















データマネジメントの要!データ品質管理のことはじめ 第3回 データ品質管理を効率的に実施する仕組み
はじめに
本コラム「データマネジメントの要!データ品質管理のことはじめ」は、3回に分けてお送りしています。第1回では、「データ品質管理とは」と題し、データ品質管理の基本的な概念と実践する際の課題について述べました。第2回では、「データ品質管理の進め方」と題し、DMBOKに沿ってデータ品質管理を進めるにあたっての作業ステップと検討内容などを解説しました。これまでの記事をまだ読んでいない方は、ぜひ以下からご覧ください。
これまでの解説で、データ品質管理のプロセスとフローを定義しました。しかしながら、データ品質管理を継続的な取り組みとして、定着させるには運用の効率化が欠かせません。
今回は、データ品質管理の運用における課題とそれらを解消し、効率よく運用するための仕組みをどのように構築していくのか、解説していきます。
データ品質管理の効率化が必要になる背景と課題
前回策定したデータ品質管理の運用フローが示すとおり、データ品質管理を効果的に行うには、データ品質の評価や監視やデータ品質への問題対処、レポーティングなどのプロセスを継続的に実施していく必要があります。
しかしながら、それらのプロセスは時間と労力(コスト)を要する場合があることや、データ品質管理の対象が増えると、第1回で述べた次の点についても考慮が必要になるでしょう。
- ・データソースの多様化によるデータ品質管理の複雑さ
- ・データを取り巻く人・プロセス・テクノロジーの変化への対応
では、具体的にどのような課題が発生するのかを前回策定した運用フローで見ていきます。
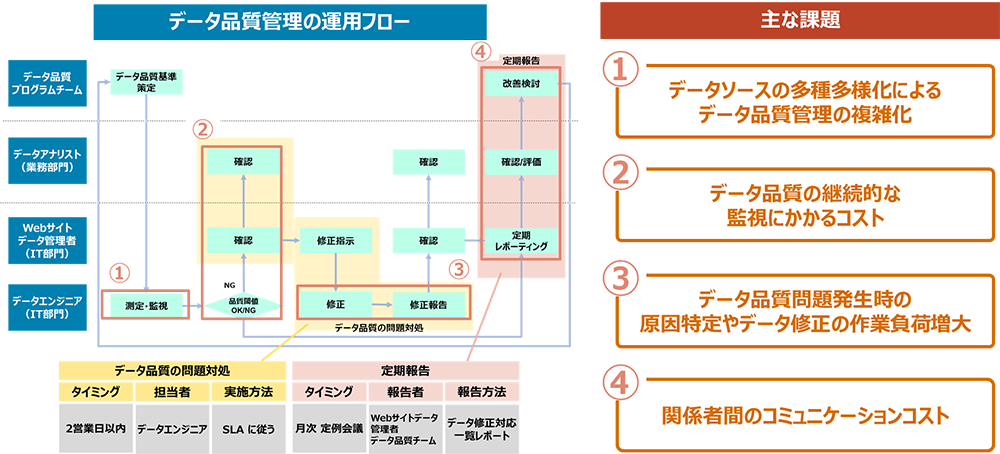
図1:データ品質管理の運用フローと主な課題
- ①データソースの多種多様化によるデータ品質管理の複雑化
データを活用する業務によってデータに求められる品質要件は異なります。その業務で必要とされるデータの種類は、構造化データだけでなく、非構造化データも含まれることがあります。また、格納場所についても、オンプレ・クラウド問わず対象になることも想定され、データソースとルールの対応付けなどの管理が複雑化してしまいます。 - ②データ品質の継続的な監視にかかるコスト
データ品質の監視は継続的に実施する必要があります。監視する対象が増えると都度の品質評価および、データ品質の問題発生時の通知先の管理など運用が煩雑になってしまいます。 - ③データ品質問題発生時の原因特定やデータ修正の作業負荷増大
データ品質の問題に対処する際、問題が発生する度に人手での原因特定およびデータ修正は時間と労力がかかるものです。また、SLAを遵守しながら複数の問題の対処をする場合に作業負荷は増大してしまいます。 - ④関係者間のコミュニケーションコスト
データ品質管理は IT部門と業務部門が協調して実施する必要があります。データ品質はビジネス要件によるため、データ品質の状況はデータの利用者に適切に共有することが重要です。そのコミュニケーションコストが増えると取り組みが滞ってしまいます。
これらの課題を解決し、データ品質管理を効率よく実施していくには、どのような対策が必要になるのでしょうか。
データ品質管理を効率化するには
データ品質管理を効率化するには、その取り組みを支えるテクノロジーを整備することが重要になります。DMBOKにおいても、「IT上の推進要因」として以下の「ツール」と「技法」が述べられています。
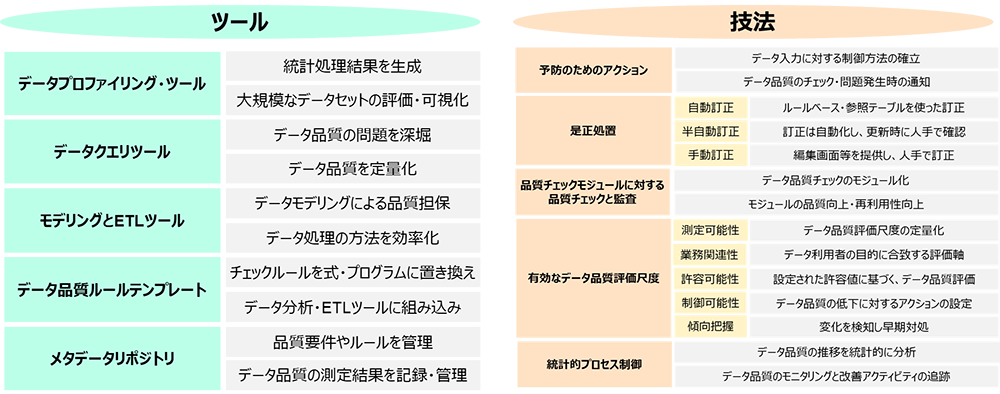
図2:IT上の推進要因となるツールと技法
ツールには、データの理解や品質の問題に対する原因特定および対処を手助けし、データ品質のチェックやモニタリング、それらを管理するものが述べられています。また、技法には、ツールを活用し、データ品質を継続的に改善するための要素が述べられています。
つまり、「ツール」と「技法」を活用することで、データ品質管理を効率よく実施するための“仕組み”を作るものと考えることができます。これを踏まえた解決方法は次の通りです。
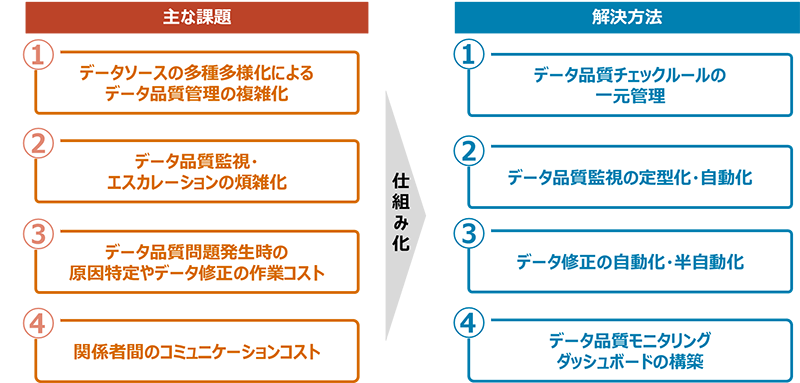
図3:データ品質管理課題と解決方法
- ①データ品質チェックルールの一元管理
データ品質管理の複雑さを解消するには、データの格納場所やデータ種類(構造化・非構造化)、形式を問わず、対象となるデータとデータ品質チェックルールを一元管理することが重要です。データ品質チェックルールは、プログラムコードや定義ファイルとしてテンプレート化し管理し、それらのテンプレートを ETL ツールや分析ツールに組み込むことで、データ接続から品質評価まで一貫した実施および管理が可能となります。 - ②データ品質監視の定型化・自動化
データ品質の継続的な監視を実現するには、データの取り込みや更新されたことを検知して、データ品質のチェックを実施する必要があります。このデータ品質のチェックは、通常のシステム運用の自動化のように、テスト自動化ツールや運用監視ツール等を用いて自動化することができます。また、データ品質の問題を検出した際の通知先などあらかじめ設定しておくことも可能になります。 - ③データ修正の自動化・半自動化
データ品質の問題に対しては、事前に定義した手続きに沿ってデータの修正を行い、期待する品質に適合させます。前回策定した運用フローで具体的なデータ修正の手続きまで定義ができています。従って、修正の手続きが定型の場合は、データプリパレーションツールやETLツールによる自動修正が有効です。ただし、クリティカルなデータの修正や修正内容の信頼度が低い場合は、人手での確認が必要になります。その場合、確認だけ人手で行い問題なければ後続の処理は自動化するなどで効率化が可能です。 - ④データ品質モニタリングダッシュボードの構築
データ品質評価結果を自動的に収集・蓄積し、可視化することで、タイムリーにデータ品質の状況を共有することができます。BIツールなどを利用し、ダッシュボード化することで、データの利用者含め関係者に共有が可能になります。これにより、定期的なレポート作成なども省力化でき、関係者間のコミュニケーションも円滑にできます。
上述のとおり、様々な(下線部に示す)ツールを組み合わせることで、データ品質管理の仕組みを構築できるように思えます。しかしながら、一連のプロセスを動かすには、異なるツール間を相互に連携することが求められ、高度なITスキルが求められることは想像に難しくありません。従って、システムの開発だけでなく運用においても、専門性を持った多くのITエンジニアを抱える必要があります。自社で人材確保が難しい場合は、運用コストの観点で一考の余地がでてきます。
これらのすべての課題を解決するには、「オールインワンプラットフォーム」の利用が選択肢の一つとしてあげられます。本稿では、Dataikuとうデータ分析プラットフォームで実現する例を紹介します。
オールインワンプラットフォーム「Dataiku」を使った例
本稿で紹介する「Dataiku」は、データ接続から、データの準備、機械学習モデルの構築、本番運用まで一つのプラットフォーム上で完結でき、IT部門や業務部門などあらゆる役割のユーザーが共同作業できることが大きな特徴となっています。
品質の高いデータは、「利用者の活用目的に合致しているデータ」のことを指しますが、オールインワンプラットフォームを利用すると、データの利用者からシームレスにデータ品質に関する改善のフィードバックを得られるようになり、効果的な改善サイクルを回すことが可能になります。
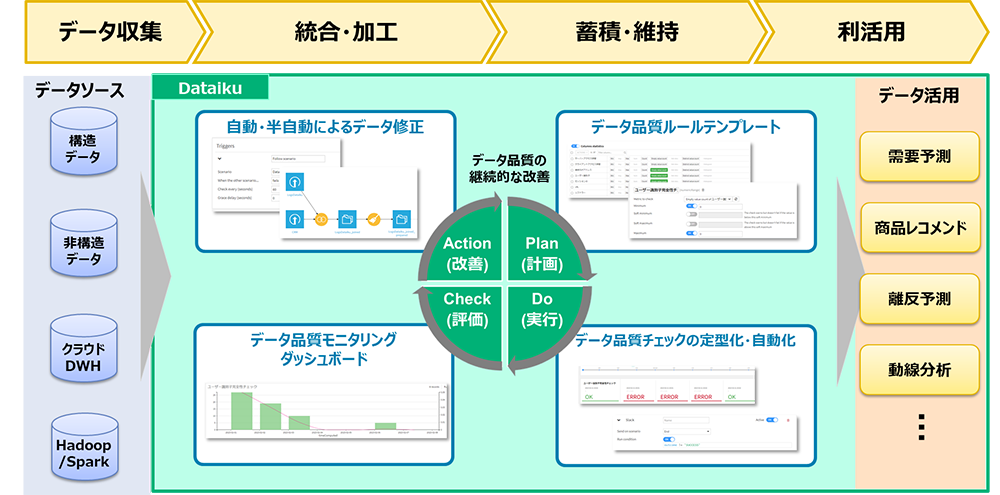
図4:Dataikuを使った場合の全体イメージ
Dataikuを使うと、データ品質管理の仕組みをどのように実現できるのか、次に紹介します。
① データ品質チェックルールの一元管理
データ品質チェックルールの一元管理を実現するには、一つのプラットフォームで多種多様なデータへの接続ができることと、接続したデータに対するデータ品質チェックを一元的に実施できることが重要です。Dataikuでは、以下の機能を活用することができます。
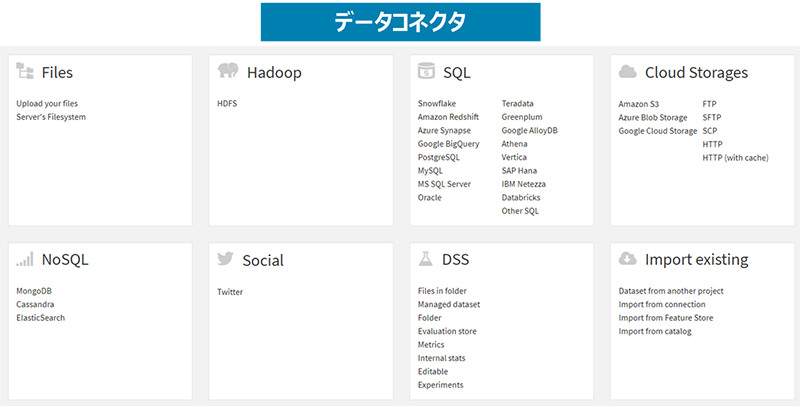
図5:多種多様なデータソースに対応したコネクタ
・ データの格納場所や構造化・非構造化データ問わず、様々なデータソースに対応したコネクタを利用しデータへ接続
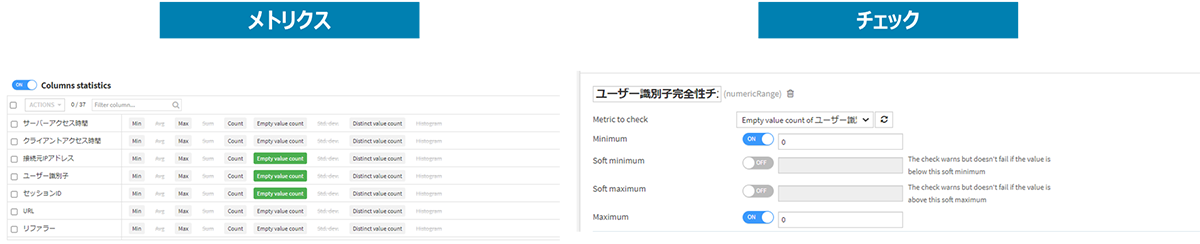
図6:メトリクスとチェック
・ 接続したデータセットに対して、欠損値の数や値の範囲などの評価指標(メトリクス)と許容値(チェック)などのデータ品質チェックルールを設定
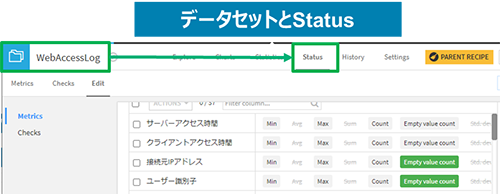
図7:データセットと品質チェックルールの紐づけ
・ データセットに設定した品質チェックルールはデータセットのStatus(データ品質チェックルールやチェック結果)として紐づけて管理
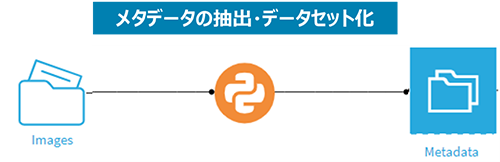
図8:非構造データのメタデータ抽出とデータセット化
・ 非構造データに対してはPython コードを使いメタデータを抽出し、データセットとして出力。構造化データ同様にデータ品質チェックルールを適用
② データ品質監視の定型化・自動化
データ品質監視の定型化・自動化を実現するには、品質チェック結果の自動収集と監視を行い、データ品質に問題が発生した場合は、あらかじめ設定した通知先へ自動的にアラート通知を行う仕組みの構築が必要です。Dataikuでは、品質の監視と、問題発生時の通知先として様々なチャネルに対応しています。

図9:データ品質の監視・アラート通知
- ・新しいデータの取り込みやデータが更新されたタイミングでメトリクスの算出とチェックルールを実行し、結果を監視
- ・データ品質に問題があった場合の通知先とチャネルを設定
③ 自動・半自動によるデータ修正
データ品質に問題があった場合の対処を定型化できるところは自動的に実施することで効率化できます。Dataikuでは、データプリパレーション機能を使ったパイプラインの構築と自動実行のためのシナリオ機能(トリガー)で実現できます。
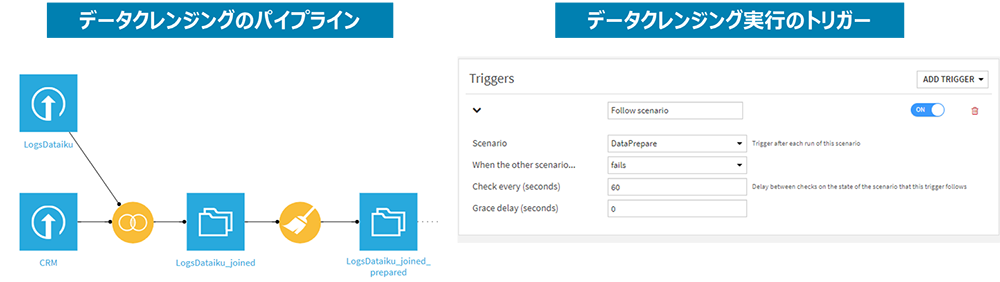
図10:データクレンジングの自動化
- ・データプリパレーション機能を使いデータクレンジングのパイプラインを構築
- ・データ品質に問題が発生した場合に自動実行するためのトリガーの設定
- ・人手の判断が必要な場合は、データを確認後、データクレンジングのパイプラインを手動実行
④ データ品質モニタリングダッシュボード
データ品質状況は関係者に常に共有できる状態にしておくことで、コミュニケーションの円滑化にもつながります。Dataikuでは、データの可視化とダッシュボードの構築が容易にできます。
図11:モニタリングダッシュボード
- ・データ品質の評価結果はデータセット化し、可視化
- ・モニタリングダッシュボードを構築
このようにオールインワンプラットフォームを利用すると、データ品質管理に必要なツールをシームレスに活用できるため、データ品質管理の仕組みを容易に構築することができます。また、Dataikuのようなノーコードツールであれば、業務部門のユーザー自ら実装し運用することも可能になるでしょう。実際にDataikuの導入したお客様では、内製開発からオールインワンプラットフォームにシフトしたことで、「乱雑に配備されたツール類による非効率さが解消された」といったことや、「そのデータが何を意味するのか、どこから得たデータなのかをスタッフが理解できデータ品質が向上できた」といった効果を述べられています。データ品質管理を継続的な取り組みとして定着させるには、オールインワンプラットフォームの導入も有効な方法の一つとなります。
おわりに
本コラムでは全3回にわたって、データ品質管理の重要性や進め方、効率的に運用するために必要なツールの整備、実践方法について解説してきました。
データから価値を効果的に引き出すにはデータ品質が重要になります。
データ品質管理は、データマネジメントにおける土台となる要素の一つで、企業のビジネス目的に沿った形で行われる戦略的な取り組みであり、DXおよびデータ駆動型ビジネスの成否を分けると言っても過言ではありません。
データ品質は一朝一夕に向上するものではなく、地道な取り組みになります。
データに求められる品質の要件はビジネス環境と共に変化し、テクノロジーの進化によっても変わってきます。決まった正解があるものではなく、繰り返し実施して改善する、これを業務に組み込んでいくことが重要です。データ品質は、常に業務と利用者のニーズを考えながらアクションを検討し実施することで改善されます。その取り組みは、企業の競争力を高め、目標に向かって前進させることにも役立つものと考えています。
データ品質管理の進め方やその実践方法について、本コラムが参考になれば幸いです。
- ※文章中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。