
















AI開発のプロジェクトを紹介します 【第1回】 ~AIの考え方やプロトタイプの作成について~
はじめに
NTTデータ先端技術の“AIソリューション事業部”では、主にAI案件のサービスやAIを扱う開発案件の事業を展開しています。 AIは現在主流の脳の神経回路を模したディープラーニングを使用したものからルールベース処理といった単純な仕組みまでさまざまなものがあり、要件に合わせて最適な方式を用いてシステムを構築していきます。 本コラムでは、AI開発案件業務の進め方について、プロジェクトの開始から終了までの流れを実際の体験談を交えて3回に分けて紹介していきます。
第1回では、AI案件の発生からプロトタイプを作成するまでの取り組みについて紹介します。
開発案件の発生と開発方式について
皆さんが生活していくうえで、インターネットや電子機器を利用することはごく普通のことになっています。 新しいツールや文化を取り入れることで生活をより便利にすることができるわけですが、学校や企業でも同様に、日々の活動を効率よく進めるために新しいシステムを導入することが必要になります。そのシステムがソフトウエアで実現できる場合は、内部の開発部門や外部のIT企業へシステム開発を依頼することで開発案件が発生し、実現 へ向けて話を進めていくことになります。
システム開発の要件の一例を以下にあげます。
- ・オンライン化推進へ向けて、学校の講義や生徒との対話をWebサービスで実現したい
- ・社内の帳票処理システムを更改して使いやすくしたい
- ・製品の問い合わせ対応システムやFAQシステムを導入したい
一般的な開発案件は、以下の流れ(ウォーターフォール方式と呼びます)でシステムを開発し、基盤と呼ばれるサーバー環境にシステムを配置してサービスを開始することで完成します。
ウォーターフォール方式による開発の流れの例
- (1) 要件に沿って仕様を決める
- (2) 仕様通りに動作するプログラムを製造する
- (3) 動作試験を実施する
- (4) サービス環境を構築し、プログラムを配置する
- (5) サービスを開始する
コンピューターは計算や決まった手順で処理を繰り返すことが得意なため集計の式や処理順が決まれば仕様化は容易です。仕様が決まれば各工程でやるべきことも明確になるので、必要な工数も見積もりやすいですね。 また、システム開発の過程ではさまざまな問題が生じることがありますが、これらの問題解決の工数も加味したうえで見積もりを実施しておけば安心です。
しかし、要件の中には仕様が明確ではない場合があります。例えば次のような場合はどうでしょうか。
・マーケティングのために、製品の情報が記載された多様な文書から製品の短所が記載された文章を抽出したい
この要件には、“多様な文書”や“短所が記載された文章”など不明瞭な部分が多く、未知の入力情報に対して人の思考のようなモノで文章を評価する必要がありそうなため、仕様がなかなか決められません。 仮に、「こんな方法で情報を処理すれば上手くいくのではないか?」というアイデアがあったとしても、実装して得られた結果が期待通りであるかはわかりません。おそらく、何度も試行錯誤を繰り返すことで初めて納得できる結果に到達できるのではないでしょうか。
要件が未知の課題で実現後の効果や全体の工数を見出すことが困難な場合は、“技術の検証を行いながら実現可能性を見極めていく”方法で作業を進めます。この進め方はPoC(Proof of Concept:概念実証)と呼ばれます。PoCでは、実現方法のアイデアをシステム化してその方法が有効であるか評価し、さらにブラッシュアップしていくことでひとつの成果物とし、その成果物に対して対価を得ます。 また、PoCでは、前述のウォーターフォール方式のように決まった工程を順番に進めていく方式ではなく、アジャイル方式という小さいサイクルを何度も繰り返していく手法で進められることが多いです。
当事業部では、このように実現方法が難しい案件を、AIを用いたPoCで解決していくことを得意としております。
アジャイル方式によるAI開発の流れの例
- (1)現状を分析し、AIの解決手法を決定する
- (2)AIの仕様を仮決めし、プロトタイプを作成する
- (3) AIのモデル(言語モデルや推論モデル)を作成する
- (4)作成したAIモデルを検証し、誤り分析を行う
- (5) 誤り分析の結果を仕様やデータ作成に反映しながら(2)~(4)を繰り返してAIの精度を高める
AIは何ができるの?
続いてAIのお話です。昨今、ニュースやテクノロジーに関する記事などで、“AI”という言葉をよく見かけるようになりましたが、AIとはどのようなものなのでしょうか?
AI(Artificial Intelligence)は人工知能とも呼ばれます。さらにAIは、「決まった課題に対して問題を解決することができるAI=弱いAI」や、「人間のように意思を持ち、考えて行動できるAI=強いAI」に分けることができます。ソフトウエア開発におけるAIは、一般的に弱いAIを指すことになります。AIを用いることで問題を自動で解決したり、人間の意思決定を手助けして作業を効率化したりすることができます。スマホのナビ機能や音声指示もこれらに該当します。
次はAIの仕組みについてです。AIは次のように大きく3つの世代に分けられ、処理方式も異なります。
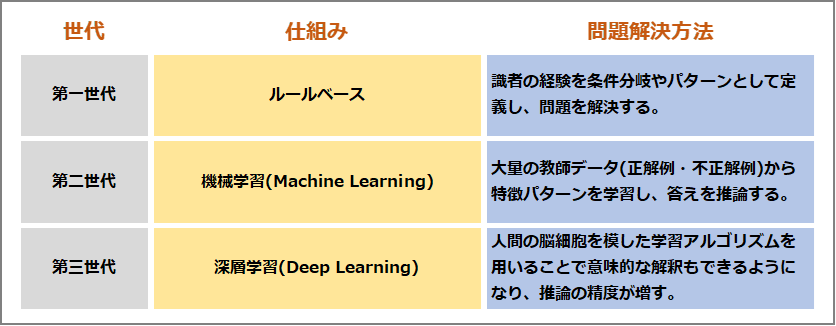
図1:AIの世代
最近は第3世代AIの進化が進んでおり、画像認識による疾患の早期発見や意味理解を用いた文書検索などが実用化されています。 世代が新しいAIほど開発には高度な技術が必要とされますが、古い世代のAIでも適切な箇所で使用すれば大きな効果が得られるため、AIで問題を解決するためには、世代や難易度にとらわれず適切なAIをいかに選択するかが重要になります。
当事業部で受注するAI案件は多様なニーズとなっており、画像認識、音声認識、自然言語処理などを駆使して目的を達成していきます。私が所属する担当では自然言語処理を得意としており、次のような案件を担当することが多いです。

図2:AI案件の例
これらAI案件を、PoCとして受注することで、プロジェクトが開始されることになります。
AIの解決手法を決定する
引き続き、「製品の情報が記載された多様な文書から製品の短所が記載された文章を抽出したい」という要件に沿って話を進めます。AIを開発するためには現状を分析し、どのような技術を用いるべきかを検討します。 まずは要件を少し具体的にしてみましょう。
要件の具体化
- ・多様な文書 → どんな文書を処理するの?新聞記事?SNSの情報?
- ・短所が記載された文章 → 短所に相当する表現を検索したらどうか?具体的にどのような表現?ネガティブな表現以外にも該当する表現は無いか?
次に、人間の思考に当てはめた場合にどのような手順を踏んで目的を達成するか?を考えてみます。
人間の思考の例
- ・入力された文書に記載された文章の特徴から、文書の種別を特定する。
- ・製品の短所を述べた表現を決定する。
- ・文書の種別ごとに、製品の短所に相当する文章を検索する。
次に、実現方法を検討してみます。
仮に新聞記事やSNSに投稿された情報を扱うとしましょう。これらの文書では文章の質(記事なのか意見なのか)に加え、語彙も異なります。さらに、何をもって短所と断定するのか?特定の単語なのか、悪い評価をしている文章なのか、などさまざまな疑問が生じてきます。
従来の検索技術では、文章から得られるキーワードをスコア化して比較するなどのアプローチを取るのですが、最新の深層学習を用いた推論では、単語の使われ方などから意味を理解して検索することができるため、従来手法よりもより精度の高い検索結果が得られることが知られています。
今回の要件のように正解の定義が難しい場合は、深層学習の仕組みを使って“このような表現を短所としたい”という事例をAIモデルに学習させ、そのAIモデルに推論させてあげることで良い結果が得られるかもしれません。
このようなプロセスを経て、実現方法を決定していきます。 以降の説明では、AIに深層学習を利用するという前提で話を進めていきます。
AIのプロトタイプを作成する
手法が決定したら次はAIの実装になりますが、実装については他のコラムやWebの記事でも詳しく紹介されているため、本稿では割愛します。
AI開発はアジャイル方式で行うことが主流なため、日々目標を決めてその結果を評価してトライ&エラーを繰り返して少しずつ完成形を目指していくことになります。その過程で方針が変更になる場合もありますが、アジャイル開発では作業期間に予めバッファ(不確かな課題に対応するための余剰工数)を設けておき、問題や課題に対応できるようにしておきます。
もし工数に余りができたら、未解決の課題にも取り組み、成果物をより良いものに仕立ていきます。過去の経験上、新しい技術に取り組む場合は、さまざまな課題や追加対応が発生するためバッファが余ることはほぼありません。各課題は優先順位を決めて対応し、残課題となるものについて今後どうすべきか?について議論、案出しをすることが多いです。
外部の組織や内部の有識者と協力する
昨今のソフトウエア開発環境は、開発を効率化するOSS(オープンソースソフトウエア)がとても充実しており、AIに関するライブラリやモデルも多数公開されています。これらOSSに加えて、NTTデータやNTT研究所の技術を用いて開発や検証を実施することもあります。外部の技術を用いる場合は必要に応じて技術開発者とのディスカッションも実施してノウハウの共有を行います。
そのため、これまでは難しかった意味を理解した解析なども高精度で実行できるようになりました。ですが、それだけでは顧客が所望する要件を満たすことはできません。昔からある基礎技術、関連技術、アイデアを組み合わせて細かい部分にも手を加えることで、大きな目標を達成することができます。
時には、論文などで発表される考え方にならって処理を実装することもあります。その場合、考え方は理解できるものの実際にプログラムに書き起こすと簡単では無いこともあり、実装が完成したものの期待する結果が得られない、ということもありました。
また、当社には各分野のスペシャリストも多くいますので、その方たちから知見を得て課題を解決していくこともあります。
このように内部、外部とも上手く連携することでシステムが完成に近づいていきます。
学習用のデータを準備してモデルを作成する
AIの実装が完成したら、次はAIを評価するためのデータを準備してモデルを作成します。
自然言語処理で深層学習を行う場合は、コーパスと呼ばれる言語資源データと教師データ(事例の正解例と不正解例)を用いてモデルを作成することが多いです。
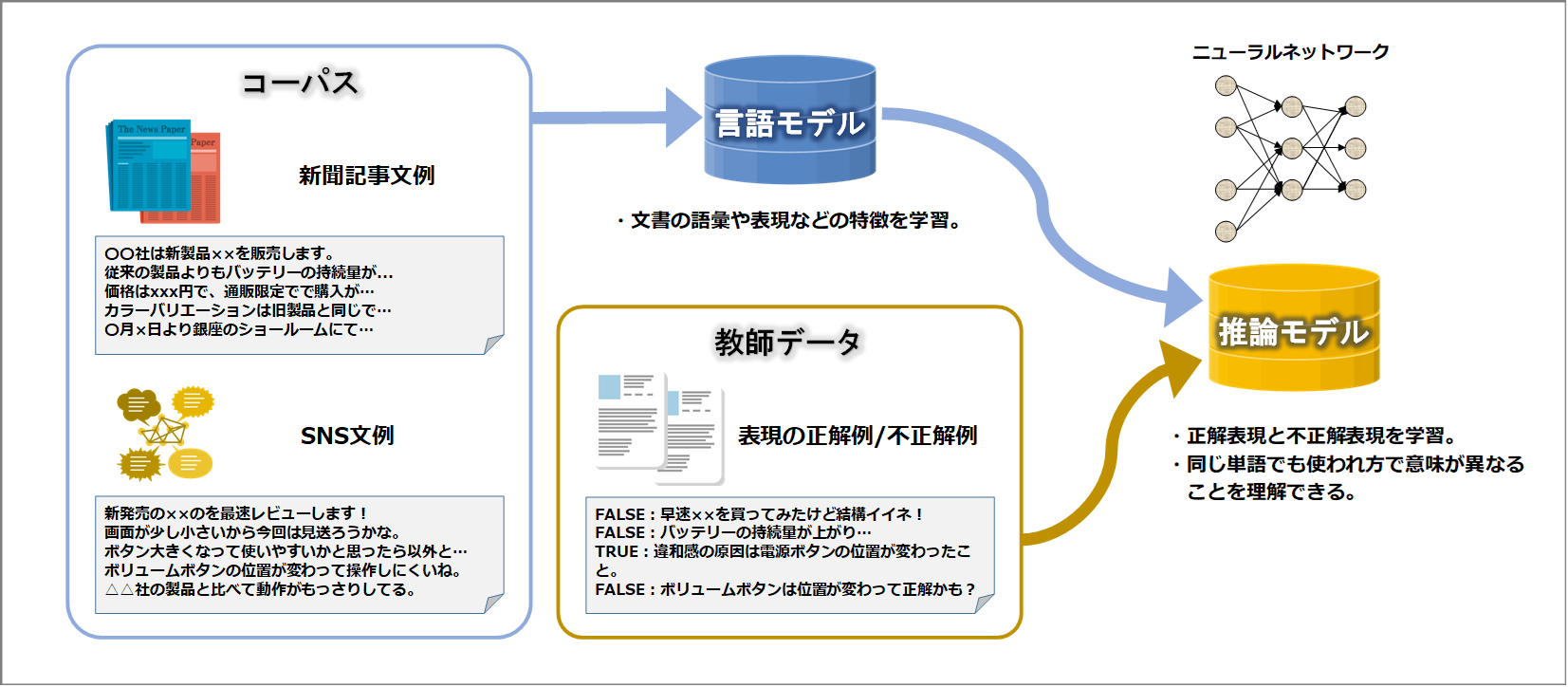
図3:モデル作成のイメージ
コーパスとは、言語の資源とも言うべきテキストの集まりです。例えば新聞記事やSNSの情報を扱う場合は、文章の質、登場する単語、表現などが異なるため、予め言語の資源としてこれらのデータを大量に用意して言語モデルとして学習させます。学習した言語モデルを使用することで、新聞記事やSNSの文章それぞれにどのような単語や表現が登場するのかなどの文章の特徴が判断できるようになります。
次に、モデルを学習するための教師データが必要になります。教師データは目的によって用意する内容が異なります。
例えば、
- ・猫を画像認識するAIであれば猫(正解)とそれ以外(例えば犬や虎など)のデータ
- ・カルテのメモから疾患を判定するAIであればさまざまな疾患に関する記述のデータ
といった具合です。
また、教師データは、モデルを作成する他に検証用のデータとして一部残しておき、評価の際に使用することもあります。
大抵のケースでは数千件規模の教師データ作成が必要になります。このような場合はデータオーグメンテーション(基データから副次的にデータを作成して増幅する技術)を用いたり、クラウドファウンディングを用いて大量の教師データを作成したりします。 特に判定が難しい課題の場合は、データオーグメンテーションによるデータ増幅を行うと、基となるデータに類似するデータが作成されることになるため精度面に悪影響を及ぼす可能性があります。また、人為的に作成する場合も、教師データを作成する人のスキルに左右されるようにモデルの性能も変わってきます。そのため、正解の定義を明確に決めておき中間結果をプレビューしてデータ作成の観点にブレがあれば正していくことが必要になります。
本題に戻り、新聞記事やSNSのコーパスから「製品の短所が記載された文章」を教師データとして定義する場合を考えてみましょう。
「〇〇機能は使いにくい」といったような誰もが思いつくネガティブな表現もあれば、「△△社製品のほうが実用性がある」のように他の製品と比較して短所としているケースもありそうです。また、何を境目に短所と捉えるか?など、教師データを作成する人が100人いれば答えは100通りになると思います。
これと同様な作業をコンピューターにやらせるわけですから、得られた結果の評価も難しいものになるでしょう。
AI開発における初回(できたてモデル)の評価結果は良くない結果になることが多いですが、モデルの傾向を見ながら何度も実験を重ねていき、目標性能を目指していくことになります。 このようにトライ&エラーで開発~評価を重ねていく作業は、モノ作りが好きな方にとっては腕の見せ所になります。
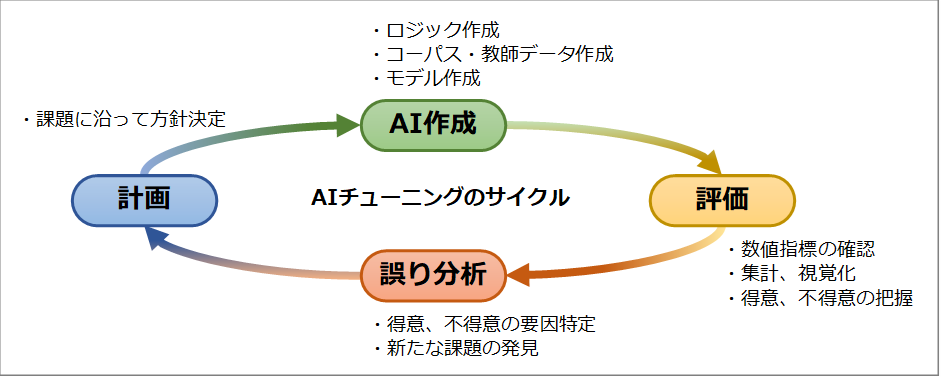
図4:トライ&エラーで繰り返す
ここまでが、AI案件の発生からプロトタイプを作成するまでの取り組みについての紹介です。
次回は、AIの性能に関する取り組みについて紹介していきます。