
















NER(固有表現抽出)始めませんか? 第3回
前回のおさらい
本コラム第1回、第2回と続いて、固有表現抽出データセットを対象としたルールベース・探索と機械学習による取り組みをご紹介いたしました。
第3回では前回取り扱った機械学習を更に発展させた深層学習を用いた固有表現抽出への取り組みについてご紹介差し上げたいと思います。
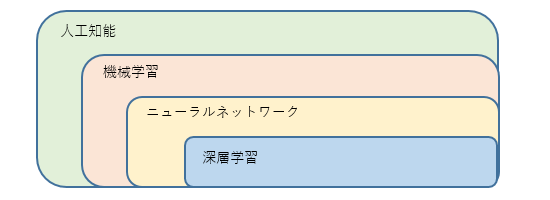
第三世代ー深層学習(ディープラーニング)モデル
まずは、深層学習(ディープラーニング)モデルとは?からご説明したいと思います。
深層学習(ディープラーニング)モデル
音声の認識や画像の特定・識別など、人間の行動・観点をコンピューターに学習させる機械学習の手法の一つ。脳神経回路であるニューロンを模したニューラルネットワークを更に多層構造化したものです。
深層学習は人工知能・機械学習の一種で前回の統計/探索モデルと同様に大量のデータからパターンや規則性を抽出する事で自動判断を行う仕組みとなります。
今回はこの深層学習手法を用いたモデルであり「INTELLILINK バックオフィスNLP」でも採用しているBERTによる企業名の固有表現抽出を取り扱いたいと思います。
BERT(Bidirectional Encoder Representations from Transformers)について ※1
BERTはTransformerというモデルを元とした双方向エンコーダーで構成された事前学習モデルです。
事前学習では単語や文章の表現を学習したパラメータ(重み)の情報のみ持つため単体では何もできません。
BERTのパラメータがどのような構成になるのかが基礎となるため、まずはTransformer、そしてエンコーダーについてご紹介差し上げたいと思います。
Transformerとは※2
Transformerは機械翻訳を目的として提唱されたエンコーダデコーダモデルです。
エンコーダデコーダモデルとはエンコーダという機構で系列内のトークンが持つ関係性や文の表現を捉えその情報を入力にデコーダという機構で変換後の系列を推論するモデルです。
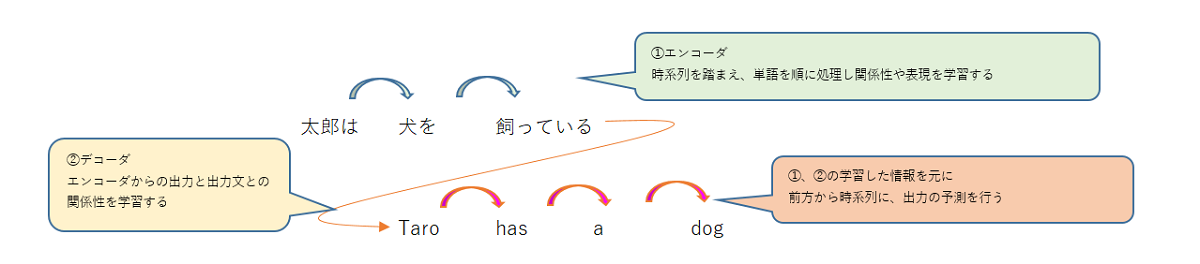
Transformerが提唱される以前は、系列を前方から順に数珠繋ぎに計算する手法が主流で計算に掛かる時間がネックとなっていました。
これを解決するため、Transformerではエンコーダー、デコーダーの両方でPosition Encodingという仕組みを用いて単語の位置・時系列の情報を、Attentionと呼ばれる仕組みを用いて単語間の照応関係(二つの単語が互いに関係性を持っている事)の情報を文単位に学習すると共に演算処理を並列化可能とすることで学習時間の短縮を実現した手法です。
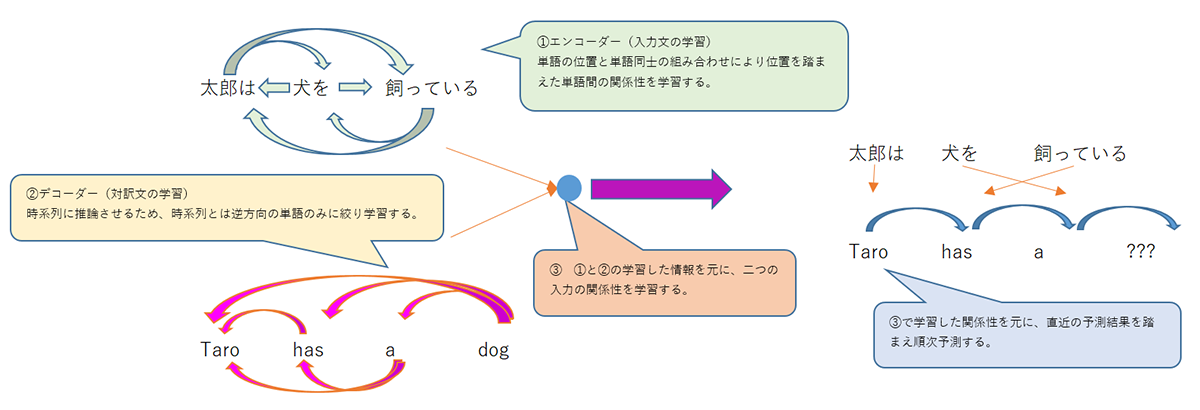
BERTはTransformerのエンコーダー部分を複数重ねたモデルで、学習を時系列方向とその逆方向の双方向で行うモデルです。
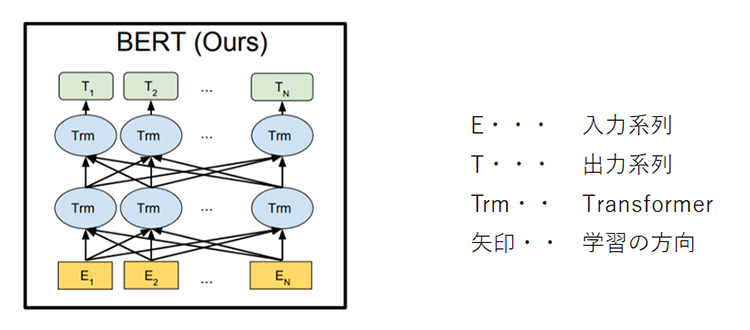
https://arxiv.org/pdf/1810.04805.pdfより引用
BERTはWikipediaなどの大規模データを元にした事前学習と、タスク(機械翻訳や質問応答、固有表現抽出など推論を行う種類)に合わせたファイン・チューニング(既存モデルの一部を変更したモデル作成)の2段階の学習を行います。
BERTの事前学習
BERTの事前学習では「穴埋め問題を解かせる学習」と「二つの系列が連続したものか判定する学習」の2つの学習により系列内のトークンについての学習と系列間の関係性についての学習を行います。
これにより、質疑応答のような複数の系列を用いるタスクや固有表現抽出のような系列内の単語に対するタスクの両方に対応するモデルとなります。
穴埋め問題を解く学習(Masked Language Modeling (MLM))
系列内の15%のトークンを穴埋め問題の対象に設定。そのうち、一定の割合で3つの加工基準を適用し元のトークンを推論するよう学習させます。
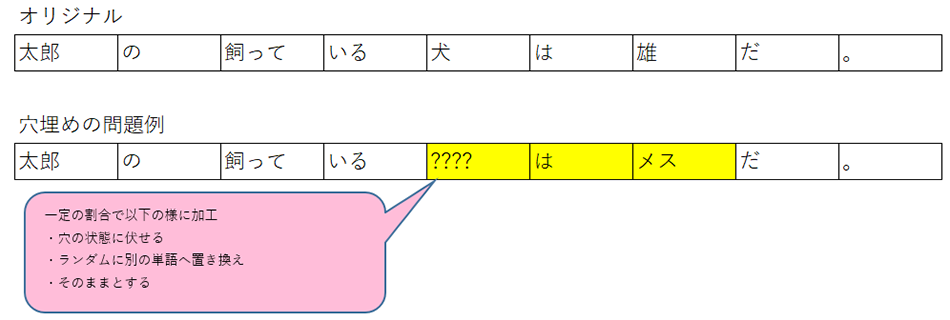
この学習により、前後の文脈に基づいて対象となったトークンの本来の意味を予測するよう学習し単語分散表現を獲得します。
二つの系列が連続したものか判定する学習(Next Sentence Prediction (NSP))
学習データの約半数を2系列が連続したもの、残りを不連続なものとし連続/不連続を当てるよう学習します。

この学習により、前後の文の等価性や連続性を獲得します。
これら学習により、事前学習済みモデルは前回のWord2Vecのような分散表現と以下のタスクに対応した機能の土台を持つモデルとして生成されます。
- Sentence Pair Classification
- 言い換え文評価や類似文評価など、2文の等価性を導出するタスク
- Single Sentence Classification
- 感情分析や文章の自然さ評価など、1文を分類するタスク
- Question Answering
- 読解力を要する質問応答タスク
- Single Sentence Tagging
- 固有表現抽出など、トークンのタグ付けを行うタスク
ファイン・チューニング
BERTでは事前学習獲得した単語の意味・表現や文の関連性を元に、ファイン・チューニングでモデルの入出力部分を変更し各タスクに対応したモデルを生成します。
固有表現抽出では入力に対する出力をBIOタグ(Begin=開始、Inside=途中、Outside=対象外の識別子を伴うタグ)などのラベルとして学習させることで、単語を予測するモデルをラベルを予測するモデルへと変更していきます。
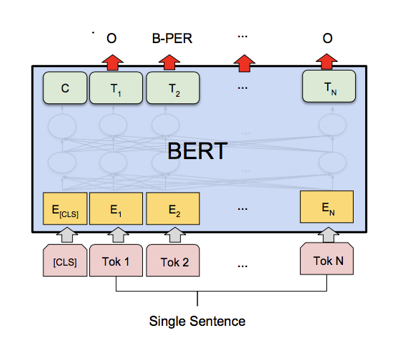
日本語版BERTを利用した固有表現の取り組み
BERTは学習を並列化可能としたことで時間の短縮が可能なりましたが、大きなメモリー、GPU/TPUといった強力なコンピュータリソースの元で学習しなくては多大な時間を要してしまうという側面もあります。
Transformerを提唱したGoogleにより多言語対応した事前学習済みモデルが公開されているのですが、漢字が1文字単位にトークン化され熟語が存在しないことから、固有名詞などの意味を捉えるのは難しいかもしれません。
Google以外にも、企業や研究機関が日本語の文書を元に事前学習を行ったモデルを提供しているため言語以外にもトークン化の基準やモデルのサイズ(モデルが持つパラメータ数)を勘案し選定を検討します。
また、BERTでの固有表現抽出では前回のCRFのように出力トークンの全体で最適解を求めるのではなくトークンそれぞれで最適解を求めるためBIOタグの「Bの次にIが続く」といった構造的な判定に弱い部分があります。
そのため、出力部分の計算方法についても検討する必要が有ります。
データセットの前処理について
BERTでは前回取り扱ったCRFと同様に文をトークン化し取り扱います。
トークン化の方法としては、前回の結果と比較できるよう形態素解析器としてSudachiを使用したいと思います。
学習・推論の実施についてはHuggingFace社が提供するBERTのフレームワークを元に実施するため※3フレームワークに合わせてデータセットをトレーニングデータ・バリデーションデータ・テストデータの3つに分割し取り扱います。
| トレーニングデータ | モデルがパラメータを獲得するため学習させるデータ |
|---|---|
| バリデーションデータ | モデルの学習プロセスの決定や学習状況の確認に使用する確認用データ |
| テストデータ | 学習したモデルが最終的な推論結果を出す検証データ |
BERTの事前学習モデル選定
今回の固有表現抽出の取り組みでは、東北大学で事前学習を行い公開されている※3日本語版BERTのLARGEサイズ(パラメータ数が多いモデル)を用いて固有表現抽出に取り組みたいと思います。
東北大学のBERTモデルは、トークン化の単位(形態素/文字)やパラメータ数により複数種類のモデルが公開されています。
これまでの取り組みではMeCab、Sudachiといった形態素解析器を用いて予測を行ってきたため、トークン化の単位は形態素単位とし、パラメータ数の大きさにより単語の表現力も広がる事からパラメータ数が大きいモデルを利用したいと思います。
固有表現抽出の精度向上に向けた出力部分の計算方法について
固有表現抽出におけるBERTの出力部分については、上記の様にCRFのような構造的な判定の弱点からBERTの出力部分にCRFを用いてラベルを学習させることで構造的な判定を組み込む事もできますが筆者の過去の経験ではCRFを組み込む事によりラベルの予測数が少なくなったこともあり、抽出する対象に合わせて実証しなくてはならないものと考えます。
今回の取り組みでは、BERTの出力部分にCRFを用いるのではなく、交差検証(cross-validation)による多数決で最終的な推論を決定したいと思います。
交差検証は、同一のデータセットでトレーニングデータとテストデータを組み替えて行う事によりモデルの汎用性を評価するための検証方法です。
今回の取り組みでは、テストデータを共通としトレーニングデータとバリデーションデータを組み替えて学習した5つのモデルを準備。この5つのモデルによる多数決で推論を決定する事で汎用性を持たせたいと思います。
データ分割イメージ
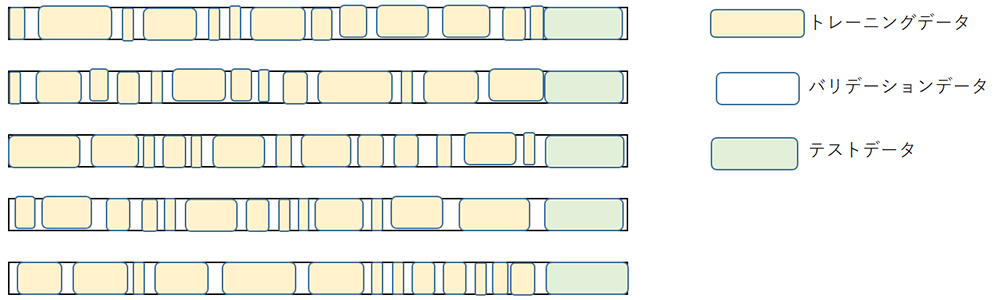
※トレーニングデータ、バリデーションデータの量は比率で決定し対象はランダムで決定する事とします。
BERTとHugginface製フレームワークによる情報抽出サンプル
東北大学にて公開されている日本語BERTモデルは2020年に公開されており、モデルの公開時期に合わせたHuggingfaceのTransformerフレームワークを用いるためTransformesのバージョン3.5.0をベースにスクリプト類を記載しております。
前処理(データセットの加工・調整)
import os
from time import time
import json
from transformers import AutoTokenizer
from sklearn.model_selection import train_test_split
def save_jsonl_file(file_name, jsonl):
with open(file_name,"w", encoding="utf8") as f:
for json_data in jsonl:
json_text = json.dumps(json_data,ensure_ascii=False)
f.write(json_text + "\n")
class TextTokenizer:
def __init__(self):
from sudachipy import tokenizer
from sudachipy import dictionary
self.tokenizer_obj = dictionary.Dictionary().create()
self.tokenizer_mode = tokenizer.Tokenizer.SplitMode.A
def _tokenize(self, text):
return self.tokenizer_obj.tokenize(text, self.tokenizer_mode)
# 形態素解析し、形態素情報配列を返却
def extract_tokens(self, text):
result = []
if not text: return result
# Sudachiによる形態素解析を実施
tokens = self._tokenize(text)
text_pos = 0
for token in tokens:
# 表層・スパンを結果として格納
if len(token.surface().strip()) > 0:
result.append({"surface": token.surface(), "span": [text_pos, text_pos + len(token.surface())]})
text_pos += len(token.surface())
return result
class DataSetConverter(object):
def __init__(self, origin_file, priprocessed_file):
texts = []
if os.path.exists(priprocessed_file):
with open(priprocessed_file, "r", encoding="utf-8") as f:
for line in f.readlines():
line = json.loads(line)
texts.append(line)
else:
# 形態素解析等、前処理加工を実施
texts = self._preprocessing(origin_file)
# 前処理済みデータを保存
save_jsonl_file(priprocessed_file, texts)
self.texts = texts
# データセット JSONファイルの前処理
# 形態素解析し、トークンとして加工する
def _preprocessing(self, json_file):
result = []
# 前処理済みファイルが無い場合はオリジナルを読み込み
# 形態素解析によるトークン化を準備
tokenizer = TextTokenizer()
# データセットをロード
with open(json_file,"r", encoding="utf8") as f:
jsons = json.load(f)
for j in jsons:
# 文を形態素解析し結果を取得
tokens = tokenizer.extract_tokens(j["text"])
for i, token in enumerate(tokens):
# BIOタグの初期値としてOを設定
token["tag"] = "O"
# 正解(法人名)、不正解(法人名以外)のラベル情報を準備
j["correct"], j["incorrect"] = [], []
# データセットのラベル付けを元に、正解、不正解のBIOタグを付与
for e in j["entities"]:
bio_items = []
for token in tokens:
if e["span"][0] <= token["span"][0] and e["span"][1] >= token["span"][1]:
bio_items.append(token)
# 法人名、法人名以外のタグ分けします
if len(bio_items) > 0 and bio_items[0]["span"][0] == e["span"][0] and bio_items[-1]["span"][1] == e["span"][1]:
label_kind = ("correct" if e["type"] == "法人名" else "incorrect")
for i, token in enumerate(bio_items):
token["tag"] = ("B" if i == 0 else "I") + "-" + label_kind
# 正解、不正解ラベル情報を保持
j[label_kind].append({"name": e["name"], "span": e["span"]})
j["tokens"] = tokens
# トークン化&BIOタグ付与し結果を格納
result.append(j)
return result
def set_test(self):
# 学習データ+検証データ 9割、 テストデータ 1割に分割
self.train_dev_texts, self.test_texts = train_test_split(self.texts, test_size=0.1)
def set_train_valid(self):
# 学習データと検証データを8:2に分割
self.train_texts, self.valid_texts = train_test_split(self.train_dev_texts, test_size=0.2)
t0 = time()
print("Load DataSets ")
# データセットロード
dc = DataSetConverter("./ner.json", "./ner_preprocessed.json")
# 交差検証用に複数のデータセットとして保存
# 学習・検証・テストデータに分割
data_root_dir = "./datas/"
set_cnt = 5
max_tokens = 128
bert_model = "./model/bert/cl-tohoku/bert-large-japanese"
tokenizer = AutoTokenizer.from_pretrained(bert_model)
def dataset_save(texts, filename, format="txt"):
# original json
save_jsonl_file(filename + ".jsonl", texts)
# dataset
if format == "txt": # text形式
with open(filename + ".txt", "w", encoding="utf-8") as f:
datas = []
def add_data(tokens, tags):
for token, tag in zip(tokens, tags):
datas.append(token + " " + tag)
datas.append("")
for text in texts:
subwords_len = 0
tokens, tags = [],[]
for token in text["tokens"]:
tokens.append(token["surface"])
tags.append(token["tag"])
sw_len = len(tokenizer.tokenize(token["surface"]))
if subwords_len + sw_len > max_tokens:
add_data(tokens, tags)
tokens, tags, subwords_len = [], [], 0
add_data(tokens, tags)
for data in datas:
f.write(data + "\n")
elif format == "json": # json形式
with open(filename + ".json", "w", encoding="utf-8") as f:
datas = []
def add_data(tokens, tags):
datas.append(json.dumps({"tokens": tokens, "tags": tags}, ensure_ascii=False))
for text in texts:
subwords_len = 0
tokens, tags = [],[]
for token in text["tokens"]:
tokens.append(token["surface"])
tags.append(token["tag"])
sw_len = len(tokenizer.tokenize(token["surface"]))
if subwords_len + sw_len > max_tokens:
add_data(tokens, tags)
tokens, tags, subwords_len = [], [], 0
add_data(tokens, tags)
for data in datas:
f.write(data + "\n")
# 全体の1割をテストデータとして設定
dc.set_test()
for i in range(set_cnt):
# 異なる組み合わせの学習・検証データセットを作成
dc.set_train_valid()
train_texts = dc.train_texts
valid_texts = dc.valid_texts
test_texts = dc.test_texts
data_dir = os.path.join(data_root_dir, str(i))
if not os.path.exists(data_dir): os.makedirs(data_dir)
dataset_save(train_texts, os.path.join(data_dir, 'train'))
dataset_save(valid_texts, os.path.join(data_dir, 'dev'))
dataset_save(test_texts, os.path.join(data_dir, 'test'))
duration = time() - t0
print(f"done in {duration:.1f}sec")
学習・推論
#! /bin/bash MAX_LENGTH=128 BERT_MODEL=./model/bert/cl-tohoku/bert-large-japanese DATASET_DIR_ROOT=./datas OUTPUT_DIR_ROOT=./fine-tuning_model BATCH_SIZE=32 NUM_EPOCHS=8 SAVE_STEPS=750 SEED=1 MAX_DATASET_NO=4 for i in $(seq 0 $MAX_DATASET_NO); do DATASET_DIR="$DATASET_DIR_ROOT/$i" OUTPUT_DIR="$OUTPUT_DIR_ROOT/$i" LOG_FILE="$OUTPUT_DIR_ROOT/train_$i.log" python run_ner_old.py \ --task_type NER \ --data_dir $DATASET_DIR \ --labels ./labels.txt \ --model_name_or_path $BERT_MODEL \ --output_dir $OUTPUT_DIR \ --max_seq_length $MAX_LENGTH \ --num_train_epochs $NUM_EPOCHS \ --per_gpu_train_batch_size $BATCH_SIZE \ --save_steps $SAVE_STEPS \ --seed $SEED \ --do_train \ --do_eval \ --do_predict \ --overwrite_output_dir&> $LOG_FILE done
後処理(5つのモデルの結果結合、及び精度算出)
import os
import json
from collections import Counter
import sklearn_crfsuite
from sklearn_crfsuite import metrics
# 入力データセットのトップディレクトリ
input_base_dir = "./datas"
# モデル&推論結果出力のトップディレクトリ
result_base_dir = "./fine-tuning_model"
# 交差検証パターン数
test_patterns = 5
# 入力テストデータ(JSON)のロード
input_jsons = None
input_dir = os.path.join(input_base_dir,"0")
with open(os.path.join(input_dir, "test.jsonl"), "r", encoding="utf-8") as f:
lines = f.readlines()
input_jsons = [json.loads(line) for line in lines]
for jsn in input_jsons:
jsn["sub_predict"] = [[] for i in range(test_patterns)]
# ラベル一覧のロード
with open("./labels.txt", "r", encoding="utf-8") as f:
tags = [line.strip() for line in f.readlines()]
# 5つの検証パターンの推論結果をロードする
for i in range(test_patterns):
# 出力結果のロード
result_dir = os.path.join(result_base_dir,str(i))
with open(os.path.join(result_dir, "test_predictions.txt"), "r", encoding="utf-8") as f:
lines = f.readlines()
predict_labels = []
labels = []
for line in lines:
if line.strip():
# 予測ラベルを格納
labels.append(line.split(" ")[1].strip())
else:
# 空白行が文の切れ目
predict_labels.append(labels)
labels = []
assert len(input_jsons) == len(predict_labels)
# 各入力情報に推論ラベル情報を組み込む
for jsn, labs in zip(input_jsons, predict_labels):
assert len(jsn["tokens"]) == len(labs)
jsn["sub_predict"][i].extend(labs)
# 各検証パターンで精度を算出する
for i in range(test_patterns):
pred, gold = [], []
for jsn in input_jsons:
gold.append([token["tag"] for token in jsn["tokens"]])
pred.append(jsn["sub_predict"][i])
print(f"pattern [{i}]")
f1 = metrics.flat_f1_score(gold, pred, average='weighted', labels=tags)
print("f1-score:" + str(f1))
print(metrics.flat_classification_report(
gold, pred, labels=tags, digits=3
))
# 多数決で各トークンのラベルを決定する
pred, gold = [], []
for jsn in input_jsons:
for i , token in enumerate(jsn["tokens"]):
cnt = Counter([pred[i] for pred in jsn["sub_predict"]])
token["predict"] = cnt.most_common()[0][0]
gold.append([token["tag"] for token in jsn["tokens"]])
pred.append([token["predict"] for token in jsn["tokens"]])
print(f"Majority vote")
f1 = metrics.flat_f1_score(gold, pred, average='weighted', labels=tags)
print("f1-score:" + str(f1))
print(metrics.flat_classification_report(
gold, pred, labels=tags, digits=3
))
# 推論結果をスパンに変換し反映
for jsn in input_jsons:
jsn["pred_correct"], jsn["pred_incorrect"] = [], []
spans = []
last_tag = ""
def add_pred(tag, sp):
span = [sp[0]["span"][0], sp[-1]["span"][1]]
name = jsn["text"][span[0]:span[1]]
jsn["pred_" + tag].append({"name": name, "span": span})
for token in jsn["tokens"]:
bio, tag = token["predict"][0], token["predict"][2:] if token["predict"][0] in ["B", "I"] else ""
if (bio == "O" or bio == "B" or tag != last_tag) and len(spans) >0:
add_pred(last_tag, spans)
spans, last_tag = [], ""
if (not len(spans) and bio== "B") or (len(spans) and bio == "I" and last_tag == tag) :
spans.append(token)
last_tag = tag
if len(spans) > 0:
add_pred(spans)
# 抽出結果の精度確認
print("精度算出 start")
TP1, FP1, TN1, FN1 = 0, 0, 0, 0
TP2, FP2, TN2, FN2 = 0, 0, 0, 0
for sentence in input_jsons:
# 企業名予測についての算出
# 企業名を正しく企業名として予測した結果をえり分け
true_positive1 = [p for p in sentence["pred_correct"] if p in sentence["correct"]]
# 企業名と予測したが企業名ではなかった結果をえり分け
false_positive1 = [p for p in sentence["pred_correct"] if p not in sentence["correct"]]
# 企業名を企業名と予測できなかった対象をえり分け
false_negative1 = [p for p in sentence["correct"] if p not in sentence["pred_correct"]]
# 企業名以外を企業名以外と予測できた対象をえり分け
true_negative1 = [p for p in sentence["pred_incorrect"] if p not in sentence["correct"]]
# True Positive = 企業名を正しく企業名と予測できた件数
TP1 += len(true_positive1)
# True Negative = 企業名以外を企業名でないと予測できた件数
TN1 += len(true_negative1)
# False Negative = 企業名である固有表現を企業名でないと予測した件数
FN1 += len(false_negative1)
# False Positive = 企業名を企業名と予測できなかった件数
FP1 += len(false_positive1)
sentence["true_positive1"] = true_positive1
sentence["true_negative1"] = true_negative1
sentence["false_negative1"] = false_negative1
sentence["false_positive1"] = false_positive1
# 企業名以外の固有表現についての算出
# 企業名以外を正しく企業名以外として予測した結果をえり分け
true_positive2 = [p for p in sentence["pred_incorrect"] if p in sentence["incorrect"]]
# 企業名以外を企業名として予測した結果をえり分け
false_positive2 = [p for p in sentence["pred_incorrect"] if p not in sentence["incorrect"]]
# 企業名以外を企業名以外と予測できなかった対象をえり分け
false_negative2 = [p for p in sentence["incorrect"] if p not in sentence["pred_incorrect"]]
# 企業名を企業名以外でないと予測できた対象をえり分け
true_negative2 = [p for p in sentence["pred_correct"] if p not in sentence["incorrect"]]
# True Positive = 企業名以外の固有表現を正しく企業名以外の固有表現と予測できた件数
TP2 += len(true_positive2)
# True Negative = 企業名を企業名以外の固有表現でないと予測できた件数
TN2 += len(true_negative2)
# False Negative = 企業名以外の固有表現を企業名以外の固有表現と予測できなかった件数
FN2 += len(false_negative2)
# False Positive = 企業名以外の固有表現を企業名と予測した件数
FP2 += len(false_positive2)
sentence["true_positive2"] = true_positive2
sentence["true_negative2"] = true_negative2
sentence["false_negative2"] = false_negative2
sentence["false_positive2"] = false_positive2
# 精度をコンソールに出力
print("企業名")
print("TP:{},FP:{},TN:{},FN:{}".format(TP1, FP1, TN1, FN1))
print("Accuracy:{}".format((TP1 + TN1) / (TP1 + TN1 + FP1+ FN1)))
print("Precision:{}".format(TP1 / (TP1 + FP1)))
print("Recall:{}".format(TP1 / (TP1 + FN1)))
print("企業名以外")
print("TP:{},FP:{},TN:{},FN:{}".format(TP2, FP2, TN2, FN2))
print("Accuracy:{}".format((TP2 + TN2) / (TP2 + TN2 + FP2+ FN2)))
print("Precision:{}".format(TP2 / (TP2 + FP2)))
print("Recall:{}".format(TP2 / (TP2 + FN2)))
# 結果をファイルに保存
with open('./result.json', 'w', encoding="utf8") as f:
json.dump(input_jsons, f, indent=4, ensure_ascii=False)
抽出結果の評価
BERTでの抽出結果も前回のCRFと同様にBIOタグによるラベル表現です。
第一回から取り上げておりますデータセットには、法人名や人名、地名などがラベルとして含まれておりますので本コラムでは法人名のラベルを「企業名」、法人名以外のラベルを「企業名以外」として定義します。
評価方法は前回と同様にBIOタグ単位での評価と、これを結合し最終的なラベル範囲へ変換した結果で行いたいと思います。
1 BIOタグによる性能評価
〇性能評価
まず、BIOタグそれぞれでの予測性能を評価したいと思います。
評価方法は前回にも取り上げた混同行列とし正負のそれぞれで評価します。
今回は学習データの組み合わせが異なる5つのモデルを生成し推論を行いましたので以下の基準で推論結果を集約・集計したいと思います。
- ①5つのモデルでの推論結果をトークン単位で多数決を取り全体での推論結果として集約。この推論結果で評価を行う。
- ②5つのモデル毎の推論結果を評価し、この評価結果の平均を5つのモデル全体での評価結果とする。
| ① | ② | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 正(B) | 正(I) | 負(B) | 負(I) | O | 正(B) | 正(I) | 負(B) | 負(I) | O | |
| 適合率(Precision) | 0.962 | 0.969 | 0.936 | 0.959 | 0.996 | 0.942 | 0.956 | 0.938 | 0.956 | 0.995 |
| 再現率(Recall) | 0.9 | 0.913 | 0.976 | 0.973 | 0.993 | 0.902 | 0.916 | 0.967 | 0.968 | 0.993 |
| 正解率(Accuracy) | 0.987 | 0.9858 | ||||||||
凡例:
- 正(B)・・・企業名の開始位置
- 負(B)・・・企業名以外の開始位置
- O・・・対象外
- 正(I)・・・企業名の途中位置
- 負(I)・・・企業名以外の途中位置
企業名であると予測し実際に企業名であった推測については①で約96%程が正解であり②で約95%程が正解となりました。
企業名以外のタグについては両方とも約94%が正解できほぼ僅差の状況です。
予測に対する正解率としては①が高く、学習データの組み合わせによりある程度差異は出るものの単体のモデル毎の弱点を少しずつ補完するような結果に繋がっていると考えられます。
多数決で企業名/企業名以外の改善ができた部分もありますが、BERTでの予測で今回のデータセット上難しいと筆者が感じられたものは「NHK」という表記です。
次の誤り分析でどのようなデータ構成で誤りがあったのか見ていきたいと思います。
〇誤り分析
BERTでの推論で特徴的だと思われた「NHK」という表記の推論について、データセット中のラベル割り当て状況と併せて分析したいと思います。
- データセット内での「NHK」の表記がある文例 赤字:企業名、青字:企業名以外
-
- 格助詞、主格など法人体としての表記
NHKを退きフリーとなるが、一時は資金を得るために借金をしなければならないほど苦しい生活を送っていた。
「あ・うん」は、1980年3月9日から3月30日までNHKで放送された向田邦子脚本のテレビドラマ。
NHKの「みんなのうた」テレビ放送では、曲に合わせた、くまのぬいぐるみ劇のアニメーションが放送された。 - 団体名だが、企業名以外(その他団体)とされる表記
その後、桐朋学園大学に入学するも、1964年に中退してNHK交響楽団に入団し首席奏者となる。
2015年4月の人事異動で、地元NHK仙台放送局へ異動。
※「NHK」、「仙台放送局」それぞれで企業名以外の異なるラベルが付いています。 - NHK主催のイベントや制作番組名などで企業名でないとされる表記
NHKスペシャル「1000人に聞くハケンの本音」で、脚本家の中園ミホと意見が対立。
1979年のNHK杯では7位となる。
番組の企画者は、「NHK紅白歌合戦」も企画立案したNHK音楽部のプロデューサー、三枝嘉雄。 - 格助詞が省略されているのか、制作物なのか不明瞭な表記
2001年公開の映画「ウォーターボーイズ」の佐藤勝正役で注目を浴び、2003年のNHK朝ドラ「こころ」でヒロインが恋心を抱く花火職人を演じ広く認知される。
ヒロインの人選は「マッサン」と同様に、17歳から33歳までと事実上の年齢制限を設けた公募オーディションが行われ、2015年3月12日、NHK大阪放送局での記者会見で波瑠に決定したと発表された。
- 格助詞、主格など法人体としての表記
格助詞が含まれるケースなどは法人名・企業体であるという事は読み取れますが、イベントや制作番組であるケースとイベント・制作番組のようだが企業名とされるケースは人が見ても不明瞭な部分が多く判断がなかなかつかないと思います。
上記の「NHK大阪放送局」の例では「NHK」が企業名以外のラベルと予測されました。
| 予測ラベル | 負(B) | 負(B) | 負(I) | 負(I) | O |
|---|---|---|---|---|---|
| 正解ラベル | 正(B) | 負(B) | 負(I) | 負(I) | O |
| トークン | NHK | 大阪 | 放送 | 局 | で |
学習データには「地元NHK仙台放送局」の例があるので、これに習っているための誤りと考えられます。
また、この例での5つのモデルの評価としては1:4で「企業名の開始」より「企業名以外の開始」が多数派という結果となったためデータの母数やそのパターンによっては正解できる例でもある例です。
このように、Attention機構自体が前後の文脈から単語の意味を捉え、その情報を元にタグの推論が行われるため文脈としての意図を捉えているような推論ができるという特色が出た例ではないでしょうか。
2 最終的な抽出結果による評価
〇性能評価
前回の結果との比較のためにも、基準を合わせるため①企業名の予測と②企業名以外の固有表現の予測の2つの軸で性能評価を行いたいと思います。
混同行列の計算基準としては完全一致をベースに、以下のような判定基準となります。
| ①企業名の予測 | ②企業名以外の固有表現の予測 | |
|---|---|---|
| TP(対象を対象として正しく予測できたか) | ①を正しく①と予測できた | ②を正しく②と予測できた |
| TN(対象外を対象外として正しく予測できたか) | ②を①以外と予測できた | ①を②以外と予測できた |
| FN(対象を誤って対象外と予測したか) | ①を①と予測できなかった | ②を②と予測できなかった |
| FP(対象外を誤って対象と予測したか) | ①以外を①と誤って予測した | ②以外を②と誤って予測した |
この計算基準で前回と同様に正解率、適合率、再現率を正負の両方でスコアリングしてみます。
混同行列
| TRUE | FALSE | |
|---|---|---|
| Positive | 222 | 13 |
| Negative | 29 | 1176 |
| TRUE | FALSE | |
|---|---|---|
| Positive | 1095 | 99 |
| Negative | 51 | 230 |
スコア
| ① | ② | |
|---|---|---|
| 正解率(Accuracy) | 0.971 | 0.898 |
| 適合率(Precision) | 0.945 | 0.917 |
| 再現率(Recall) | 0.888 | 0.955 |
企業名と予測し実際に企業名であった割合(正解率)は97.1%、企業名を取りこぼさず当てられた割合(再現率)は88.4%と前回のCRFと比較し正解率で約8%、再現率で約28%良い結果となりました。
企業名以外の固有表現を当てられた割合は②の適合率、再現率となりますがこちらも前回より高い結果となりました。
前回のCRF、今回のBERT両方共通して、企業名の当てられた割合より、企業名以外の固有表現とした対象の当てられた割合が少ないという結果になりました。
今回「企業名以外の固有表現」とした対象は人名、地名など複合的なラベル構成です。パターン認識という観点から、入力されたトークンが様々な意味/パターンを持つ複合的なラベルより、1つの限定されたドメインや意味を持つラベルを予想する方が的中する確率が高くなる傾向があると考えられます。
〇誤り分析
BIOタグでの誤り分析については対象を対象外としてしまったNHKの例を取り上げましたので、対象外を対象と余ってしまった例を取り上げたいと思います。
- 正論:
- 2018年6月1日、岡本製作所はラクテンチの事業を株式会社ラクテンチに会社分割し、株式会社ラクテンチは
地元でガソリンスタンドなどを展開する西石油グループに事業譲渡された。 - 推論:
- 2018年6月1日、岡本製作所はラクテンチの事業を株式会社ラクテンチに会社分割し、株式会社ラクテンチは
地元でガソリンスタンドなどを展開する西石油グループに事業譲渡された。
- 赤:企業名
- 青:企業名以外の固有表現
上記の予測例では「ラクテンチ」が企業名以外(データセット上では「製品名」のラベル)ですが企業名として予測されました。
こういった表記はかなり難しく、「~の事業を」と「会社分割し」といった文脈から読み取らなくては「ラクテンチ」が事業体ではなく事業そのものであると認識する事は難しいと思われます。
トレーニングデータとして発生する近い文章も「ウェスタン・デジタルの事業規模拡大に伴って~」など事業体を表すものが多く係り受けなどの構文解析を用いない事には正確に予測する事は難しいでしょう。
BERTによる固有表現抽出という取り組みについて
最終的な評価として、「企業名」と予測し正解できた確率は97%、「企業名」とされた正解のうち88%を抽出する事ができました。
BERTが発表されたされた際には、様々なタスクで人の認識を超える予測を出すなど驚異的な結果を残し、今回の取り組みでも「株式会社ラクテンチ」の例の様に一見したら人でも見間違えてしまうような箇所の不正解のみとなる驚異的な精度がでる手法です。
前回のCRFでも単語のベクトル(分散表現)として周辺語により学習を行うWord2Vecを扱いましたが、文内の単語の位置・関連性を元に文脈を踏まえ学習するBERTのベクトルが精度に寄与しているのではと考えられます。
今回の取り組みではBERTが持つ分散表現を元にベースとなる手法で予測を行いましたが、出力結果をルールベースで加工する事もファインチューニング時の出力処理に別の情報を組み込む事も可能なため更に対象とするデータセットに合わせたモデルを目指す事も可能かと考えられます。
最後に
今回は「NDIL バックオフィスNLP」で採用している深層学習手法のBERTを取り扱いました。
BERTのベースとなる機能を用いるのみでも高い精度での抽出が可能となりましたが、弊社製品ではお客様のタスクや解決したいテーマに向け、手法・機能の追加や組み換えを行う事で業務における知識の獲得に貢献できるよう尽力させて頂いております。
弊社製品にご興味を持たれましたら、お声がけ戴けますと幸いです。