
















<請求書データの自動抽出で作業時間を70%削減>紙をデータ化するAI技術を活用しバックオフィス業務を効率化
~次世代AI技術「フリーフォーム」を活用した社内実験で、高い文字認識精度を実証~
企業のデジタル化に向けた取り組みのなかで、バックオフィス分野でもテクノロジーとの融合による業務効率化が進んでいます。NTTデータ先端技術では、2020年10月から財務部門の業務効率化を目的に、次世代AI技術「フリーフォーム」を活用して社内実証実験を行っており、請求書から月次処理に必要な項目・データを自動抽出して業務システムと連携させることで、請求書データ入力関連業務の作業時間を70%削減することができました。
「AI-OCR」の課題であった、文字列の位置指定の手作業が不要に!
NTTデータ先端技術ではこれまでも、AIを使った紙のテキストデータ化で広く普及している「AI-OCR」を試験的に導入していましたが、請求書は取引先ごとにフォーマットが異なり、また備考欄など表内の自由な位置に情報が記入されていることもあるため、 文字列の位置指定を必須とする特性の「AI-OCR」では、読み取りたい文字列の位置を都度手作業で指定しなければならないことが課題でした。
この課題を解決し業務効率化を図るため、テキストデータ化の次世代AI技術であるフリーフォームを使用した社内実証実験を行い検証することにしました。フリーフォームは、ディープラーニングをベースとしたフィールド自動特定技術と帳票レイアウト認識技術により、文字位置を高精度に自動で抽出し、手作業による文字列の位置指定を不要にする技術です。また、言語モデルの使用により文字認識で誤認識をした場合でも結果を補正します。加えて、一般的な「AI-OCR」では困難とされる表の項目抽出にも対応することができます。
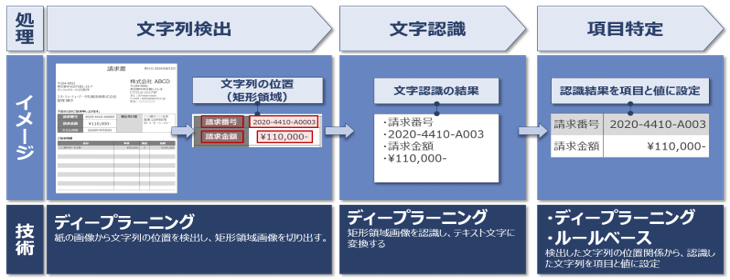
表1:フリーフォーム技術のイメージ
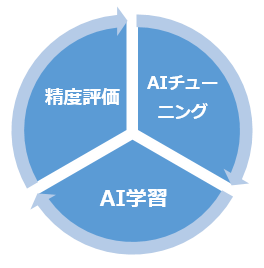
図1:フリーフォーム認識の検証の流れ
こ実証実験前には、事前評価やAIの精度評価が必要です。今回の実証実験を行うにあたり事前準備として、評価用の請求書を利用して、AIチューニング、AI学習、精度評価を繰り返し実施しました。そこで精度評価されたAIを活用して実証実験を行いました。
社内実証実験では、4社の請求書を対象として、「紙の保存状態が悪い(文字がかすれていたり不鮮明)請求書」、「読み取りたい文字列が表外または表内の固定された位置にない請求書」、「読み取りたい文字列が表内の罫線をまたぐ請求書」などを20~100枚程度準備し、文字列の位置特定と文字認識精度を評価しました。その結果、 認識精度は9割と高く、4社中3社の請求書で認識精度が97%を超える結果となり、高い効果が示されました。今後、請求書のみならず様々な紙文書での展開も期待できます。
※当社の実証実験には、NTTデータのAI技術センタが研究・開発した「フリーフォーム認識」と、AlgoAnalytics社の技術を活用しました。
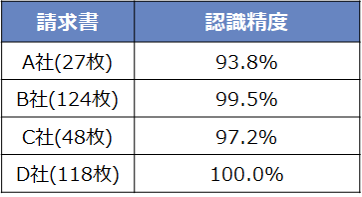
表2:社内実証実験での認識精度
バックオフィス業務の効率化・自動化ソリューション「PhroneCore」
大きな転換点を迎えているバックオフィス分野においてAI導入が注目されているなか、NTTデータ先端技術では、バックオフィス業務の自動化・効率化に向けた先進自然言語処理ソリューション「PhroneCore(プロネコア)」を2020年12月より提供開始しました。PhroneCoreは、バックオフィス業務に必要となる文書分類、知識読解、自動要約など様々な言語理解が可能な各種AI機能を備え、必要に応じた機能のみを組み合わせ業務システムなどと連携することで、コストを抑えながら業務への迅速なAI適用を実現します。本ソリューションには今後、社内実証実験でも高い効果を発揮した次世代AI技術「フリーフォーム」を組み込む予定で、更なる機能強化を加速していきます。
PhroneCoreでは、文脈を理解することができる最新の自然言語処理技術「BERT」(※1)を活用しており、少ない学習データでも高精度な文書理解が可能で、営業日報や請求書等の内容分析等、文書の整合性やリスクチェック等、幅広いバックオフィス業務の自動化・効率化を実現します。また、バックオフィス業務のDX化を推進することで、AIで対処できるプロセスはAIに任せ、組織内外の環境変化や非定型的な事象が発生しやすいプロセスに、知識・経験を有する社員を配置することができます。例えば、内部統制のような業務は、変化していく組織や環境に対応する必要がありシステム化が難しい分野です。PhroneCoreのようなソリューションを導入することで、業務の効率化のみに留まらず、社員のリソースを適切な業務に集中させることにも寄与します。
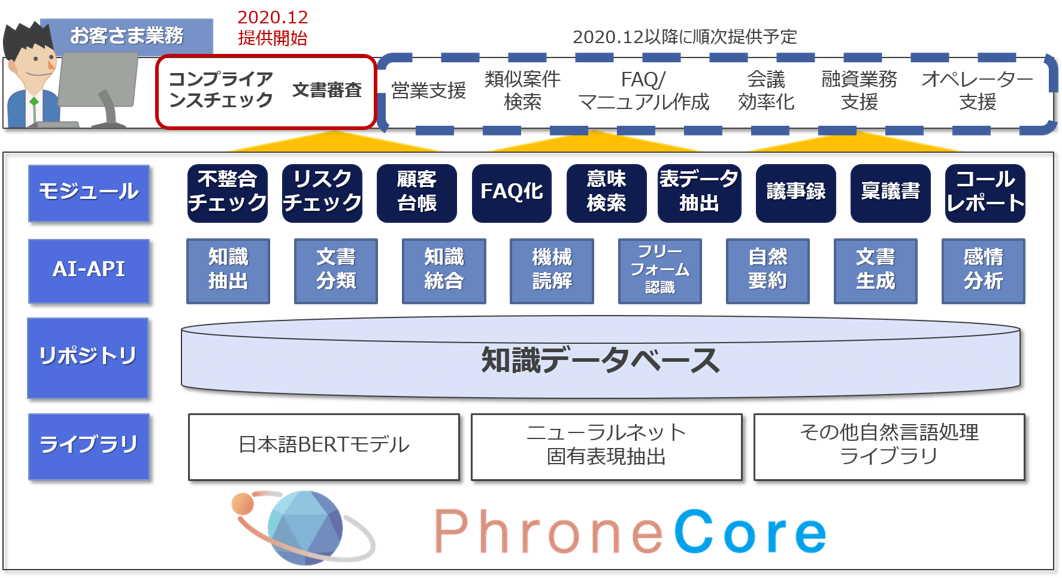
図2:「PhroneCore」のソフトウエア構成
- ※1:「BERT(Bidirectional Encoder Representations from Transformers)」とは2018年10月にGoogleが発表した自然言語処理モデルであり、自然言語処理分野のさまざまなベンチマークにおいて従来モデルの精度を上回るなど近年非常に注目されています。
NTTデータ先端技術について
NTTデータ先端技術は、NTTデータグループの技術面を支える中核会社として1999年に設立されました。基盤・ソフトウェア・セキュリティの3本柱のソリューション事業を通じて、お客様に価値を提供することを目指しています。NTTデータ先端技術に関する詳細な情報については、https://www.intellilink.co.jp/ をご覧ください。
本件に関するお問い合わせ先
NTTデータ先端技術株式会社
NTTデータ先端技術株式会社
営業統括本部
営業企画推進部
企画担当
TEL:03-5843-6860