
















NER(固有表現抽出)始めませんか? 第1回
概要
近年、ディープラーニングの自然言語処理分野の研究が盛んに行われており、その技術を利用したサービスは多様なものがあります。
当社も昨年2020年に「INTELLILINK バックオフィスNLP」という自然言語処理技術を利用したソリューションを発表しました。
INTELLILINK バックオフィスNLPは、最新の自然言語処理技術「BERT」をはじめとする最新の自然言語処理群に加え、ルールベース・機械学習問わず様々な技術要素を備え本コラムにて扱う「知識抽出」以外にも「文書分類」「機械読解」「文書生成」「自動要約」などさまざまなAI機能を備えており幅広いバックオフィス業務の効率化を実現することが可能です。※1
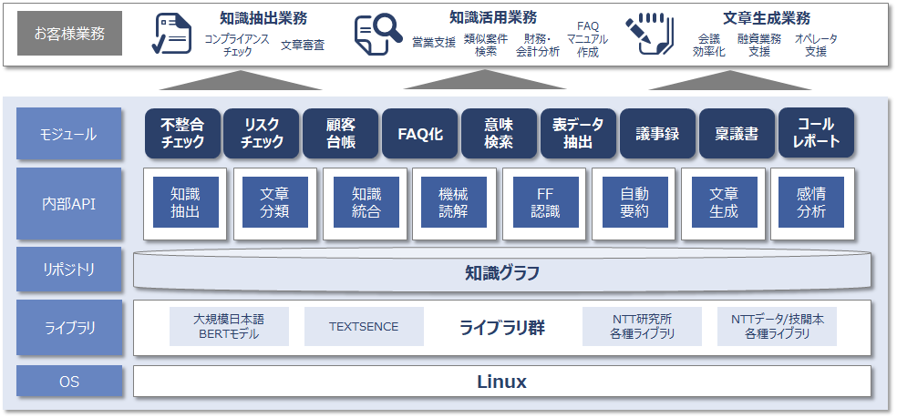
本コラムでは、様々な企業が自社で取り扱うビジネス文書、メール・応対履歴といったログ情報などの自然文から機械が取り扱いやすい構造化データとして情報を抽出する「知識抽出」の取り組みの一つである「固有表現抽出」に焦点を当てAIの技術的な遍歴に沿ってご紹介したいと思います。
固有表現抽出とは?
固有表現抽出とは、入力となる自然文から組織・地名・製品名などの固有名詞に日時や数量などを加えた固有表現を機械的に取り出す取り組みです。
例えば以下のようなニュース記事から、どのような固有表現が抽出できるでしょうか?
安部首相人名は15日日付表現首相官邸場所にて、台風19号イベントの被害について「激甚災害イベント」に指定する考えを明らかにしました。
情報抽出・情報検索のワークショップであるIREX(Information Retrieval and Extraction Exercise)では以下の固有表現が定義されていますが上記例にある「イベント」のように自分が必要な対象を定義し抽出する事が固有表現抽出での取り組みとなります。
IREXで定義されている固有表現の種類
| 種類 | 抽出対象 | |
|---|---|---|
| ORGANIZATION | 組織名 | 会社名や団体名といった組織の名称 |
| PERSON | 人名 | 役職等も含む個人を表す名前や呼称 |
| LOCATION | 地名 | 都道府県名や観光スポットなど場所を表す名称 |
| DATE | 日付表現 | 具体的な年月日や、昨日/今日/明日といった相対的な表現も含む日付を表す名称 |
| TIME | 時間表現 | 日付表現と同様に時間を表す名称 |
| MONEY | 金額表現 | 1万円、4,000円など金額を表す表現 |
| PERCENT | 割合表現 | 1/2、50%、2割など割合を表す表現 |
このように自然文(日常使っている自然な形の文)から固有表現抽出を獲得することで、文章をタグ付けしカテゴライズしたりExcelやデータベースといった構造化データにまとめる事でシステムで取り扱いやすい情報を抽出する事がタスクとなります。
ルールベース、探索による抽出
AIは第一次ブーム:探索による推論、第二次ブーム:知識を基にルールを利用した推論、第三次ブーム:機械学習による推論とこれまで発展してきました。
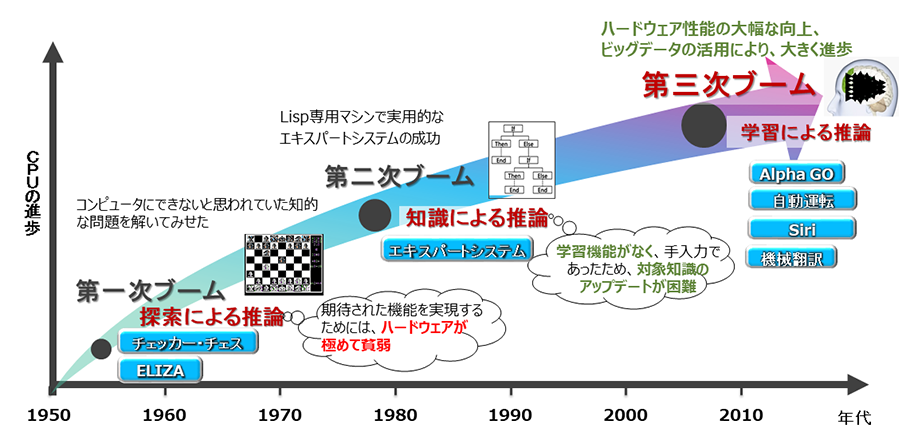
AIブームの変遷
本連載コラムではこのブームの変遷に沿って固有表現抽出を取り扱い、第一回目となる今回は辞書を元にした探索とルールベースによるパターンマッチング手法を取り扱いたいと思います。
- ①辞書による抽出
上記のニュース例では「安倍」「菅」は人名、「首相官邸」は場所というように種類を割り当てました。
このように、抽出したい固有表現の種類毎に文字列を辞書として準備し抽出する方法です。
辞書による抽出ではバリエーションを多く用意する事ができますが以下のような注意点もあります。- 「人名」と「地名」は重複する可能性がある。
例:「石川で11人感染、新たなクラスター発生か」(「石川」さん?「石川」県?) - 日付表現、金額表現などで扱う「数字」を全てのパターン辞書として登録する事が不可能。
- 「人名」と「地名」は重複する可能性がある。
- ②ルールベースによる抽出
正規表現や辞書内の名称など、一定のルールをあらかじめ定めておきこのルールを元に抽出する方法です。
文内から一定のパターンを抽出し特徴づける要素(特徴量や素性{そせい}と呼びます)を導出し、パターンに沿うようルールを定めるのが一般的です。文章や単語から特徴量として用いられる情報としては形態素(意味を持つ最小単位の言葉≒品詞)や掛かり受け関係を用いる事が多くあります。
自然文からルールベースで抽出するには、様々なパターンが文内に存在する事が考えられパターンを一つずつ導出するために時間が掛かるケースが多くあります。
ルールベースによる情報抽出例
今回は文章を形態素に分割する形態素解析器の「MeCab」を元に、品詞の情報と辞書を用いて抽出を試みたいと思います。※2
抽出対象のデータセット及び抽出する情報として、ストックマーク株式会社により公開されている固有表現抽出の正解付きデータセット「ner-wikipedia-dataset」から企業名(法人名)の抽出を行います。※3
〇抽出方針の立案
データセットから情報をサンプリングし、有用と考えられる抽出方針を検討します。
- ①データパターンの解析
まず、対象のデータを1件見てみましょう。
- 文:
- 2019年現在、日本の航空会社では日本航空、全日本空輸、AIRDOの3社で使用されている。
- 企業名:
- 日本航空、全日本空輸、AIRDO
対象データはWikipediaからの引用文のため、「~は」といった説明文や「、」(読点)による羅列が企業名として多いかもしれません。
文を形態素解析し、前後の品詞を見てみましょう。
形態素 品詞 航空 名詞 会社 名詞 で 助詞 は 助詞 日本航空 名詞-固有名詞-組織 、 記号,読点 全日本空輸 名詞-固有名詞-組織 、 記号 AIRDO 名詞-固有名詞-組織 の 助詞 形態素解析結果
助詞「~は」と記号(読点)の後、助詞「~の」前に発生する頻度が高そうです。
データセットから企業名の前後における品詞と形態素の発生数を見てみましょう。
法人名の前後の形態素と品詞 TOP3
企業名の前
形態素 品詞 発生数 、 記号,読点 661 は 助詞 226 の 助詞 142 企業名の後ろ
形態素 品詞 発生数 の 助詞 497 は 助詞 334 が 助詞 260 やはり全体的に見ても企業名の前後に読点、「~は」、「~の」が接するケースが高いようです。
上記の3つの法人名は以前からの有名企業という事もあり、MeCabの基本的な辞書に既に固有名詞として表現されているため「日本」「航空」と別れることなく「日本航空」と単一の形態素として抽出できました。
MeCabにて組織として登録されている形態素は企業名である可能性が高いのでこれは候補の一つです。ではMeCabの辞書に登録されていない企業名ではどうでしょう。
- 文:
- レッドフォックス株式会社は、東京都千代田区に本社を置くITサービス企業である。
- 法人名:
- レッドフォックス株式会社
形態素 品詞 レッド 名詞-一般 フォックス 名詞-固有名詞-人名 株式会社 名詞-一般 は 助詞 、 記号 形態素解析結果
辞書には該当の社名が存在しませんが、「レッドフォックス株式会社」の各形態素の品詞は名詞と判定されました。
データパターンまとめ
上記のMeCabに登録されていない企業名は一例ですが、企業名や製品・サービスといった名称には一般名詞や人名など単独の形態素では他の意味合いとなるの連続した名詞で構成された例が多くあります。
また、日本の企業名には「第一フロンティア生命」の「第」、「旧常陽銀行」の「旧」の様に接頭辞をもつ企業名が多くありこの接頭辞をMeCabでは「接頭詞」と判定するためこれも企業名の一部として取り扱いと思います。
これら分析結果から、法人名の前後の品詞と法人名を構成する品詞を以下の様に定義したいと思います。
法人名の前後の品詞 助詞:「は」、「の」、「が」及び句読点 法人名を構成する品詞 MeCabで組織と判定された単一形態素 または
2つ以上の連続した名詞(接頭詞から始まるものを含む) - ②辞書データの検討
今回使用する形態素解析器MeCabは確率統計的に形態素と品詞を予測するアプリケーションです。
固有表現も抽出できますが、MeCabが持つシステム辞書に依存しており全ての単語のカバー範囲も限られるため解析対象とする文書とMeCabの予測がマッチしない場合は企業名として認識されなかったり、誤認識されるケースも少なからずあります。
そこで今回は①の品詞構成による情報と企業名の辞書による抽出を検討します。辞書情報としてはMeCabで利用な形式でMITライセンス公開されている「JCLdic」を利用します。
この辞書は国税庁の法人番号公表サイトにある企業名を法人名として辞書化したものですが一般語が使用された企業名ではMeCabの解析で誤認識しノイズとなる可能性があることから以下2通りの抽出方式をとり比較をしてみたいと思います。- ①上記①の手法で抽出した企業名候補を辞書に引き当て企業名として確定する方法
- ②MeCabに辞書として組み込んで抽出する方法
以下は、参考情報としてMeCabとJCLdicを組み合わせた方法で抽出した結果誤認識しノイズとなる例です。
- 文例:
- 同僚と社員食堂で昼食を取りました。
形態素 品詞 同僚 名詞-一般 と 助詞 社員食堂 名詞-固有名詞-組織 で 助詞 を 助詞 形態素解析結果
この例では「株式会社社員食堂」という実際の企業名が存在し、JCLdicに「社員食堂」が組織の固有名詞であると登録されているために発生しています。
これらサンプリングと外部情報から、特定の品詞の前後に連続する名詞から企業名が抽出できそうだという知見を得ました。次では、MeCabとJCLdicを用いて法人名を抽出し抽出精度を見てみましょう。
〇抽出結果の精度評価
今回の抽出では、抽出精度を図る指標として混同行列を用いて性能評価を行います。
- 〇混同行列とは?
混同行列は対象を正しく予測できたか/できなかったか、対象外を正しく対象外と予測できたか/できなかったかをチェックし正解率や取りこぼしが無かったかを計算するための指標です。
AIが出した答えの一つ一つについて以下の4つに分類します。- TP(True Positive)
- 対象を対象として正しく予測できたか
- TN(True Negative)
- 対象外を対象外として正しく予測できたか
- FN(False Negative)
- 対象を誤って対象外と予測したか
- FP(False Positive)
- 対象外を誤って対象と予測したか
上記の4つの分類を元に、今回はよく精度の判断指標として使用される正解率(Accuracy)、適合率(Precision)、再現率(Recall)を用いて評価を行います。
正解率(Accuracy)= 予測対象の全体に対しての正解率
Accuracy = (TP + TN) /(TP + TN + FN + HP)適合率(Precision) = 対象と予測した中で実際に正解できた率(高いほど誤りが少ない)
Precision = TP / (TP + FP)再現率(Recall) = 全ての対象に対して実際に正解できた率(高いほど取りこぼしが少ない)
Recall = TP/(TP + FN)
〇抽出処理のサンプル
以下はこれら条件を元に、実際に抽出から精度評価までを行うコードです。
※Pythonコードで記載しています
import json
import MeCab
from collections import Counter
from tqdm import tqdm
# 形態素解析器としてMeCabを準備
mecab = MeCab.Tagger("-Ochasen")
try:
mecab.parse("")
except:
pass
# MeCabによる形態素分割処理
def get_token(text):
result = []
morph_pos = 0
# 形態素分割で半角スペースが消えるので、位置を覚えておいてあとで、半角スペース位置を加算する
half_with_space_indexes = [i for i, w in enumerate(text) if w == ' ']
node = mecab.parseToNode(text)
while node:
feat = node.feature.split(",")
if feat[0] != "BOS/EOS": # 開始・終了のラベルは除外
surface, hinshi1,hinshi2,hinshi3 = node.surface, feat[0], feat[1], feat[2]
# 表層(オリジナルの文字列)と品詞情報
# 文字の開始位置・終了位置を併せて格納
span = [morph_pos, morph_pos + len(surface)]
result.append({"surface": surface, "hinshi1": hinshi1, "hinshi2": hinshi2, "hinshi3": hinshi3, "span": span})
morph_pos += len(surface) + (1 if morph_pos + len(surface) in half_with_space_indexes else 0)
node = node.next
return result
# 抽出対象のjsonデータをロードし、形態素分割します。
print("データセット読み込み start")
sentences = []
with open("ner.json","r", encoding="utf8") as f:
jsons = json.load(f)
for j in jsons:
# 法人名を正解、法人名以外を不正解とラベル分けします
j["correct"] = [ {"name": e["name"], "span": e["span"]} for e in j["entities"] if e["type"] == "法人名"]
j["incorrect"] = [ {"name": e["name"], "span": e["span"]} for e in j["entities"] if e["type"] != "法人名"]
# 文の形態素解析結果を付加します
j["tokens"] = get_token(j["text"])
sentences.append(j)
# 1件目のデータをサンプルとして表示
print("データ件数:" + str(len(sentences)))
print("サンプル1件:" + str(list(filter(lambda x: len(x["entities"]) >0 , sentences))[0]))
#JCLdic(CSV版)を読み込み
print("JCLdic読み込み start")
company_list = []
with open("jcl_slim.csv","r", encoding="utf8") as f:
for line in tqdm(f.readlines()):
company_list.append(line.strip())
company_list = list(set(company_list))
print("データ件数:" + str(len(company_list)))
print("サンプル1件:" + company_list[0])
# 1文毎に抽出を実施
print("法人名抽出 start")
for sentence in tqdm(sentences):
# 抽出情報を初期化
extract_item = None
sentence["predict"] = []
for idx, token in enumerate(sentence["tokens"]):
# 組織の固有名詞は単独で対象として扱う
if extract_item is None and token["hinshi1"] in ["名詞"] and token["hinshi2"] == "固有名詞" and token["hinshi3"] == "組織":
extract_item = [idx, idx, token["surface"], "1", token["span"]]
# 接頭詞または名詞から始まる文字列のスパン情報を格納
if extract_item is None and token["hinshi1"] in ["接頭詞", "名詞"]:
extract_item = [idx, idx, token["surface"], "2", token["span"]]
elif extract_item is not None and extract_item[3] == "2" and token["hinshi1"] =="名詞":
# 名詞が連続する場合は結合する
new_span = extract_item[4] + token["span"]
new_span = [min(new_span), max(new_span)]
word = extract_item[2] + token["surface"]
extract_item[1], extract_item[2], extract_item[4] = idx, word, new_span
else:
if extract_item is not None:
# 固有名詞は単一形態素で辞書に引き当てる
if extract_item[3] == "1":
if extract_item[2] in company_list:
sentence["predict"].append({"name":extract_item[2], "span": extract_item[4]})
else:
# 2連続以上の名詞が途切れたら前後の品詞確認を実施
if extract_item[1] - extract_item[0] >= 2:
before_token, after_token = None, None
if extract_item[0] > 0:
before_token = sentence["tokens"][extract_item[0] - 1]
# 読点、助詞:「は」、「の」の後を有効とする
if not ((before_token["hinshi1"] == "記号" and before_token["hinshi2"] == "読点") or (before_token["hinshi1"] == "助詞" and before_token["surface"] in ["は", "の"])):
before_token = None
if extract_item[1] < len(sentence["tokens"]) -1:
after_token = sentence["tokens"][extract_item[1] + 1]
# 助詞「は」、「の」、「が」の前を有効とします
if not (after_token["hinshi1"] == "助詞" and after_token["surface"] in ["の", "は", "が"]):
after_token = None
if before_token is not None or after_token is not None:
# 前後の品詞が条件に合致し、JCLdicに含まれる文字列を法人名として抽出
if extract_item[2] in company_list:
sentence["predict"].append({"name":extract_item[2], "span": extract_item[4]})
extract_item = None
# 抽出結果の精度確認
print("精度算出 start")
TP, FP, TN, FN = 0, 0, 0, 0
for sentence in sentences:
# 企業名を正しく抽出した結果をえり分け
pred_correct = [p for p in sentence["predict"] if p in sentence["correct"]]
# 企業名以外を企業名でないとできた正解をえり分け
positive_incorrect = [e for e in sentence["incorrect"] if e not in sentence["predict"]]
# 正解として抽出できなかった企業名をえり分け
negative_correct = [e for e in sentence["correct"] if e not in sentence["predict"]]
# 企業名でない文字列を企業名と予測した抽出結果をえり分け
pred_incorrect = [p for p in sentence["predict"] if p not in sentence["correct"]]
# True Positive = 企業名を正しく企業名と抽出できた抽出件数
TP += len(pred_correct)
# True Negative = 企業名でない固有表現を企業名でないと除外できた件数
TN += len(positive_incorrect)
# False Negative = 企業名である固有表現を企業名でないと除外した件数
FN += len(negative_correct)
# False Positive = 企業名でない文字列をを企業名であると抽出してしまった件数
FP += len(pred_incorrect)
sentence["pred_correct"] = pred_correct
sentence["positive_incorrect"] = positive_incorrect
sentence["negative_correct"] = negative_correct
sentence["pred_incorrect"] = pred_incorrect
del sentence["tokens"]
del sentence["entities"]
# 精度をコンソールに出力
print("TP:{},FP:{},TN:{},FN:{}".format(TP, FP, TN, FN))
print("Accuracy:{}".format((TP + TN) / (TP + TN + FP+ FN)))
print("Precision:{}".format(TP / (TP + FP)))
print("Recall:{}".format(TP / (TP + FN)))
# 結果をファイルに保存
with open('./result.json', 'w', encoding="utf8") as f:
json.dump(sentences, f, indent=4, ensure_ascii=False)
〇抽出結果の評価
- 〇性能評価
正解率、適合率、再現率の3つの指標の元、①「連続した名詞をJCLdicに引き当てる手法」とベースとなる②「MeCabにJCLdicを適用した手法」それぞれの抽出結果で精度を比較してみましょう。
① ② 正解率(Accuracy) 0.814 0.752 適合率(Precision) 0.479 0.274 再現率(Recall) 0.179 0.274 正解率は①の方が高いことから、必要な部分の抽出と不要な部分の除外の全体精度としては①の方が精度が高くなりました。
適合率は①の方が高く、再現率は②の方が高いことから①の手法は②に手法と比較し、誤った抽出は少ないものの正解を抽出する確率は低いことになります。
①は②よりも精度が高いが抽出できる数は少なく、②は①よりも抽出できる数は多いものの精度が低い結果となりました。AI開発においては、実現したい機能に対し複数の手法を検討しそれぞれの出力の多様さと精度を比較する事が多くあります。
出力の多様さ、精度のどちらを求めるのかは、機能として必要とされる要件により異なるためより要件にマッチした手法を取捨選択し決定します。 - 〇誤り分析
- ①対象を誤って対象外としてしまった例
1. 品詞の連続性のルールに該当しなかった例
①の手法では法人名の前後の品詞を元に抽出対象を絞り込むようにしました。
このルールに該当しない例として以下のように「~を」が続く形態素として存在していました。- 文:
- 同月5日には、トヨタファイナンシャルサービス証券株式会社を吸収合併。
- 法人名:
- トヨタファイナンシャルサービス証券株式会社
2. 辞書にヒットする法人名が存在しなかった例
①の手法ではJCLdicの中間サイズのデータを辞書として使用しました。
この辞書は国税庁法人番号公表サイトの情報を元としているため正式名称が含まれる事となります。そのため、以下の例の様に通称での表記については辞書に含まれていないため抽出できない結果となりました。- 文:
- ついに1980年にはBMW JAPANのサブディーラーとしてBMW車の販売を開始、ようやく従来の顧客層をつなぎとめることに成功、以来BMWの販売が同社の主力業務となった。
- 法人名:
- BMW JAPAN、BMW
- 抽出結果:
- 「BMW」のみ
- ②対象外を対象としてしまった例
1. 対象の一部分のみを抽出し、結果的に対象外を抽出した例
MeCabの基本の辞書に含まれる企業名の複数が合併してできた新企業など、企業名が連続した名詞であれば抽出できますが、記号などを含むケースでは部分的な抽出となり対象外となってしまう結果となりました。
- 文:
- IHG・ANA・ホテルズとのフランチャイズ契約は2012年3月31日を以って終了。
- 法人名:
- IHG、ANA・ホテルズ
- 抽出結果:
- IHG、ANA
※正解データも実は間違いであり、正式には「IHG・ANA・ホテルズ」で1つの企業名です。
2. 文意として企業名と扱われないため対象外を対象としてしまった例
単語としては企業名であるが、前後の文脈により企業名以外(下記例だと事件名)である箇所が含まれる例では企業名以外を企業名と抽出する結果となりました。
- 文:
- 1989年の参院選で自民党はリクルート、農政批判、消費税の逆風を受け、連合候補の池田治に敗れ落選、政界を引退した。
- 法人名:
- 無し
- 抽出結果:
- リクルート
①の手法について、「対象を誤って対象外としてしまった例」と「対象外を対象としてしまった例」のサンプルを元に誤りの分析を行いたいと思います。
ルールベースによる情報抽出とその先
上記の精度と誤り分析から、抽出において一定の精度が見込めるもののルールのバリエーションと辞書の情報量に検討の余地があるという事が分かりました。
しかし、2つの検討内容のいずれも単純に増やす事で解決するものではなく、組み合わせによっては更なる誤りを生む可能性もあり精度向上には多くの時間と手間が必要になります。
また、自然文を扱うという観点から誤り分析に記載のある通称や記号を含むケースなど表記ゆれのカバーも考慮すると果てしなくバリエーションを用意しなくてはならなくなり非常に難しい問題です。
このような多くのバリエーションを持つデータの中から、今回検討した品詞によるルールのようなパターンを計算で構築できたらどうでしょう?
上記の第二世代として挙げた「統計/探索モデル」は大量のデータの中からパターンや傾向を統計的に導出する事でルール構築の手間を解決する事が見込める手法です。
次回はこの統計/探索モデルでの検討を元に、第二世代のAIについてご紹介させて頂きたいと思います。