
















1. 概要
近年、自然言語処理分野において、汎用的な大規模言語モデルの開発が世界中で活発に行われています。「汎用的な大規模言語モデル」とは、大規模なテキストデータを事前に学習し、わずか数例のタスクを与えただけでさまざまな言語処理タスク(文章生成、穴埋め問題、機械翻訳、質問応答など)を解くことができる言語モデルのことです。
(文章生成の汎用的な大規模言語モデルとしては、「GPT-3」が有名ですが、そちらの紹介は以下のコラムで行っておりますので、よろしければご参照ください。)
コラム:自然言語処理モデル「GPT-3」の紹介:https://www.intellilink.co.jp/column/ai/2021/031700.aspx
こうした中、2022年3月28日に、東京大学松尾研究所発のAI(人工知能)スタートアップである株式会社ELYZA(イライザ)は、キーワードから日本語の文章を生成できる大規模言語モデルの開発に成功したと発表※1、文章執筆AIのデモサイト「ELYZA Pencil」として一般公開を開始しました。
「ELYZA Pencil」では、キーワードを数個入力すると、約6秒で日本語のニュース記事やメール文、職務経歴書の3種類が作成されます。キーワードから文章生成できる日本語AIとしては初の一般公開になるそうです。
「ELYZA Pencil」:https://www.pencil.elyza.ai/
上記の通り、近年は自然言語処理分野の技術を利用してさまざまなサービスが開発されています。当社も2020年に「INTELLILINK バックオフィスNLP」という自然言語処理技術を利用したソリューションを発表しました。詳細はここでは割愛しますが、本ソリューションも「ELYZA Pencil」のように、バックオフィス業務で必要となる記事タイトル生成機能や文書要約機能のような文書生成も可能です。
さて、今回のコラムを執筆する大きな動機となったものは、汎用的な大規模言語モデルの中で、「日本語に特化した」汎用的な大規模言語モデルが開発されてきているという情報があり、さらに調査を行いたいというものでした。また調査で得た知見をINTELLILINK バックオフィスNLPの方にも活用したいという気持ちもありました。
前置きが長くなってしまいましたが、本コラムでは、日本語に特化した汎用的な大規模言語モデルについてご紹介していきたいと思います。
2. 現在の言語モデルの傾向
2020年5月にGPT-3(Generative Pre-Training-3)が登場して以降、言語モデルの大規模化が引き続き行われています。
言語モデルの性能を表す一つの指標であるパラメータ数で見ると、GPT-3は1750億のパラメータを使用しています。これはGPT-2のパラメータが約15億に対して約117倍以上になります。一方、同時期の2020年6月にGoogle社が、6000億のパラメータの「GShard」を発表しました※2。その後、Google社傘下のGoogle Brainは、2021年1月に最大1兆6000億のパラメータを持つSwitch Transformerをオープンソース化しました※3。さらに中国政府による資金援助を受けている北京智源人工知能研究院が主導する研究チームは、2021年6月1日に新たな事前学習モデルである「悟道2.0(WuDao 2.0)」を発表しました※3。悟道2.0は1兆7500億ものパラメータを使用しています。
また、最近では2022年1月にGoogleの子会社でありAlphaGoを開発したDeepMind社が、最大で2800億のパラメータを持つGopherと名付けられた言語モデルを発表しました※4。
このように、言語モデルの大規模化は現在の言語モデルの傾向であり、前述したDeepMind社によると、言語モデルの大規模化は引き続き効果的だと判断されています※5。
以下は各言語モデルとそのパラメータ数を記載した表です。
| モデル名 | パラメータ数 | 開発元 |
|---|---|---|
| GPT-3 | 1750億 | OpenAI |
| GShard | 6000億 | Google社 |
| Switch Transformer | 1兆6000億 | Google Brain |
| 悟道2.0 | 1兆7500億 | 北京智源人工知能研究院 |
| Gopher | 2800億 | DeepMind社 |
| 日本語GPT言語モデル | 13億 | rinna社 |
| HyperCLOVA | 820億(2022年1月時点) | LINE社、NAVER社 |
日本語に特化した汎用的な大規模言語モデルとしては、rinna社が開発中の日本語GPT言語モデルや世界初の日本語に特化した汎用的な大規模言語モデルであるLINE社とNAVER社で共同開発中の「HyperCLOVA」があります。「HyperCLOVA」では、1750億以上のパラメータと100億ページ以上の日本語データを、学習データとして利用予定です。
表に示しているrinna社の日本語GPT言語モデルとLINE社のHyperCLOVAは、現時点で公開されている中で最大のパラメータ数を記載していますが、これを見ると、日本語に特化した汎用的な大規模言語モデルは英語圏や中国語圏のそれと比較し、現時点ではまだ規模が小さいと言えます。
3. 「日本語に特化した言語モデル」が直面する言語固有の課題
なぜ英語圏や中国語圏の汎用的な大規模言語モデルと比較して、日本語に特化した汎用的な大規模言語モデルが小規模に留まっているのでしょうか。これには、日本語固有の課題や難しさがあります。 最初の課題として、これまで言語モデルで日本語を使用する際、コーパス(と呼ばれる自然言語の文章を構造化して大規模に集め、品詞等の言語的な情報を付与したもの)が少なかったり、例えあったとしても、テキスト内にノイズがたくさん存在しているため、使用する際に上手く除去しなければいけませんでした。
また、インターネット上のテキストはウィキペディアのコピーが多く、教師データとして適切なものが少ないということもあります。共通語である英語であればデータ量もさることながら、研究者同士のつながりで質の良いデータが共有されることに対し、日本語はこれと比較して、データ量・研究者間のデータ共有数ともに量は多くありません。
さらに日本語独自の難しさとして、以下が挙げられます。
- 日本語は語順の自由度が高いことや、日常における必須語が多い。
- さまざまな表記や同じ音で異なる語が存在する。
- 方言の多様性で同じ意味の単語でも日本全国で異なる単語の組み合わせになる。
- 日本語の話者はひらがな・カタカナ・漢字・ローマ字など、さまざまな文字を使って1つの文章を作り、同じ単語を複数回表記する場合には書き方を変える。
- 日本語の話し言葉は文中の主語や目的語を省略しがちなので、テキストを読む際には、その文中の単語の省略を考慮しながら意味を解釈していく必要がある。
日本語に特化した汎用的な大規模言語モデルが作られれば、これらの問題を解消することができ、さらに日本語の会話や文章を正確に推定することができるようになります。
さて、ご紹介した通り、日本語に特化した汎用的な大規模言語モデルの開発にはさまざまな難しさが存在します。このような中、rinna社の日本語GPT言語モデルとLINE社のHyperCLOVAは、これらの課題にどう対応しているのでしょうか。
本コラムの後編では、両モデルの詳しい仕組みについて解説していきます。
関連リンク
INTELLILINK バックオフィスNLPは、最新の自然言語処理技術「BERT」を用いて、少ない学習データで高精度の文書理解が可能です。また、文書の知識を半自動化する「知識グラフ」を活用することで、人と同じように文章の関係性や意図を理解することができます。
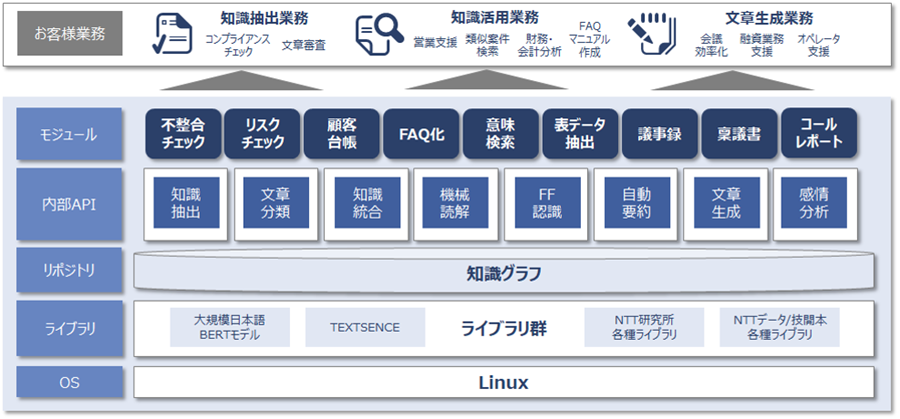
図:INTELLILINK バックオフィスNLPのソフトウエア構成図
引用元
※文章中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。