
















チーム開発の視点が変わる アジャイル開発の新常識 第6回 アジャイル開発のマイクロサービス化に欠かせない可観測性
*本コラムは、技術評論社「Software Design」2021年5月号に寄稿したコラムを掲載しています。
少し間が空いてしまいましたが、今回は連載第2回「アーキテクチャから考える大規模アジャイルの最適化」の続きにあたる話をしていきたいと思います。
第2回のおさらい
第2回では、アジャイル開発の規模増加に伴いコミュニケーションが取りづらくなる問題や、特定の機能だけのスケールや更新が難しくなるという課題を提示しました。これらの課題の解決策として、1つの巨大なサービスを単独で動作可能な複数のサービスに分割し、サービスごとにチームを割り当てることでコミュニケーションコストを抑える、マイクロサービスというアーキテクチャを紹介しました。またマイクロサービスにおいて各サービスを独立してスケール・デプロイするための技術として、コンテナ技術(Docker)や、コンテナオーケストレーションツール(Kubernetes)といったツールにも触れました。
一方でマイクロサービスの採用はメリットだけではなく、トレードオフで発生する課題があることも第2回では示唆しました。
今回の記事ではマイクロサービスを採用することに伴う課題への対応方法を見ていきたいと思います。
マイクロサービスの導入により生まれる課題
マイクロサービスの導入によりどんな課題が生まれるのでしょうか。当然ですが、単純な構成であるモノリシックなアプリケーションに比べると、システム構成が複雑化します。
複雑性を生み出す要因
では、何が複雑性を生み出すのでしょうか。
1つめの理由は、ネットワーク関連の問題です。マイクロサービスではアプリケーションの機能は複数のサービスに分割され、サービス間のやりとりはネットワークを介したものになります。ネットワークを介すことで、通信失敗時のリトライ処理の検討が必要になります。
2つめの理由は、データ整合性の担保の難しさです。1回のトランザクションで複数のサービスのDBを更新するような処理があったとします。マイクロサービスのように分散されたコンポーネント間で、途中で処理が失敗したらすべてを元に戻すというようなアトミック性を担保するのは非常に難しいです。
3つめの理由は、サービスの更新の難しさです。第2回では、マイクロサービスはそれぞれのサービスを独立してデプロイ・スケールができるということを利点としてあげました。これは基本的には正しいのですが、更新対象のサービスがほかのサービスから呼び出され、かつ更新内容が破壊的な場合、独立してデプロイというのは難しくなります。
システム構成の複雑さは運用の複雑化に繋がる
前項のようにマイクロサービスを導入すると、システムとして動作させるための構成要素が非常に多くなり、これらが複雑に絡み合って動作することになります。このようなシステム構成の複雑さは運用の複雑化、とくに障害復旧の難化につながります。
従来のシステムは障害による影響を予測しやすかった
従来の一般的なモノリシックアプリケーションでの障害対応は次のようなプロセスでした(図1)。
- 想定される障害ケースで、それに伴うメトリクス(=システムの状態)の変化を予測する
- メトリクスの閾値を決めてアラートを設定する
- アラートが発生したら自動で対応できるものは自動で対応する(サーバの追加など)。人的対応が必要なものは人手で対応する
もちろんすべての障害ケースがカバーできるわけではないですが、障害に伴ってメトリクスがどのように変化するか、どのような対応を行うか検討しておくことで、ほとんどの障害ケースをカバーできました。

図1 従来のシステムでは、障害ケースとシステムへの影響を予測しやすかった
マイクロサービスは予期せぬ障害が発生する
一方でマイクロサービスのような複雑なシステム構成では、これまで予測もできなかったケースが発生することが多いです。
想定できない障害ケースにより、システムを構成するどこかのコンポーネントで障害が発生すると、何かしらのメトリクスアラートが発生するかもしれませんが、事前に決めておいたメトリクスアラートに対する対応策では解決されない可能性が高いです。
また、そもそも障害が発生したコンポーネントについて対応を行っても解決されないことがあります。システム構成内で依存関係のあるコンポーネントが存在する場合、障害が連鎖していく可能性があります。たとえばコンポーネントBでメモリ不足でアラートが発生したとして、対応としてコンポーネントBをスケールさせたとします。それでもアラートが止まることはないかもしれません。障害原因をさらに追及すると、真の原因は別のコンポーネントAで、BはAの呼び出しがタイムアウト待ちで溜まっていったためメモリ不足のアラートを発していたということも発生し得ます(図2)。
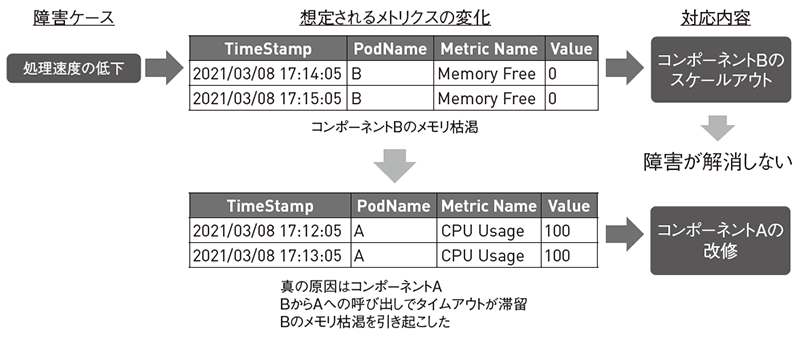
図2 マイクロサービスでは障害が連鎖し、真の原因を突き止めるのが困難
未知の障害ケースでも、メトリクス上は既知の障害ケースと同じように見えることもあるかもしれません(図3)。そこで既知の障害ケースと同じパターンの対応をとっても解決はされません。早急に障害原因を突き止めて、対策を施すことが必要になります。

図3 メトリクスの変化パターンに対して、複数の障害ケースが発生し得る
このようにマイクロサービスのような複雑なシステムでは、従来のモノリシックアプリケーションで行っていたように、障害パターンをあらかじめすべて網羅し、障害復旧パターンを整理しておくだけでは解決できない障害が多々発生します(図4)。
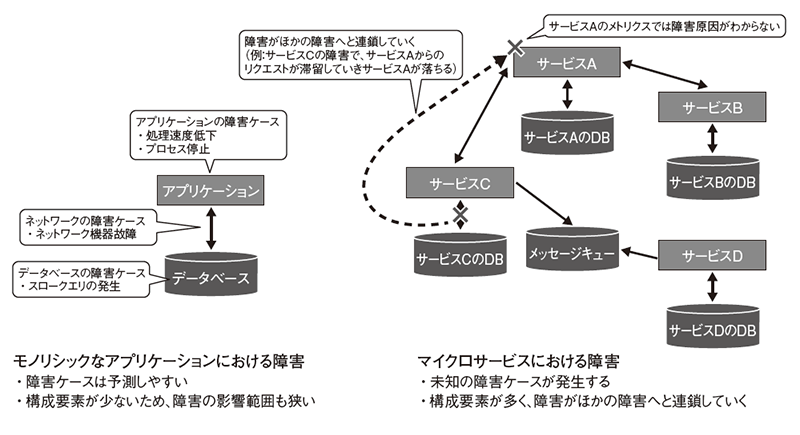
図4 モノリシックなアプリケーションとマイクロサービスにおける障害の比較
このような障害に対応するには、障害が発生したときにシステムの奥まで深く潜り、内部状態を把握・デバッグし、その場で解決策を見つけ、早急な復旧措置を取れるための方法が必要であると言えます。
可観測性とは?
ここで必要となるのは、システムが可観測性(オブザーバビリティ)を持つことです。
可観測性について、近年耳にする機会が増えてきました。定義は人によって違うことが多いですが、CNCF(Cloud Native Computing Foundation)では次のように定義しています注1。
可観測性とは、システムの状態またはステータスが外部出力からどれだけよく理解できるかを測定したものです。コンピュータシステムは、CPU時間、メモリ、ディスクスペース、遅延、エラーなどを監視することで測定できます。取得されたこれらの情報は、システムがどのようにして動作しているかを説明しますが、これらのメトリクスはユーザーによって異なる方法で解釈可能です。ユーザーは、システムの同じデータから独自の解釈を推測します。これらの解釈がより整合し、より正確であるほど、可観測性が高いと言えます。
ほとんどの制御システムと同様に、ユーザーはシステムの状態を診断したり解釈したりするのに、システムの出力を当てにしています。ユーザーがシステムの状態を解釈できない場合、インシデント中に修正措置をとることは容易ではありません。システムが動作しない時間が長いほど、ひどい損害を被ることになります。
可観測性はシステムの運用コストに大きな影響を及ぼします。可観測性のあるシステムは、ユーザーに意味のある実用的なデータを提供し、より良い結果とより少ないダウンタイムにつながります。しかし、情報が多いからといって、必ずしもシステムの可観測性が高いとは限らないことに注意してください。意思決定者は、特定の意思決定や要件に応じて情報を提供することが可能なツールやメトリクスを検討する必要があります。
この定義から、可観測性のあるシステムとは「障害復旧のために、システム内部の状態を、実用的かつ人によって認識の齟齬が発生しないような形式で出力するシステム」と考えられます。これはマイクロサービスが備えている性質ではありません。そして、これはまさしく前の節であげた「何かしらの障害が発生したときにシステムの状態を把握・デバッグし、早急な復旧措置をとれるための方法が必要である」という課題に対する解決策と言えます。
可観測性のあるシステムを構築することで、障害発生時に早急にシステム内部の状態を取得し、障害原因を突き止め復旧措置が可能になると考えられます。
次節からは、可観測性のあるシステムを実現するために必要なことを見ていきたいと思います。
可観測性はどうやって実現する?
システム内部の状態を実用的かつ、人によって認識に齟齬が発生しないような形式のデータとして出力するためにどのようなものを用意しなければならないでしょうか?
メトリクス、ログ、トレースは可観測性の3つの柱としてよく知られています注2。実際にこれらはマイクロサービスなどの分散システムで可観測性を実現するための重要な構成要素となります。
メトリクス
メトリクスは、ある特定の時点もしくは非常に短い期間でのシステムの状態を表現したものです。たとえば、ある時点でのあるサービスのCPU利用率や、ある短い期間(たとえば10秒)でのサービスのリクエスト回数といったものを表します。
昨今の多くのメトリクス収集ツールは、第2回の記事でも紹介したようなマイクロサービス導入時によく使われるコンテナオーケストレーションツール(Kubernetes)をサポートしているため、既存のシステムに何か変更を加えることなく情報を集めることが可能です。そのためメトリクス、ログ、トレースの中でもとくに取りかかりやすいものだと思います。
メトリクスは単体のデータで利用されることはなく、収集したデータをサンプリングしたり集計したりすることで、特定の期間でのシステムの状態、もしくは状態の遷移を表現できます(図5)。
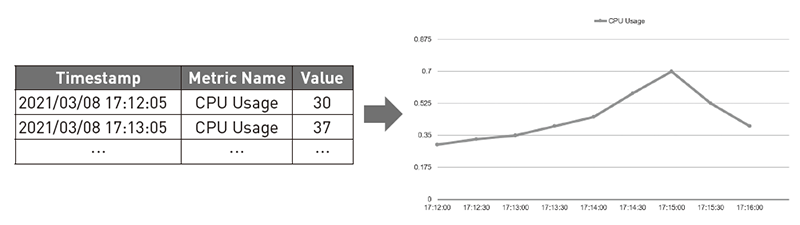
図5 メトリクスと、メトリクスをグラフ化したイメージ
メトリクスはシステムの全体的な状態を観測する目的で使われることが多いです。
一方でメトリクスは定期的なスパンでこれらの測定値を回収するという特性上、個別のリクエストを詳細に調査する用途には適しません。もちろんリクエスト単位でメトリクスを回収することで、リクエスト単位での観測は可能かもしれませんが、これはメトリクス用ストレージの圧迫につながるためリクエストの詳細は次項で紹介する、ログで観測するのが良いと言えます。
ログ
ログはシステム内のあるコードが実行されたときに生成されるテキストになります。そのため3つの柱のうち最もきめ細かい情報を提供してくれます。
ログもメトリクスに次いで導入しやすいです。ログ収集ツールもメトリクス同様に主要なコンテナオーケストレーションツールのサポートをしているものが多く、ログ収集ツールを導入しアプリ側でロギングの設定を行うだけで観測を始めることができます。
ログの典型的な構造は次のようなタイムスタンプとログメッセージのセットになります。
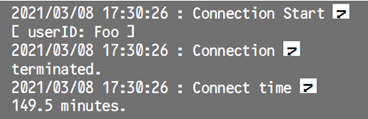
このように構造化されていないログメッセージは検索性が低いため、最近では次のようにJSONフォーマットなどの構造化ログという形式を採用しているシステムが多いです。
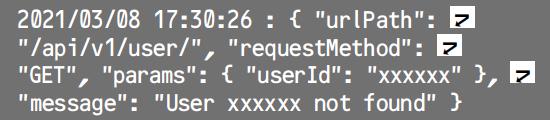
構造化されたログデータはログ確認ツールなどで解釈しやすくなり、検索性が向上します。またこのように構造化されたKey-Valueの組み合わせはメトリクスとしても扱うことが可能で、より多くの情報を提供できるようになります。
ログとメトリクスを導入することで、システム内の個々のコンポーネントの状態についてはかなりの情報を得ることができます。
しかしながらマイクロサービスのような分散システムでは、1つの処理を行うのに複数のコンポーネントをまたいで処理することが多々あります。コンポーネント間の依存関係の状態を確認するにはログやメトリクスだけでは非常に困難です。このような状態の確認にはトレースを利用するのが適しています。
トレース
トレース(厳密には分散トレーシング)はマイクロサービスなどの分散システムでの、エンド・ツー・エンドのトランザクションを観測可能にします。
トレースはスパンという特殊なイベントを生成することで実現します。スパンは各コンポーネントでの処理で費やされた時間を表します。
トランザクションが開始されると、システム全体でユニークなトレースIDを生成し、同一トランザクション内のすべてのスパンに伝播します。このトレースIDでスパンを集約することでトランザクション内のコンポーネント間の依存関係の分析や、時間的にボトルネックとなっているコンポーネントの発見に役立てることができます(図6、表1)。

表1 スパンデータの例
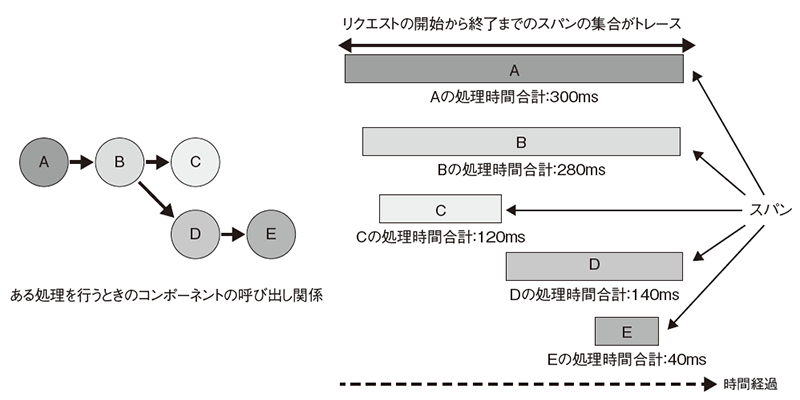
図6 トレースにより、ボトルネックになっているサービスを特定するための情報が得られる
トレースの導入は、ログやメトリクスに比べるとハードルが高いです。トレースIDを生成し、リクエスト先のコンポーネントへ伝播させたり、トレースIDが付与されたリクエストを受け付けたりするようなしくみが必要になります。これらの実現のためにはJaegerやZipkinなどの分散トレーシングライブラリを用意し、トレース対象のアプリケーションすべてに埋め込まないといけません。
分散トレーシングを一部だけでなく、システム全体に導入するのであれば、サービスメッシュを導入するのが良いかもしれません。サービスメッシュとはマイクロサービスでのサービス間通信でのさまざまな課題を解決するしくみです。サービスメッシュのプロダクトの多くは分散トレーシングをサポートしています。サービスメッシュで分散トレーシングを実現すると、アプリケーションごとに分散トレーシングライブラリを埋め込む必要なくトレースを集めることができます。
メトリクス、ログ、トレースはお互いに補完し合うものである
ここまで見てきたようにメトリクス、ログ、トレースはお互いに補完しあうものです。
ログとトレースだけでは、システム全体を俯瞰して観測できず、障害の早急な発見が難しくなります。
トレースとメトリクスだけでは、システムの状態の詳細まで確認することが難しくなります。
メトリクスとログだけでは、複数コンポーネントの相関関係を確認するのが難しくなります。
メトリクス、ログ、トレースの3つを組み合わせることでマイクロサービスのような分散システムでの内部状態を最大限に可視化することが可能になります。
可観測性をより高めるためには?
前節では可観測性を実現するために集めるべきデータについて見ていきました。これらを集め、見られるようにしただけで可観測性が実現されたと言えるでしょうか?
前述のようにメトリクス、ログ、トレースは互いに補完しあうものです。マイクロサービスのような分散システムで何か障害が発生し復旧作業を行う場合は一般的に次のようなステップを踏むことになります。
- 1.メトリクスで全体を俯瞰し何が起きているかを把握する
- 2.トレースを確認し、どのコンポーネントで問題が発生しているかを特定する
- 3.問題がありそうなコンポーネントのログを確認し、障害原因を発見する
このように、メトリクス→トレース→ログという順番でドリルダウン(観測範囲を絞ってより詳細な情報を取得)していくことが多いです。しかしメトリクスからトレース、トレースからログへの移動はユーザーの判断が介入します。このようなデータ間の関連付けや、目処をつける判断の精度はユーザーの経験に依存してしまいます(図7)。
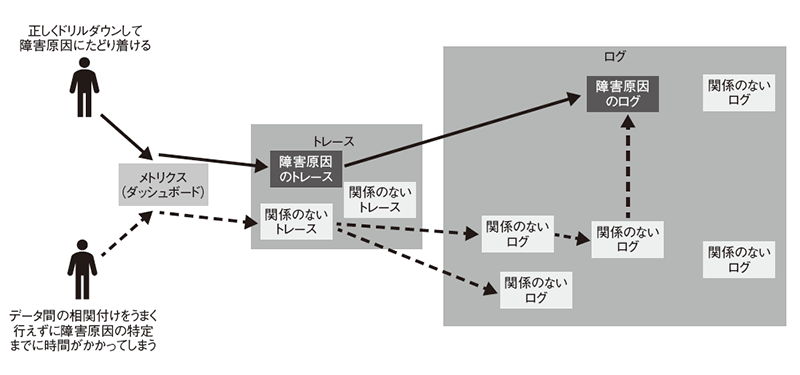
図7 メトリクス、ログ、トレース間の相関付けはユーザーの経験に依存する
CNCFの可観測性の定義でも述べられていたように、ただデータを提供するだけでは可観測性は高まりません。
メトリクス、ログ、トレース間の相関付けをシステム側で行い、ユーザーの判断を減らし、ユーザーによって取得できるデータが変わらないようなしくみをサポートするツールを選定し、導入することも可観測性においては重要となります。
メトリクス・ログ・トレース間の相関付けを行うツール 注5
相関付けのサポートは多数の監視SaaS提供会社の製品や監視系のOSSで取り組まれていますが、ここでは一例として k8sのメトリクスダッシュボードとして非常に人気なOSSであるGrafana、そしてGrafanaのSaaSなどを提供しているGrafana Labs社の関連ツールでの可観測性への取り組みを見てみたいと思います。
Grafana LabsではPrometheus、 Grafana、 Grafana Loki、 Grafana TempoといったOSSの開発を主導しています。 これらは以下の機能を提供します。
- ・Prometheus : メトリクス集約
- ・Grafana : メトリクス可視化ダッシュボード
- ・Grafana Loki : ログ集約
- ・Grafana Tempo : 分散トレーシング
ここでは各ツールの詳細については触れません。 可観測性の3本の柱であるメトリクス・ログ・トレースに対応するツールがあり、それらを可視化するためのダッシュボードとして、このようなツールがあると思ってください。 サンプル 注6 が用意されているので、それを用いて紹介します。
Grafana関連のツールを利用するとメトリクス→トレース→ログという遷移はGrafanaという共通ダッシュボード上で相関付けされ、動的に作成されたリンクから辿っていくことが可能となります。
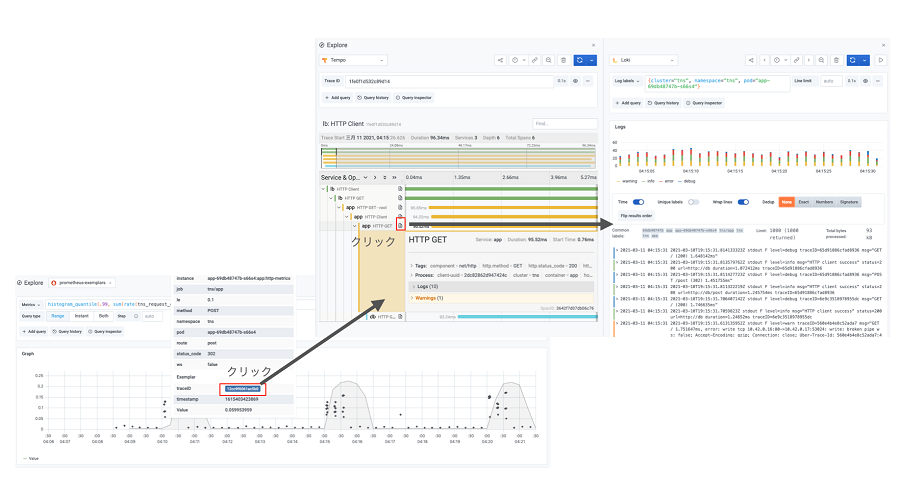
図8 Grafanaでメトリクス・トレース・ログを相関付けしている様子
図8ではメトリクスのグラフ内に分散トレーシングのサンプリングされたリクエストが表示されています。このサンプリングデータからトレース詳細へ飛ぶことが可能です。またトレースから各スパンの関連するログへ飛ぶことが可能です。 またこれらはGrafana1つで完結して行うことができます。これによりメトリクス・ログ・トレース間の移動でのユーザーの判断機会が軽減され、異なるツールへ移る必要もなくなります。
インフラは誰が責任を持つ?
ここまで紹介してきた内容を見てどう感じましたか? もしあなたがスクラムチームの一員で、これまでの話(クラウドや障害対応、可観測性など)を他人事のように感じていたら、注意しなければなりません。
スクラムガイド2020年版注3では、スクラムチームを次のように定義しています。
スクラムチームは、ステークホルダーとのコラボレーション、検証、保守、運用、実験、研究開発など、プロダクトに関して必要となり得るすべての活動に責任を持つ。
また、かの有名なMartin Fowlerが提唱する“Microservices”というブログ記事注4においても、“Products not Projects”、すなわち、リリースして終わり、というプロジェクトとしてとらえるのではなく、1つの製品を作り上げたと認識し、リリース後も責任を持つべきであると伝えています。
このように、インフラは、特定のインフラエンジニアだけの仕事ではなく、スクラムチームが自分事として考えないといけない重要なテーマなのです。
たとえば、前述したように、複雑なシステム構成では障害が連鎖的に発生していく可能性があります。インフラレイヤの障害だと思っていたらアプリケーションレイヤの障害だったということが発生するかもしれません。また、適切に設計されたアプリケーションログは、障害復旧に非常に役立つでしょう。どの処理に対してログを埋め込むか、ログメッセージ・埋め込む変数は何にするか、ログレベルをどうするかはスクラムチームが検討していくべきです。
最後に
今回紹介した可観測性は、監視と同義のように扱われていることが多いですが、今回見たように監視は可観測性を実現するための構成要素の1つでしかありません。真に重要なのはマイクロサービスなどの複雑な分散システムで発生する未知の障害にどう立ち向かうかということです。
これには今回紹介したような監視用のツールを導入することも必要ですが、チームの働き方・考え方から変えていかなければなりません。
今回紹介したようなツール類を導入して、メトリクス、ログ、トレースの収集をし、データの相関付けを実現したとしても、肝心のユーザーが、メトリクスだけを確認し「以前と同じ障害パターン」と勝手に解釈してしまっては意味がありません。チームの一人一人が複雑なシステムでは未知の障害が常に発生し得るという考えを持って取り組まなければなりません。
今回の記事で少しでも、障害に対してどう立ち向かおうかという考えを持っていただけたのであれば幸いです。
※図・表・リストは技術評論社の許諾を得て掲載しています。
- 注1)https://github.com/cncf/glossary/blob/main/definitions/observability.md
上記のドキュメントに対して、筆者が意訳を行ったものを掲載しています。 - 注2)https://learning.oreilly.com/library/view/distributedsystems-observability/9781492033431
- 注3)https://scrumguides.org
- 注4)https://martinfowler.com/articles/microservices.html
- 注5)当段落は、技術評論社「Software Design」2021年5月号に寄稿したコラム内容から追記しています。
- 注6)https://github.com/grafana/tns