















第1回「テーブル・パーティショニングが大幅アップデート」
PostgreSQL 11では、デーブル・パーティショニング機能が大幅にアップデートされる予定です。本コラムでは2回に分けてテーブル・パーティショニング機能にどのような改善が導入されたかを徹底解説していきます。今回は、以下の機能を紹介します。
- ハッシュ・パーティショニング
- デフォルト・パーティション
- パーティションをまたがった更新
- インデックスの自動生成
ハッシュ・パーティショニング
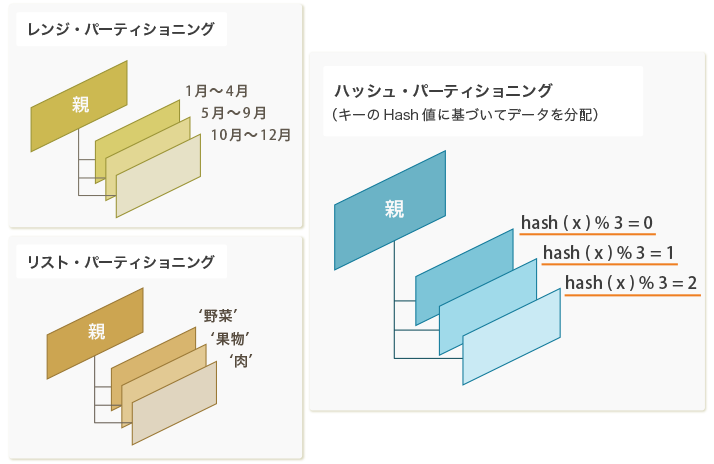
PostgreSQL10では、リスト・パーティショニングとレンジ・パーティショニングのみをサポートしていましたが、PostgreSQL 11にてハッシュ・パーティショニングが導入されました。
| 種類 | 特徴・利点 | よく使うキー |
|---|---|---|
| レンジ | ・各パーティションは同じ範囲内に入る行で構成される ・検索キーワードによって検索する子テーブルを絞り込む(パーティション・プルーニング)が可能 |
登録年月日など |
| リスト | ・離散的な列値を子テーブルに分割 ・データに順序や関連性がなくてもグルーピングが可能 |
商品カテゴリ、都道府県など |
| ハッシュ | ・各子テーブルにデータを(ほぼ)均等に分散 | 顧客番号など |
基本的な使い方
ハッシュ・パーティショニングを使用する場合、親テーブル作成時にHASH方式を選択します。
-- 親テーブルを作成 =# CREATE TABLE users (userid int, username text) PARTITION BY HASH(userid);
そして、子テーブルを作成する際には、「modulus n remainder i」と指定します。nにはHASH値の除数を指定し、iには剰余を指定します。つまり、パーティション・キーのHASH値をnで割った剰余を元に、格納される子テーブルが決定されます。そのため、各子テーブルでremainderは異なる数である必要があります。以下の例では、4つの子テーブルを作成しています。
=# CREATE TABLE users_0 PARTITION OF users FOR VALUES WITH (modulus 4, remainder 0); =# CREATE TABLE users_1 PARTITION OF users FOR VALUES WITH (modulus 4, remainder 1); =# CREATE TABLE users_2 PARTITION OF users FOR VALUES WITH (modulus 4, remainder 2); =# CREATE TABLE users_3 PARTITION OF users FOR VALUES WITH (modulus 4, remainder 3);
サンプルデータを投入し、各テーブルの状態を確認します。
=# INSERT INTO users SELECT id, 'user_' || id FROM generate_series(1,1000) id; INSERT 1000 =# SELECT relname, reltuples FROM pg_class WHERE relname LIKE 'users%' ORDER BY 1; relname | reltuples ---------+----------- users | 0 users_0 | 259 users_1 | 234 users_2 | 276 users_3 | 231 (5 rows)
ハッシュ・パーティショニングの分割数を増やす
テーブル・パーティショニング機能を利用していると、データ増加に合わせてテーブルの分割数を増やしたいケースがあります。例えば、レンジ・パーティショニングでは、新しいデータの範囲に対して子テーブルを追加することは容易ですが、ハッシュ・パーティショニングはその性質上、パーティション・キーのハッシュ値で子テーブルに均一に分割されているため、単純に子テーブルを追加するだけではできません。
PostgreSQLのハッシュ・パーティショニングでは、各テーブルのmodulusの値はすでに設定済みのmodulusの倍数であれば、異なる値を設定することができます。例えば、すでにmodulus = 4で設定されている場合は、次のmodulusとして8, 12, 16, 20...の値が指定できます。このような性質と、子テーブルのデタッチ機能を組み合わせることで、子テーブルの数を増やすことができます。
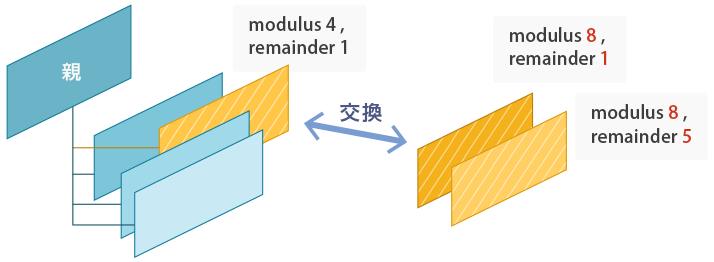
以下の例では、子テーブル(u_1)を一時的にパーティション・テーブルから取り外し(デタッチ)、同じ領域をカバーするmodulus = 8の子テーブルを2つ作成します。そして、元の子テーブル(u_1)のデータを親テーブルに挿入することで、新しく作成した2つの子テーブル(u_1とu_5)にデータを格納します。
=# ALTER TABLE users DETACH PARTITION users_1; ALTER TABLE =# ALTER TABLE users_1 RENAME TO users_1_old; ALTER TABLE =# CREATE TABLE users_1 PARTITION OF users FOR VALUES WITH (modulus 8, remainder 1); CREATE TABLE =# CREATE TABLE users_5 PARTITION OF users FOR VALUES WITH (modulus 8, remainder 5); CREATE TABLE =# INSERT INTO users SELECT * FROM users_1_old; INSERT 234 =# DROP TABLE users_1_old; DROP TABLE =# SELECT relname, reltuples FROM pg_class WHERE relname LIKE 'users%' ORDER BY 1; relname | reltuples ---------+----------- users | 0 users_0 | 259 users_1 | 124 users_2 | 276 users_3 | 231 users_5 | 110 (6 rows)
1つの子テーブルに格納されていたデータを2つの子テーブルに分割することができました。この操作を全ての子テーブルに行うことで、ハッシュ・パーティショニングの分割数を4から8に増やすことができます。
デフォルト・パーティション
PostgreSQL10のテーブル・パーティショニングでは、データの振り分け先となる子テーブルが存在しない場合は、エラーとなっていました。PostgreSQL 11のデフォルト・パーティションを利用することで、振り分け先がないデータが格納される子テーブルを作成することが可能です。なお、デフォルト・パーティションはレンジ・パーティショニングとリスト・パーティショニングでのみ有効です。
デフォルト・パーティションは、子テーブルを作成する際にDEFAULT句を指定します。
-- 親テーブルと2つの子テーブルを作成
=# CREATE TABLE foods (category text, name text) PARTITION BY LIST(category);
=# CREATE TABLE foods_vegitable PARTITION OF foods FOR VALUES IN ('vegitable');
=# CREATE TABLE foods_fruit PARTITION OF foods FOR VALUES IN ('fruit');
-- 'vegitable'と'fruit'は対応する子テーブルがあるため成功する
=# INSERT INTO foods VALUES ('vegitable', 'carrot'), ('fruit', 'apple');
INSERT 2
-- 'meat'、'fish'に対応する子テーブルがないので失敗する
=# INSERT INTO foods VALUES ('meat', 'pork'), ('fish', ' saury');
ERROR: no partition of relation "foods" found for row
DETAIL: Partition key of the failing row contains (category) = (meat).
-- 対応する子テーブルがない場合に追加するデフォルト・子テーブルを作成する
=# CREATE TABLE foods_default PARTITION OF foods DEFAULT;
CREATE TABLE
=# INSERT INTO foods VALUES ('meat', 'pork'), ('fish', ' saury');
INSERT 0 2
=# TABLE foods_default ;
category | name
----------+--------
meat | pork
fish | saury
(2 rows)
パーティション間の行の移動
PostgreSQL 10では、パーティションにまたがるUPDATEやINSERT ON CONFLICTが利用できませんでしたが、PostgreSQL 11で利用できるようになりました。デフォルト・パーティションに想定外の値を一時的に貯めておき、新しく作成した子テーブルにデータを移す、というようなデータを入れ直す使い方も可能になります。
=# CREATE TABLE foods_meet PARTITION OF foods FOR VALUES IN ('meet);
CRAETE TABLE
=# UPDATE foods SET category = 'meet' WHERE name = 'pork';
UPDATE 1
=# TABLE foods_meet;
category | name
----------+------
meet | pork
(1 row)
インデックスの自動生成
PostgreSQL 10では、各子テーブルへのインデックス作成は、テーブルごとに行う必要があるため、運用が煩雑になっていました。PostgreSQL 11では、親テーブルに作成されたインデックスは子テーブルにも自動的に作成されるようになりました。これにより、パーティション・テーブル全体での一意制約の付与など、インデックス管理が楽になります。
-- 親テーブルを主キーと共に作成
=# CREATE TABLE tbl_with_pk (c int primary key) PARTITION BY RANGE (c);
-- 子テーブルを2つ作成
=# CREATE TABLE tbl_1 PARTITION OF tbl_with_pk FOR VALUES FROM (0) TO (100);
=# CREATE TABLE tbl_2 PARTITION OF tbl_with_pk FOR VALUES FROM (100) TO (200);
=# \d tbl_with_pk
Table "public.tbl_with_pk"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+--------
c | integer | | not null |
Partition key: RANGE (c)
Indexes:
"tbl_with_pk_pkey" PRIMARY KEY, btree (c)
Number of partitions: 2 (Use \d+ to list them.)
-- 子テーブルにも自動的にインデックスが作成されている
=# \d tbl_1
Table "public.tbl_1"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c | integer | | not null |
Partition of: tbl_with_pk FOR VALUES FROM (0) TO (100)
Indexes:
"tbl_1_pkey" PRIMARY KEY, btree (c)
=# \d tbl_2
Table "public.tbl_2"
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
c | integer | | not null |
Partition of: tbl_with_pk FOR VALUES FROM (100) TO (200)
Indexes:
"tbl_2_pkey" PRIMARY KEY, btree (c)
上記例では、親テーブルに作成済みのインデックスが新規に作成した子テーブルに伝搬されましたが、親テーブルに対するインデックス作成時には、全ての子テーブルに対するインデックス作成が行われるため、本機能使用時はサーバへの負荷に注意してください。
まとめ
本記事では、PostgreSQL 11で導入されたテーブル・パーティショニングの機能改善の一部を紹介しました。これらの機能が導入された事により、より便利にテーブル・パーティショニング機能を利用することが出来るようになりました。PostgreSQL 11では、この他にも多くの機能改善が導入されています。第二回では、主にテーブル・パーティショニングの性能向上について解説するので、ご期待下さい。
(澤田 雅彦)
Tweet