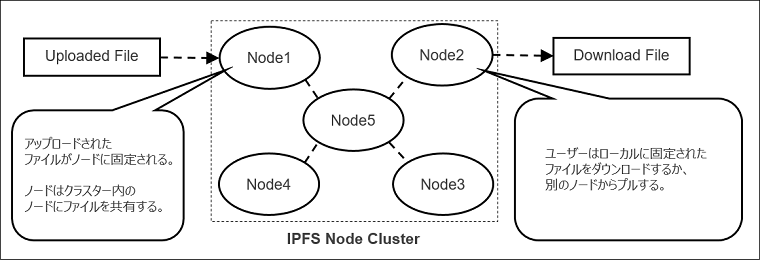
図3 IPFSノードクラスタ上のアップロードされたコンテンツとダウンロードされたコンテンツの処理
Ethereum Swarmとは異なり、IPFSは複数のノードからアクセスすることなく、アップロードされたコンテンツを提供できます。IPFSとEthereum Swarmはどちらも、ブロックチェーンネットワークをサポートし、オフチェーンデータストレージ要件を提供するように設計されています。しかし、これらのネットワークを企業のユースケースに適用するには、いくつかの課題があります。
2.3 分散データストレージの課題
2.3.1 スウォームノードクラスタ
- 1.Swarmノードクラスタはアップロードされたコンテンツを暗号化しますが、悪意のあるノードオペレータはキー推測とブルートフォース技法を試して、ローカルノードに保存されたデータを復号化できます。これにより、共有データのプライバシーが侵害される可能性があります。
- 2.現時点では、Swarmノードに格納されているデータへのアクセスを制御する効果的な方法はありません。
- 3.コンテンツハッシュに影響を与えずにコンテンツを更新することはできません。これは、コンテンツの不変性を維持するための望ましい機能ですが、特定のファイルまたはオブジェクトの論理バージョニングを維持する責任がクライアントにあることを意味します。
- 4.Swarmには、ネットワークからコンテンツを削除するメカニズムはありません。
- 5.Swarmは、ファイルやディレクトリの論理構造を保持しません。すべてのコンテンツはハッシュによってアドレス指定される必要があります。これにより、クライアントに保存されているコンテンツに名前を付けて追跡する必要が生じます。クライアントがハッシュを失うと、コンテンツの検索やアドレス指定ができなくなります。
- 6.Ethereum Swarmオープンソースプロジェクトは大幅に書き直されています。コミュニティは、libp2pプロトコルを使用してプロジェクトを再構築しており、既存の機能がすべて変更または廃棄される可能性があります。
2.3.2 IPFSクラスタ
- 1.IPFSはハッシュを使用してファイルを処理するため、同じハッシュを使用して同じファイルが参照されるため、ファイルの物理的な削除は複雑な問題となります。
- 2.デフォルトでは、IPFS上のデータは暗号化されません。通常、IPFSノードはエンドユーザに直接公開されますが、IPFSノードを管理するサーバ管理者が悪意を持って操作し、ノードに格納されている暗号化されていないデータにアクセスする可能性があります。
- 3.IPFSには、既にIPFSに格納されているファイルを更新する機能がありません。また、ファイルの変更履歴を追跡する機能もありません。ファイルの変更履歴を追跡するのは、接続されたアプリケーションの役割です。
まとめ
今回はブロックチェーン技術における、オフチェーンデータストレージや分散ストレージを中心に、その詳細や利点などについて解説しました。
後編では、こうしたオフチェーンデータの管理手法や使用例、実用的なプラットフォームについて解説します。
参考資料
-
IPFSマニュアル
https://docs.ipfs.io/ -
Ethereum Swarmに関するドキュメント
https://swarm-guide.readthedocs.io/en/latest/
- 文章中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。