
















画像分析のためのニューラルネットワークの概要
はじめに
ニューラルネットワークは、一般的な機械学習の教科書に載っている機械学習モデルの1カテゴリであり、画像分析の分野に革命をもたらしたアルゴリズムの集合です。これらは、画像分析の分野に革命をもたらした特定のアルゴリズムのセットです。ニューラルネットワークは生物学的な神経ネットワークから着想を得ており、現在のいわゆるディープニューラルネットワークは、画像処理と認識に基づく複数のユースケースで非常にうまく機能することが証明されています。
ニューラルネットワークは、それ自体が一般的な関数の近似であるため、入力空間から出力空間への複雑なマッピングを学習することに関して、文字通りほぼすべての画像およびコンピュータービジョンの問題に適用できます。
ニューラルネットワークの助けを借りて実現できる主なタスクには、以下のようなものがあります。
- 1.パターンの認識: 実際のシーンにあるオブジェクト(物体)、顔、表情、話し言葉など
- 2.異常の認識: 異常な一連の動作または異常なパターンの識別
- 3.予測: 入力と機械レベルの理解に基づく将来の予測
長年にわたり、さまざまなユースケースにおいて、複数のニューラルネットワークアーキテクチャが開発され、実装されてきました。ここでは、画像分析に広く応用されている、最も一般的で著名なニューラルネットワークのアーキテクチャをいくつか取り上げます。
CNN(Convoluted Neural Network:畳み込み/コンボリュートニューラルネットワーク、CNN)
CNN(畳み込み/コンボリュートニューラルネットワーク、以下CNN)は、1998 年に Yann LeCun とその仲間によって開発されました (当初は、LeNet と呼ばれる手書き数字用の優れた認識器を開発)。 CNNは、複数の隠れ層を持つフィードフォワードネットに逆伝播を用い、各層に多数の複製ユニットのマップを持ち、近くの複製ユニットの出力をプール(圧縮)します。そのため、複数の文字が重なっても一度に対応できる広い網を持っています。
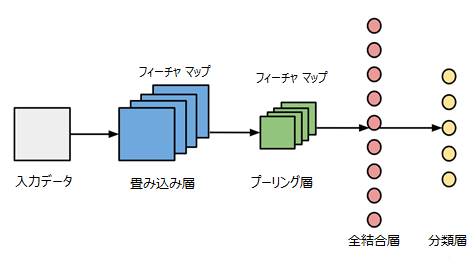
図1:Convoluted Neural Network architecture
CNNは、市場で入手可能な他の多くのニューラルネットワークアーキテクチャとはまったく異なります。CNNは、主に画像処理と分類で使用されますが、音や音声などの他の入力タイプでも使用できます。 重要なのは、CNNの働きを理解することです。このプロセスは、入力データが、従来の通常の層の代わりに、すべてのノードがすべてのノードに接続されているわけではない、コンボリュート層(畳み込み層、図1参照)を経由して供給されることから始まります。これらの複雑な層は、深くなると収縮する傾向があります。また、CNNにはプーリング層も含まれます。プーリングは細部をフィルタリングする方法であり、一般的に見られるプーリング手法の一つにマックスプーリングがあります。これは、特徴マップのパッチの値を計算し、それを使ってダウンサンプリングした(プールした)フィーチャマップを作成するプーリング操作です。通常、コンボリュート層の後に使用されます。
Recurrent Neural Networks (リカレントニューラルネットワーク、RNN)
リカレントニューラルネットワーク (以下、RNN) は、1990 年に Jeffrey Elman によって発表されたもので、基本的にはパーセプトロンになります。ただし、従来のパーセプトロンとは少し異なります。RNNは、従来のパーセプトロンがステートレスであるのに対し、パス間の接続、時間的な接続をもっています。
RNNは、過去に関する多くの情報を効率的に保存できる分散型隠れ状態と、複雑な方法で隠れ状態を更新できる非線形ダイナミクスという2つの重要な特性を兼ね備えているため、非常に強力です。
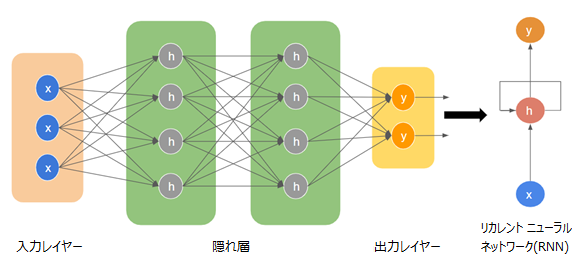
図2:Recurrent Neural Network architecture
このように非常に強力なニューラルネットワークアーキテクチャであるにもかかわらず、gradient(勾配)の消失(または爆発)という一つの大きな問題を抱えています。使用する活性化関数によっては、時間の経過とともに情報が急速に失われるという問題です。これは、過去の情報が保存されている場合に大きな問題になります。重みが 0 または1000000 の値に達すると、以前の状態は有益ではなくなります。
RNNは、原理的には多くの分野で利用できます。なぜなら、ほとんどの形式のデータには実際には時間軸がないからです (音声やビデオを除く)。一般に、リカレントネットワークは、情報を進めたり補完したりするのに最適です。
Long/Short Term Memory (長短期記憶ネットワーク、LSTM)
Hochreiter と Schmidhuber は、長短期記憶ネットワーク(以下、LSTM)と呼ばれるものを構築することで、RNN に物事を長期間記憶させるという問題を解決しました。LSTM ネットワークは、ゲートを導入してメモリセルを明示的に定義することにより、gradient(勾配)消失問題に対処しようとするものです。このメモリセルは以前の値を保存し、「forgot gate」がその値を忘れるように指示しない限り、それを保持します(図3)。
つまり、LSTM には入力ゲートと出力ゲートがあります。入力ゲートを介してメモリセルに新しいものやアイテムを追加でき、出力ゲートを介してこのセルから次の隠れ状態にベクトルを渡すかどうかを決定することができます。
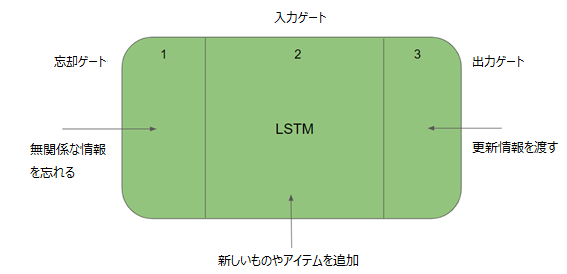
図3:Long/Short Term Memoryネットワーク
LSTM の最大の利点は、一つの反復から次の反復への隠れ状態の情報の転送を容易にするセル層を追加したことです。他のニューラルネットワークアーキテクチャと比較して、LSTM はより高い学習性を持ち、より多くの実行を成功に導きます。また、これまでのリカレントネットワークアルゴリズムでは解決できなかった、複雑で人工的な長いタイムラグのあるタスクも解決します。
Gated Recurrent Units (GRU)
Gated Recurrent Units (GRU) は、LSTMを少し改変したものです。LSTM との違いは、GRU が値を渡すためにセル層を必要としないことです。
LSTM とは異なり、GRU は3つのゲートのみで構成され、セルの内部状態を保持しません。LSTM リカレントユニットの内部セル状態に格納されている情報は、Gated Recurrent Unit の非表示状態に組み込まれます。この集められた情報は、次の Gated Recurrent Unit に渡されます。GRU のさまざまなゲートは次のとおりです。
- 1.更新ゲート: 過去の情報をどれだけを未来に伝える必要があるかを決定します。LSTM の出力ゲートに相当します。
- 2.リセットゲート:過去の情報をどの程度忘れる必要があるかを決定します。LSTM の入力ゲートに似ています。
- 3.現在のメモリゲート: リセットゲートに組み込まれ、入力に非線形性を導入し、入力をゼロ平均にするために使用されます。また、過去の情報が未来に渡される現在の情報に与える影響を減らすことです。
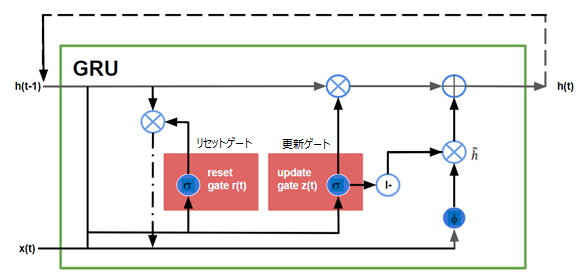
図4:Gated Recurrent Units (GRU)
ほとんどの場合、GRU は LSTM と同様に機能しますが、最大の利点は、GRU の方がわずかに高速で、比較的簡単に実行できることです。
Generative Adversarial Network (GAN)
Ian Goodfellow は、2つのネットワークが連携して機能する新しい種類のニューラルネットワークを導入しました。 Generative Adversarial Networks (GAN) は任意の2つのネットワーク (多くの場合、フィードフォワードとコンボリュートニューラルネットの組み合わせ) で構成され、一方はコンテンツを生成する(生成型)タスクを担い、もう一方はコンテンツを判断する(識別型)タスクを担います。識別モデルには、特定の画像が自然に見えるか(データセットからの画像)、人工的に作成されたように見えるかを判断するタスクがあります。ジェネレーターのタスクは、元のデータ分布に近い自然な外観の画像を作成することです。
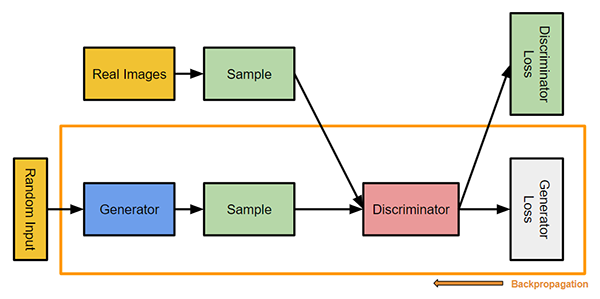
図5:Generative Adversarial Networks (GAN)
GAN は現在、非常に活発な研究テーマであり、これまでもさまざまな種類のGANの実装が行われてきました。その中で現在活発に利用されている重要なもののいくつかを以下に説明します。
- ●Vanilla GAN: これは最も単純なタイプの GAN です。Generator と Discriminator は単純な多層パーセプトロンです。通常の GAN では、アルゴリズムは非常に単純で、確率的勾配降下法を使用して数式を最適化しようとします。
- ●Conditional GAN (CGAN): CGAN は、いくつかの条件付きパラメーターを配置したディープ ラーニング手法と言えます。CGANでは、対応するデータを生成するために追加のパラメーター 'y' が ジェネレーターに追加されます。Discriminator(識別器)の入力にラベルを付加することで、Discriminator が本物のデータと偽物の生成データを区別できるようにします。
- ●Deep Convolutional GAN (DCGAN): DCGAN は、GAN の実装の中で最も人気があり、最も成功している実装の1つです。これは、多層パーセプトロンの代わりに ConvNet で構成されています。ConvNet は最大プーリングなしで実装され、実際にはコンボリューションストライドに置き換えられます。また、各層は完全に接続されていません。
- ●Laplacian Pyramid GAN (LAPGAN): ラプラシアンピラミッドは、1オクターブ間隔で配置されたバンドパス画像の集合と低周波残差で構成される、線形反転可能な画像表現です。このアプローチでは、複数の Generator および Discriminatorネットワークと、さまざまなレベルのラプラシアンピラミッドを使用します。この方法は、非常に高品質の画像を生成するために使用されます。画像は、最初にピラミッドの各層でダウンサンプリングされ、その後、画像が元のサイズに達するまで、これらの層でConditional GAN からノイズを取得するバックワードパスの各層で再びアップスケールされます。
- ●Super Resolution GAN (超解像度 GAN) (SRGAN): SRGAN は、その名の通り、より高解像度の画像を生成するために、adversarial network(敵対的ネットワーク)と共にディープニューラルネットワークを使用する GAN の設計手法です。このタイプの GAN は、低解像度のネイティブ画像を最適に拡大して細部を強調し、エラーを最小限に抑えるのに有効です。
GAN は、産業界で、対話型画像編集、3次元形状推定、創薬、半教師付き学習からロボット工学に至るまで、さまざまな用途に応用されています。
最後に
結論として、ニューラルネットワークは、これまでに発明された中で最も美しいプログラミングパラダイムの1つです。ニューラルネットワークの助けがあれば、我々はコンピューターに問題の解決方法を指示する必要はありません。代わりに、コンピューターは観察データから学習し、問題に対する独自の解決策を導き出します。このネットワークアーキテクチャの助けを借りて、画像分析やコンピュータービジョンにおける多くの重要な問題を簡単に解決できます。次回の記事では、その応用例をいくつか紹介します。
参考文献
- [1]https://openai.com/blog/generative-models/
- [2]https://data-notes.co/a-gentle-introduction-to-neural-networks-for-machine-learning-d5f3f8987786
- [3]https://en.wikipedia.org/wiki/Generative_adversarial_network
- [4]http://jalammar.github.io/visual-interactive-guide-basics-neural-networks/
- [5]http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- ※執筆協力(敬称略):Algo Analytics Pvt. Ltd. (Pune), Anand Deshpande, Amit Joshi
- ※文章中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。