
















NER(固有表現抽出)始めませんか? 第2回
前回のおさらい
本コラム第1回では、固有表現抽出データセットを対象としたルールベース・探索による取り組みをご紹介いたしました。
第2回では前回の手法で提起させて頂いた「膨大なルールとその構築についての困難さ」の解決に向け「統計/探索モデル」を用いた第二世代AIでの取り組みについてご紹介差し上げたいと思います。
統計/探索モデルとは?
まずは、統計/探索モデルとは?からご説明したいと思います。
統計/探索モデル
収集したデータを統計/確率の観点から分析しデータの背景にある事象を説明、抽出、探索を行う手法。
回帰分析やベイズ推定といった統計的なアプローチ、最短経路探索や確率的探索法など探索的なアプローチがあります。
気象庁が研究しているウェザーマーチャンダイジングでは「アイスクリームの販売数が急激に伸びるのは気温が25度を超える時」というように、ある事象の発生が他の事象の因果関係にあるという事例があります。※1
データを分析する事でこのようなデータの背景にある事柄を導出する、事象間の因果関係を探索し抽出するという手法になります。
今回は固有表現抽出への取り組みとして、探索的手法となるLinear-chain CRF(Conditional Random Fields:条件付き確率場)を取り扱いたいと思います。
Linear-chain CRFは系列ラベリング問題を解く手法であり、最短パス(一番もっともらしい経路)を探索する経路探索モデルに分類されます。
前回のコラムでご紹介したMeCabでも形態素解析時に用いるコスト(発生しやすさ)を導出するために使用されるなど幅広く使われている手法です。
系列ラベリング問題とは?
系列=入力文の各単語に対してラベリングを行う問題。
文内の単語に対して固有表現や品詞等、タグ付けを行いこれを推定する問題設定です。
CRF(Linear-chain CRF)について※2
CRF(Linear-chain CRF)は、構造学習により系列とラベルの関係を学習し、系列にマッチする分類結果を推論する識別モデルです。
構造学習とは?
データを予測する単位で分割し入力とするのではなく、全体でひとまとめとして入力。
ひとまとめ全体で最適な結果を求めるよう学習する事です。
識別モデルとは?
データを分類する分類問題に対して、"この動物は猫か犬か"という単純な分類結果を出すのではなく"猫である確率が0.6、犬である確率が0.4"など確率を導出するモデルです。
CRFでの学習と推論についてどのようなものになるのか、イメージと併せてご説明したいと思います。
例えば以下のように、文章へ人名、場所、イベントの3タイプの固有表現が付与されていたとします。
岸田総理人名は4日日付総選挙イベントを表明。
これを形態素解析によりトークン(系列内の個々のデータ)として分割します。(形態素解析にはSudachiを使用しています)※3
| ラベル | 人名 | 人名 | 無し | 日付 | 日付 | 無し | イベント | イベント | 無し | 無し | 無し |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 形態素 | 岸田 | 総理 | は | 4 | 日 | 、 | 総 | 選挙 | を | 表明 | 。 |
| 品詞 | 名詞 | 名詞 | 助詞 | 名詞 | 接尾辞 | 補助記号 | 接頭辞 | 名詞 | 助詞 | 名詞 | 補助記号 |
これに対し、複数の関数でトークンとラベルを元に文をベクトル化します。
素性としては単一のトークンを用いた観測素性、前後のトークンの組み合わせを用いた遷移素性を用います。
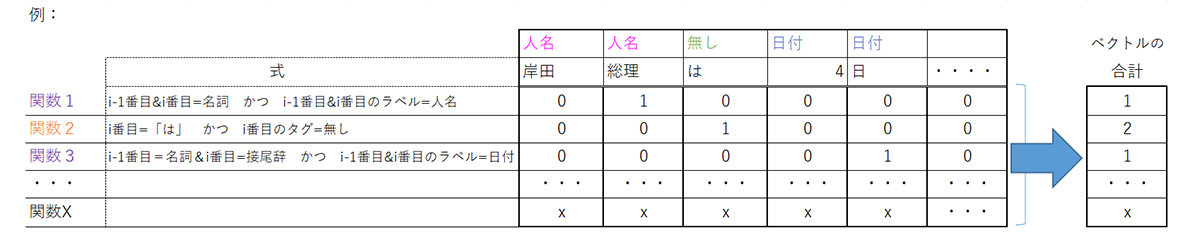
上記の様にラベルとトークンを元に関数で求めたベクトルの合計を素性ベクトルと呼び、トークン全体でのデータとなります。
CRFでは入力されるトークンが持つ属性(上記の例では表層、品詞)により素性関数を構築、関数で得られたベクトルによりどの関数を優先すべきかという重み(重要度=係数)を学習します。

系列全体で最適に予測できるよう学習・予測をする事になるのですが、CRFは計算の高速化のため以下の条件を元にトークン毎の確率の和を全体の確率とするよう学習と推論を行います。
条件:各位置のトークンについて、同位置+一つ前のラベルを組み合わせ素性関数を用いて素性を求めた場合そのベクトルを全トークンで合計すると素性ベクトルと等価になる。
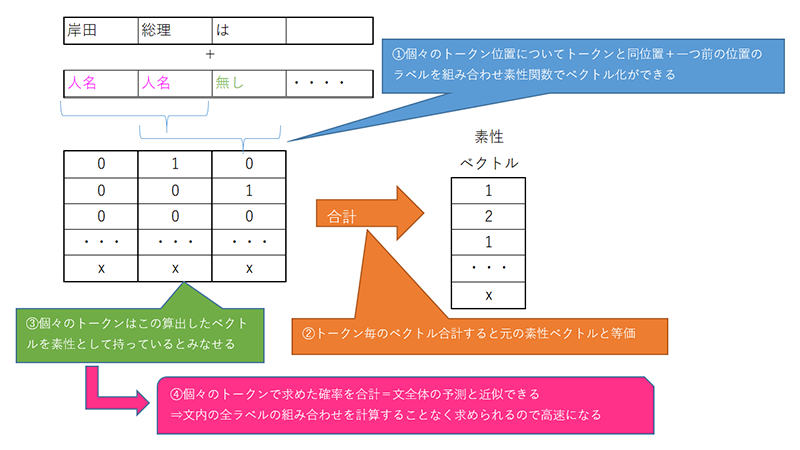
学習では文と正解ラベル一覧の多数の組を元に、トークンのベクトル(素性)が一番正解ラベルに近づくよう重み(タグ毎の確率計算の係数)を算出する事で行います。
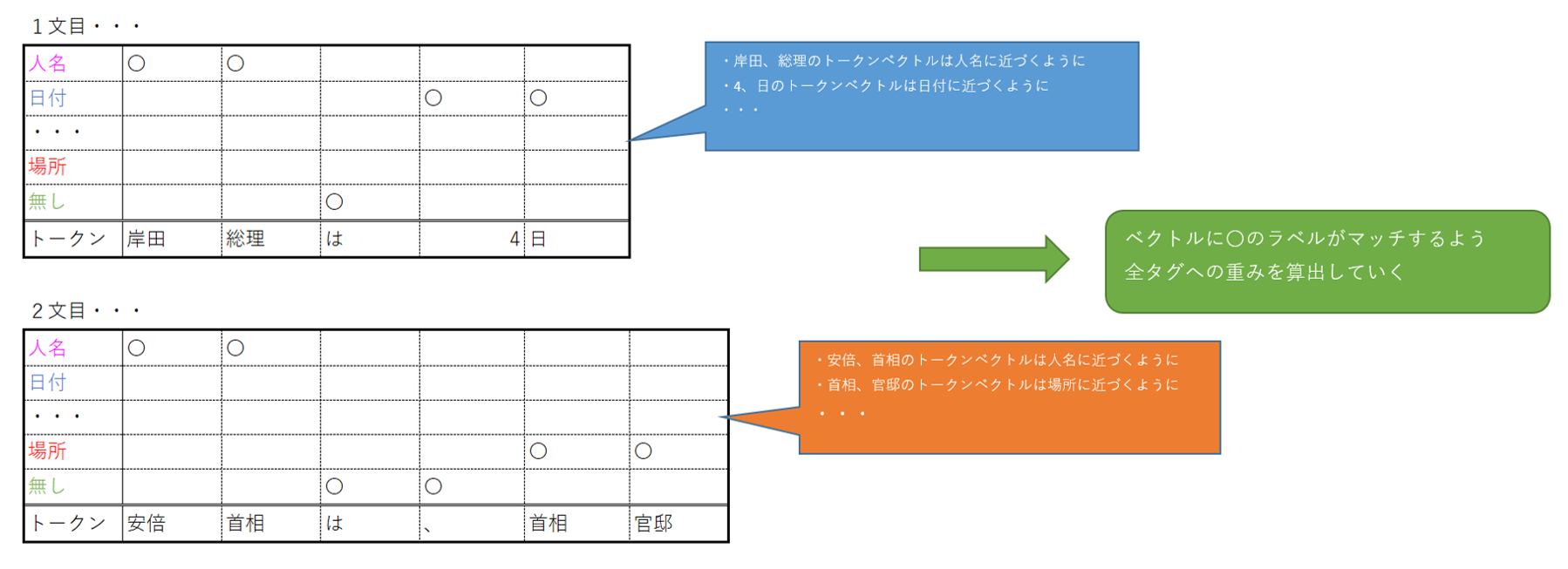
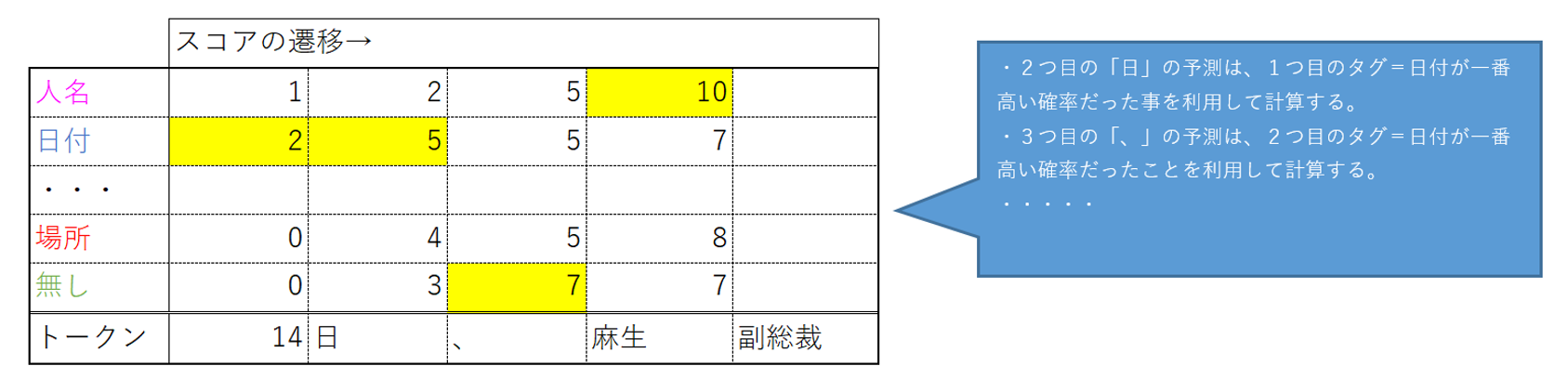
推論時には各トークンに対し、ラベルのタグ毎に素性ベクトルを計算し重みを掛け合わせ確率を算出します。
全てのトークン位置とタグ種類の組み合わせで文の最大スコア(確率の高さ)を求めるのは計算量が多大になりますがトークン毎の素性ベクトルは一つ前のラベルも入力となる事から、一つ前の予測結果を用いて絞り込む事で最大となるスコアを探索する計算量を抑える事に繋がります。
入出力の方針
CRFへの入力としてはトークン毎の素性、ラベルの種類を方針として決定する必要が有ります。
今回は前回のルールベースでの分析を踏まえ素性とする情報を決定します。
素性設計
今回取り扱うCRFでは、以下の要素を素性として取り入れたいと思います。
品詞・係り受け
対象の固有表現の前後には決まった品詞の発生が多い事が挙げられました。
今回もこの品詞情報を使用しますが、係り受け情報も素性として追加したいので係り受け解析器にginzaを、形態素解析器にはginzaが用いるSudachiを用いる事とします。※4
係り受け解析とは?
係り受け解析は「主語と述語」、「修飾語と被修飾語」など言葉と言葉の関係性である「係り受け」を機械的に解析する事です。
例えば「太郎は次郎に本を渡した」という文では以下の様な係り受けになります。
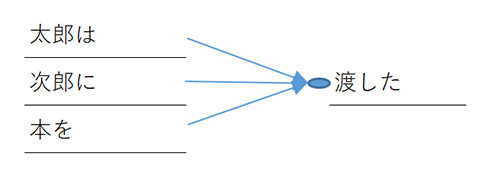
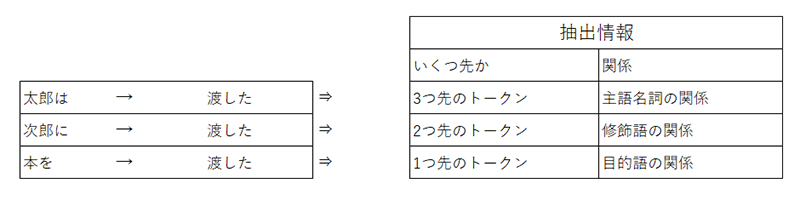
今回はこの係り受けの情報から得られる「いくつ先のトークン」に「どのような関係」があるかという情報を取り出し用いたいと思います。
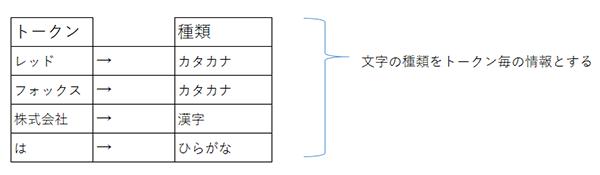
文字の種類
前回のサンプル分析では企業名として漢字・カタカナ・アルファベットが含まれていました。
この「文字の種類」についても企業名を構成する要素となり得ると考えられますので「形態素を構成する文字の種類」という素性も扱いたいと思います。
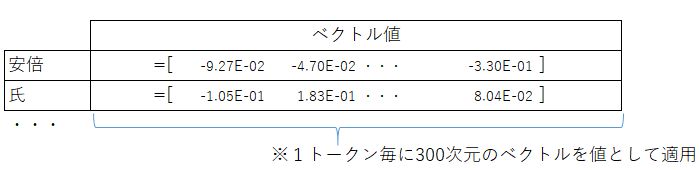
単語分散表現
単語分散表現とは単語の意味をベクトルで表現する事です。
Wikipediaを中心としたコーパス(大規模な文書集合)を元に、単語の意味を学習する事で作成されます。
単語分散表現を求める手法としてはWord2Vec、fasttextという2つの手法が代表的な例としてありますがいずれもskip-gramという対象とする周辺の単語予測するようベクトルを学習する手法です。

Word2Vecで学習されたベクトルは単語が持つ概念同士が関連し合うように学習されるため
"king"-"man"+ "woman" = "queen"といったアナロジーをベクトル同士の計算で導き出せるとされています。※5
今回は、subwordと呼ばれる単語中の文字構成の近さも特徴として持った手法となるfasttextにより学習された日本語の公開ベクトルを元に単語の分散表現を素性に組み込んでいきます。※6
ラベル設計
CRFでは素性として前後の連続したラベルが使用されるため、ラベルの境界と開始位置を学習に組み込む事を狙いBIO方式を用いてタグ付けを行いたいと思います。
BIO形式:B(Begin)=開始、I(Inside)=途中、O(Outside)=対象外の3タイプでラベルを区分する上記の例だと、人名(Begin)、人名(Inside)、日付(Begin)、日付(Inside)と各ラベル種類を2種類に分け連続した1つ目のトークンにBeginを、2番目以降にInsideを付与します。
例:
| 人名(B) | 人名(I) | O | 日付(B) | 日付(I) | |
| 岸田 | 総理 | は | 4 | 日 | ・・・・ |
上記の様に、B→Iとタグの連続性が決まっているため、「Bの後にIが発生する」という観点の注入を狙いたいと思います。
また、予測する固有表現のラベルは前回と同様に企業名を正のラベル、企業名以外を負のラベルとして取り扱いたいと思います。
例
- 文:
- レッドフォックス株式会社は、東京都千代田区に本社を置くITサービス企業である。
- 法人名:
- レッドフォックス株式会社
- 地名:
- 東京都千代田区
| ラベル: | 正(B) | 正(I) | 正(I) | 正(I) | O | O | 負(B) | 負(I) | 負(I) | 負(I) | O |
|---|---|---|---|---|---|---|---|---|---|---|---|
| トークン: | レッド | フォックス | 株式 | 会社 | は | 、 | 東京 | 都 | 千代田 | 区 | に |
| ラベル: | O | O | O | O | O | O | O | O | O | ||
| トークン: | 本社 | を | 置く | IT | サービス | 企業 | で | ある | 。 |
CRFによる情報抽出サンプル
以下はこれら条件を元に、実際に抽出から精度評価までを行うコードです。
※Pythonコードで記載しています
import os
from time import time
import json
from sklearn.metrics import make_scorer
import sklearn_crfsuite
from sklearn_crfsuite import metrics
import joblib
import numpy as np
import fasttext
def save_jsonl_file(file_name, jsonl):
with open(file_name,"w", encoding="utf8") as f:
for json_data in jsonl:
json_text = json.dumps(json_data,ensure_ascii=False)
f.write(json_text + "\n")
class TextTokenizer:
def __init__(self):
from sudachipy import tokenizer
from sudachipy import dictionary
self.tokenizer_obj = dictionary.Dictionary().create()
self.tokenizer_mode = tokenizer.Tokenizer.SplitMode.A
import ginza
import spacy
self.depend_obj = spacy.load('ja_ginza')
ginza.set_split_mode(self.depend_obj , "A")
def _tokenize(self, text):
return self.tokenizer_obj.tokenize(text, self.tokenizer_mode)
# 形態素解析し、形態素情報配列を返却
def extract_tokens(self, text):
result = []
if not text: return result
# Sudachiによる形態素解析を実施
tokens = self._tokenize(text)
depts = [[token.head.i, token] for sent in self.depend_obj(text).sents for token in sent]
text_pos, morphs = 0, 0
for token in tokens:
# 有効な品詞情報を取得(固定長で値のない項目は*で埋まっている)
features = token.part_of_speech()
features = features[:features.index("*")]
dept = ""
if len(token.surface().strip()) > 0:
dept = str(depts[morphs][1].head.i-depts[morphs][1].i) + "-"+ depts[morphs][1].dep_
morphs += 1
# 表層・品詞・係り受け・スパンを結果として格納
result.append({"surface": token.surface(), "postag": features, "deps": dept, "span": [text_pos, text_pos + len(token.surface())]})
text_pos += len(token.surface())
return result
class DataSetLoader(object):
def __init__(self, origin_file, priprocessed_file):
texts = []
# 前処理済みファイルがある場合はこれを使用
if os.path.exists(priprocessed_file):
with open(priprocessed_file,"r", encoding="utf8") as f:
for line in f.readlines():
line = json.loads(line)
texts.append(line)
else:
# 形態素解析等、前処理加工を実施
texts = self._preprocessing(origin_file)
# 前処理済みデータを保存
save_jsonl_file(priprocessed_file, texts)
# 学習データ 9割 テストデータ 1割に分割。フィールドに格納
trains = int(len(texts) * 0.9)
self.train_texts, self.test_texts = texts[:trains], texts[trains:]
# データセット JSONファイルの前処理
# 形態素解析し、トークンとして加工する
def _preprocessing(self, json_file):
result = []
# 前処理済みファイルが無い場合はオリジナルを読み込み
# 形態素解析によるトークン化を準備
tokenizer = TextTokenizer()
# データセットをロード
with open(json_file,"r", encoding="utf8") as f:
jsons = json.load(f)
for j in jsons:
# 文を形態素解析し結果を取得
tokens = tokenizer.extract_tokens(j["text"])
for i, token in enumerate(tokens):
# トークンに文字種情報を付与
token["type"] = self._get_character_types(token["surface"])
# BIOタグの初期値としてOを設定
token["tag"] = "O"
# 正解、不正解のラベル情報を準備
j["correct"], j["incorrect"] = [], []
# データセットのラベル付けを元に、正解、不正解のBIOタグを付与
for e in j["entities"]:
bio_items = []
for token in tokens:
if e["span"][0] <= token["span"][0] and e["span"][1] >= token["span"][1]:
bio_items.append(token)
# 法人名を正解、法人名以外を不正解とタグ分けします
if len(bio_items) > 0 and bio_items[0]["span"][0] == e["span"][0] and bio_items[-1]["span"][1] == e["span"][1]:
label_kind = ("correct" if e["type"] == "法人名" else "incorrect")
for i, token in enumerate(bio_items):
token["tag"] = ("B" if i == 0 else "I") + "-" + label_kind
# 正解、不正解ラベル情報を保持
j[label_kind].append({"name": e["name"], "span": e["span"]})
j["tokens"] = tokens
# トークン化&BIOタグ付与し結果を格納
result.append(j)
return result
# 形態素の文字種抽出
def _get_character_types(self, text):
def _get_character_type(ch):
def is_hiragana(ch): # 平仮名の判定
return 0x3040 <= ord(ch) <= 0x309F
def is_katakana(ch): # カタカナの判定
return 0x30A0 <= ord(ch) <= 0x30FF
if ch.isspace(): return 'SP' # 半角スペース
elif ch.isdigit(): return 'DT' # アラビア数字
elif ch.islower(): return 'AS' # アルファベット小文字
elif ch.isupper(): return 'SB' # アルファベット大文字
elif is_hiragana(ch): return 'HG' # 平仮名
elif is_katakana(ch): return 'KT' # カタカナ
else: return 'OT' # 漢字・記号を含むその他文字
# 対象形態素を構成する文字種を決定
character_types = map(_get_character_type, text)
result = '-'.join(sorted(set(character_types)))
return result
# CRFの素性演算処理
class FuturesCreator(object):
def __init__(self, model_file):
# fasttext モデルをロード
self.model = fasttext.load_model(model_file)
# 対象トークンをベクトル化
def _get_wordvector(self, word):
try:
vector = self.model[word]
except:
vector = np.zeros(300,)
return vector
def _token2features(self, tokens, position): # トークンの素性演算
features = {
'bias': 1.0,
}
# 素性追加処理
def add_futures(index):
token_index = position + index
positon_str = ""
if index > 0:
positon_str = "+" + str(index) + ":"
elif index < 0:
positon_str = "-" + str(abs(index)) + ":"
ch = tokens[token_index]["surface"] # 表層
type = tokens[token_index]["type"] # 文字種
postag = tokens[token_index]["postag"] # 品詞情報
deps = tokens[token_index]["deps"] # 掛かり受け
features.update({
f'{positon_str}char' : ch,
f'{positon_str}type' : type,
f'{positon_str}postag' : postag,
f'{positon_str}deps' : deps,
})
# position番目のトークンについて素性を追加
add_futures(0)
wordembdding = self._get_wordvector(tokens[position]["surface"])
for iv,value in enumerate(wordembdding):
features[f"v-{iv}"]=value
if position == 0:
# 最初のトークンはBOSを付与
features['BOS'] = True
else:
# 1トークン目以降は2形態素前までの文字情報を素性として入れる
if position >= 2:
# 2トークン前の文字情報を素性として入れる
add_futures(-2)
# 1トークン前の文字情報を素性として入れる
add_futures(-1)
if position == len(tokens) -1:
# 最後のトークンはEOSを付与
features['EOS'] = True
else:
# 1トークン後の文字情報を素性として入れる
add_futures(1)
if position < len(tokens)-2: # 2トークン後の情報を素性として入れる
add_futures(2)
return features
def text2futures(self, texts):
return [[self._token2features(text["tokens"], i) for i in range(len(text["tokens"]))] for text in texts]
def text2labels(self, texts):
return [[token["tag"] for token in text["tokens"]] for text in texts]
# CRF学習済みモデルの保存字ファイル名
model_file_name = "./saved_model.pkl"
t0 = time()
print("Load DataSets ")
# データセットロード
dl = DataSetLoader("./ner.json", "./ner_preprocessed.json")
train_texts = dl.train_texts
test_texts = dl.test_texts
duration = time() - t0
print(f"done in {duration:.1f}sec")
# 文書・ラベルをそれぞれ X,Yとして設定
print("Create Train Test Data ")
model_file = "./cc.ja.300.bin"
t0 = time()
fc = FuturesCreator(model_file)
X_train = fc.text2futures(train_texts)
y_train = fc.text2labels(train_texts)
X_test = fc.text2futures(test_texts)
y_test = fc.text2labels(test_texts)
duration = time() - t0
print("done in %fs" % duration)
# 学習
# 'lbfgs' -> Gradient descent using the L-BFGS method
print("Execute train[x_train:{}]".format(str(len(X_train))))
t0 = time()
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
crf.fit(X_train, y_train)
duration = time() - t0
print("done in %fs" % duration)
# モデルの保存
print("Save Model File")
t0 = time()
joblib.dump(crf, model_file_name)
duration = time() - t0
print("done in %fs" % duration)
# テスト
print("Execute Predict[{}]".format(str(len(X_test))))
t0 = time()
y_pred = crf.predict(X_test)
duration = time() - t0
print("done in %fs" % duration)
# 結果スコアリング
labels = list(crf.classes_)
# labels.remove('O')
f1 = metrics.flat_f1_score(y_test, y_pred, average='weighted', labels=labels)
print("f1-score:" + str(f1))
sorted_labels = sorted(
labels,
key=lambda name: (name[1:], name[0])
)
print(metrics.flat_classification_report(
y_test, y_pred, labels=sorted_labels, digits=3
))
# testデータと推論結果を保存
save_jsonl_file("test_data.json", test_texts)
with open("test_predict.txt","w", encoding="utf8") as f:
for sent_pred in y_pred:
sent_pred = "\t".join(sent_pred)
f.write(sent_pred + "\n")
# 推論結果をスパンに変換し反映
for x, labels in zip(test_texts, y_pred):
x["pred_correct"], x["pred_incorrect"] = [], []
pos, spans = 0, []
last_tag = ""
def add_pred(tag, sp):
span = [sp[0]["span"][0], sp[-1]["span"][1]]
name = "".join([s["surface"] for s in sp])
x["pred_" + tag[2:]].append({"name": name, "span": span})
for token, label in zip(x["tokens"], labels):
if (label == "O" or label[0] == "B") and len(spans) >0:
add_pred(last_tag, spans)
spans = []
last_tag = label
if label[0] in ["B", "I"]:
spans.append(token)
if len(spans) > 0:
add_pred(spans)
# 抽出結果の精度確認
print("精度算出 start")
TP1, FP1, TN1, FN1 = 0, 0, 0, 0
TP2, FP2, TN2, FN2 = 0, 0, 0, 0
for sentence in test_texts:
# 企業名予測についての算出
# 企業名を正しく企業名として予測した結果をえり分け
true_positive1 = [p for p in sentence["pred_correct"] if p in sentence["correct"]]
# 企業名と予測したが企業名ではなかった結果をえり分け
false_positive1 = [p for p in sentence["pred_correct"] if p not in sentence["correct"]]
# 企業名を企業名と予測できなかった対象をえり分け
false_negative1 = [p for p in sentence["correct"] if p not in sentence["pred_correct"]]
# 企業名以外を企業名以外と予測できた対象をえり分け
true_negative1 = [p for p in sentence["pred_incorrect"] if p not in sentence["correct"]]
# True Positive = 企業名を正しく企業名と予測できた件数
TP1 += len(true_positive1)
# True Negative = 企業名以外を企業名でないと予測できた件数
TN1 += len(true_negative1)
# False Negative = 企業名である固有表現を企業名でないと予測した件数
FN1 += len(false_negative1)
# False Positive = 企業名を企業名と予測できなかった件数
FP1 += len(false_positive1)
sentence["true_positive1"] = true_positive1
sentence["true_negative1"] = true_negative1
sentence["false_negative1"] = false_negative1
sentence["false_positive1"] = false_positive1
# 企業名以外の固有表現についての算出
# 企業名以外を正しく企業名以外として予測した結果をえり分け
true_positive2 = [p for p in sentence["pred_incorrect"] if p in sentence["incorrect"]]
# 企業名以外を企業名として予測した結果をえり分け
false_positive2 = [p for p in sentence["pred_incorrect"] if p not in sentence["incorrect"]]
# 企業名以外を企業名以外と予測できなかった対象をえり分け
false_negative2 = [p for p in sentence["incorrect"] if p not in sentence["pred_incorrect"]]
# 企業名を企業名以外でないと予測できた対象をえり分け
true_negative2 = [p for p in sentence["pred_correct"] if p not in sentence["incorrect"]]
# True Positive = 企業名以外の固有表現を正しく企業名以外の固有表現と予測できた件数
TP2 += len(true_positive2)
# True Negative = 企業名を企業名以外の固有表現でないと予測できた件数
TN2 += len(true_negative2)
# False Negative = 企業名以外の固有表現を企業名以外の固有表現と予測できなかった件数
FN2 += len(false_negative2)
# False Positive = 企業名以外の固有表現を企業名と予測した件数
FP2 += len(false_positive2)
sentence["true_positive2"] = true_positive2
sentence["true_negative2"] = true_negative2
sentence["false_negative2"] = false_negative2
sentence["false_positive2"] = false_positive2
# 精度をコンソールに出力
print("企業名")
print("TP:{},FP:{},TN:{},FN:{}".format(TP1, FP1, TN1, FN1))
print("Accuracy:{}".format((TP1 + TN1) / (TP1 + TN1 + FP1+ FN1)))
print("Precision:{}".format(TP1 / (TP1 + FP1)))
print("Recall:{}".format(TP1 / (TP1 + FN1)))
print("企業名以外")
print("TP:{},FP:{},TN:{},FN:{}".format(TP2, FP2, TN2, FN2))
print("Accuracy:{}".format((TP2 + TN2) / (TP2 + TN2 + FP2+ FN2)))
print("Precision:{}".format(TP2 / (TP2 + FP2)))
print("Recall:{}".format(TP2 / (TP2 + FN2)))
# 結果をファイルに保存
with open('./result.json', 'w', encoding="utf8") as f:
json.dump(test_texts, f, indent=4, ensure_ascii=False)
抽出結果の評価
CRFによる抽出結果はBIOタグによる結果表現です。
実際に文章の中から得たい企業名についてはBIOタグの連続性を元に結合し最終的な企業名とする必要が有ります。
今回の性能評価については、CRFにより予測されたBIOタグ単位での評価と、これを結合し最終的な抽出結果へ変換した結果で行いたいと思います。
1 BIOタグによる性能評価
〇性能評価
まず、BIOタグそれぞれでの予測性能を評価したいと思います。
評価方法は前回にも取り上げた混同行列とし正負のそれぞれで評価します。
| 正(B) | 正(I) | 負(B) | 負(I) | O | |
| 適合率(Precision) | 0.839 | 0.834 | 0.861 | 0.861 | 0.977 |
|---|---|---|---|---|---|
| 再現率(Recall) | 0.623 | 0.649 | 0.878 | 0.882 | 0.983 |
| 正解率(Accuracy) | 0.953 | ||||
企業名であると予測し実際に企業名であった推測については約84%程が正解であり企業名以外の固有表現については86%程度が正解できていたようです。
企業名に対する再現率は63%程度と少し低くはありますが前回のルールベース・探索と比較すると数倍に伸びているとみられます。
ただし、上記のBIOタグの結果についてはラベルの種類毎の予測結果なので、上記の「レッドフォックス株式会社」の例のように複数のトークンで構成される企業名については部分的にのみ正解できているという可能性があります。
〇誤り分析
部分正解となる例を1件見てみましょう。
| 正解ラベル: | 正(B) | 正(I) | O | 正(B) | 正(I) | O | 正(B) | 正(I) | O | O | O | O | O | O | O | O | O | O |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 予測ラベル: | 正(B) | 正(I) | 正(I) | 正(I) | 正(I) | 正(I) | 正(I) | 正(I) | O | O | O | O | O | O | O | O | O | O |
| トークン: | ロイター | 通信 | ・ | ドイツ | 通信 | ・ | AP | 通信 | の | 各 | 通信 | 社 | は | 速報 | を | 出し | た | 。 |
※長文のため、前方を省略しております。
この文例では正解上3つの企業名が含まれていますが、1つのつながった企業名として予測されました。
予測結果内のB→Iの連続性については規則正しく予測ができていましたが、終了位置についての予測が正しくできない例がいくつかあります。
これについてはBIOタグに終了(End)、単独(Single)のタイプを追加した「BIOES」方式で解決できる可能性がありますが前回の誤り分析で扱った「IHG・ANA・ホテルズ」の例もあることから、このデータセットを扱う際には「・」(中黒)に注視する必要が有ると考えられます。
解決方法としてはCRFで抽出した結果に対し、「・」で分割するといったルールベース処理を後段の処理として追加する事で改善できる可能性があります。
※もちろん、データセットの文字表現を統一化し企業名区切りの「・」は「、」(読点)に置き換え学習させるという前処理による解決策も考えられます。
2 最終的な抽出結果による評価
〇性能評価
企業名である、企業名以外の固有表現であるという2つの情報をラベルとして付与していることから、①企業名の予測と②企業名以外の固有表現の予測の2つの軸で性能評価を行いたいと思います。
混同行列の計算基準としては完全一致をベースに以下とします。
| ①企業名の予測 | ②企業名以外の固有表現の予測 | |
| TP(対象を対象として正しく予測できたか) | ①を正しく①と予測できた | ②を正しく②と予測できた |
|---|---|---|
| TN(対象外を対象外として正しく予測できたか) | ②を①以外と予測できた | ①を②以外と予測できた |
| FN(対象を誤って対象外と予測したか) | ①を①と予測できなかった | ②を②と予測できなかった |
| FP(対象外を誤って対象と予測したか) | ①以外を①と誤って予測した | ②以外を②と誤って予測した |
この計算基準で前回と同様に正解率、適合率、再現率を正負の両方でスコアリングしてみます。
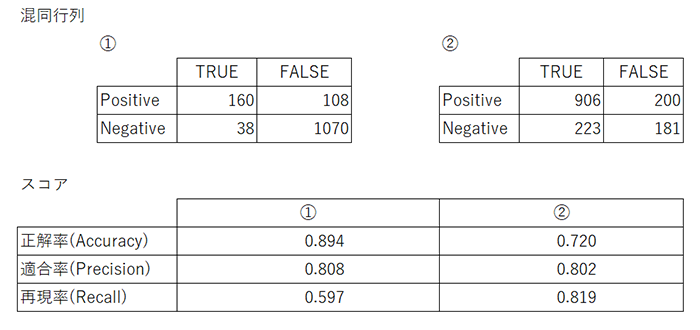
企業名より、企業名以外の固有表現が全体的にデータ数が多い事もあり、正解率は企業名以外の固有表現の当たり具合に依存傾向が出ていますが、企業名の方がより正解できているようです。
また、いずれも適合率が高いことから①、または②の対象として予測したもののうち正しかった確率は8割程度。
再現率から企業名の抽出の方は約4割ほど取りこぼしがある状況にあるとみられます。
〇誤り分析
誤り分析については、主テーマである企業名抽出に対して行っていきたいと思います。
最終抽出結果は完全一致をベースとしているため、正解に対して部分的に抽出できている予測はFPに全く予測されず取りこぼした正解はFNに計上されるためそれぞれを見てきたいと思います。
文例:日映科学映画製作所は、その一方の科学映画の人材を受け継いで、1951年に石本統吉によって設立された。
| 形態素 | 日映科学映画製作所は、その一方の科学映画の人材を受け継いで、1951年に石本統吉によって設立された。 |
|---|---|
| 品詞 | 日映科学映画製作所は、その一方の科学映画の人材を受け継いで、1951年に石本統吉によって設立された。 |
上記の予測例では「映科学映画製作所」がFPに計上される部分一致の誤り、「科学映画」の部分が取りこぼしたFNに当たる部分です。
「映科学映画製作所」の誤りについての分析
対象の文をSudachiで形態素解析すると以下のように分割されます。
| 正解 | 日 | 映科 | 学 | 映画 | 製作所 | は |
|---|---|---|---|---|---|---|
| 予測 | 名詞 | 名詞 | 接尾辞 | 名詞 | 名詞 | 助詞 |
この例の「日」の品詞の詳細部分は「副詞可能」と時相名詞を扱うものであり企業名の一部としては頻出しない事
「日」の漢字を含む企業名は「日本航空」など「日本」の表記が多いですが「日映」自体が企業名「日本映画」の略称であることから今回の素性設計では難しい内容であることが伺えます。
「科学映画」の誤りについての分析
「科学映画」部分を単語のみで捉えようとすると企業名であるという認識に至るのはかなり難しいと思われます。
もう少し範囲を広げ「科学映画の人材を受け継いで」であれば「科学映画」自体が人材を受け継ぐ組織・集団であるという予測は人が持つ前提知識を用いれば予測できるかもしれません。
今回の手法では品詞、分散表現を素性として組み込んでいますが、「人材」という言葉が企業名のそばにが発生する例がなく規則性を学習・予測できなかったパターンといえる内容かと考えられます。
CRFによる固有表現抽出という取り組みについて
CRFを用いた企業名固有表現抽出の取り組みを扱った結果、「企業名」と予測し正解できた確率は約80%「企業名」とされた正解のうち、約60%を対象として抽出するという結果になりました。
前回のルールベース・探索による取り組みと比較しても、正解率は1.6倍強、抽出率は3.3倍強と大きく飛躍させる事ができ機械学習による優位性を見る事ができました。ですが、複合的な情報を元に学習し予測をすることから、学習に際して様々な観点と情報を組み合わせる必要が有り自然言語と統計的な分析に対する知識・経験が必要な領域ともなるので専門性が高い領域とも言えます。
素性設計の検討やデータの加工を更に行う事で、更に良いスコアを目指す事はできますが学習データが量・質(パターン)的に十分に揃わず頭打ちになる局面もあると思います。そのような時には、誤り分析をし可能な部分はルールベースで抽出するというように抽出処理全体を階層化する事で更なる精度向上を図る事もできます。
また、上記のサンプルコードには学習済モデルを出力する処理が含まれておりますが、生成されるモデルファイルは2MB程と小さくアプリケーションの一部として配布する事も可能なサイズです。固有表現抽出や品詞特定以外にも、NGワードやネガティブ/ポジティブワードの特定など様々な識別モデルを作りアプリケーションに組み込む事ができるでしょう。
最後に
今回は機械学習手法を扱いました。近年では深層学習と呼ばれる機械学習を更に進化させた手法が多く扱われ様々な予測問題で人の判断を超える結果を打ち出す手法も登場しております。
次回はそのような深層学習の手法の中から「INTELLILINK バックオフィスNLP」でも採用しておりますBERTについてご紹介させて頂きたいと思います。
引用元
- ※1https://www.data.jma.go.jp/gmd/risk/H28_drink_chousa.html
- ※2http://www.cs.columbia.edu/~mcollins/crf.pdf
http://dirichlet.net/pdf/wallach04conditional.pdf - ※3https://worksapplications.github.io/Sudachi/
- ※4https://www.megagon.ai/jp/projects/ginza-install-a-japanese-nlp-library-in-one-step/
- ※5https://kawine.github.io/blog/nlp/2019/06/21/word-analogies.html
- ※6https://fasttext.cc/docs/en/crawl-vectors.html