
















前編では、各国で開発が進む大規模言語モデルの傾向と、日本語独自の課題をご紹介しました。(https://www.intellilink.co.jp/column/ai/2022/070800.aspx)
後編では、日本語に特化した大規模言語モデルの具体例として、rinna社の日本語GPT言語モデルとLINE社のHyperCLOVAをご紹介します。
1. rinna社の日本語GPT言語モデル
Microsoft社のAI&リサーチ部門でAIチャットボットの研究を行っていたチームがスピンアウトして2020年6月に設立したAIキャラクター開発企業であるrinna社※1は、日本語に特化した13億パラメータのGPT言語モデルを公開しました。
(1)背景※1
rinna社はこれまでに、日本語の自然言語処理(NLP)に特化したGPT(3.3億パラメータ)やBERT(1.1億パラメータ)の事前学習モデルを公開し、多くの研究・開発者に利用されていました。また、最近のNLPに関する研究では、モデルのパラメータ数が多いほど高い性能であることが知られています。
そこでrinna社は、これまでに公開してきたモデルより大規模な、13億パラメータを持つ日本語に特化したGPT言語モデルを開発し、日本語のNLPコミュニティに貢献するために、この言語モデルをNLPモデルライブラリ「Hugging Face」に、商用利用可能なMITライセンスで公開しました。これは、日本語に特化した学習モデルのパラメータとしては、以前のGPTと比較して約3.9倍、BERTと比較して約11.8倍になります。
NLPモデルライブラリ Hugging FaceのURLは、以下の通りです。
https://huggingface.co/rinna/japanese-gpt-1b
(2)日本語GPT言語 モデルの機能※2
日本語GPT言語モデルは、会話や文章の「人間が使う言葉」を確率としてモデル化します。優れた言語モデルとは、確率を正確に推定できるものを指します。例えば、“確率(吾輩は猫である)>確率(吾輩が猫である)”と推定できることが、言語モデルの能力です。これは、"吾輩は猫である"の方が、"吾輩が猫である"より高い確率で起こりえるということを表しています。
日本語GPT言語モデルは、単語の確率の組み合わせから次の単語の確率を計算する言語モデルです。例えば、確率(吾輩は猫である)=確率(吾輩)×確率(は|吾輩)×確率(猫|吾輩,は)×確率(で|吾輩,は,猫)×確率(ある|吾輩,は,猫,で)”のような方法で計算を行います。確率(A|B)は、確率(B)が起こるという条件のもとで確率(A)が起こる確率を表します。この性質を用いて、日本語GPT言語モデルは「吾輩は」という単語を入力したとき、次の単語として確率が高い「猫」を予測することができます。
また、以下の図は日本語GPT言語モデルに「吾輩」が入力された後、「は」、「猫」、「で」、「ある」と続く場合のイメージ図です。
この場合の確率は、以下の通り計算されます。吾輩の確率は1であるとします。
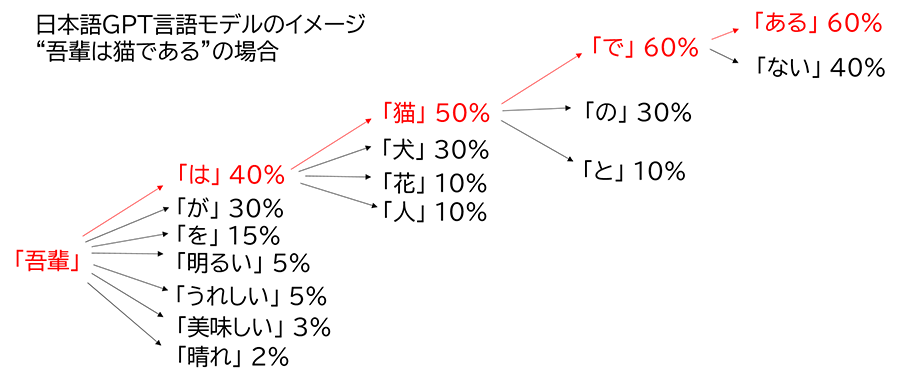
確率(吾輩は猫である)=1(吾輩の確率)×0.4((は|吾輩)の確率)×0.5((猫|吾輩,は)の確率)×0.6((で|吾輩,は,猫)の確率)×0.6((ある|吾輩,は,猫,で))の確率
=0.072
一方、以下の図は日本語GPT言語モデルに「吾輩」が入力された後、「が」、「猫」、「で」、「ある」と続く場合のイメージ図です。
この場合の確率は、以下の通り計算されます。吾輩の確率は1であるとします。
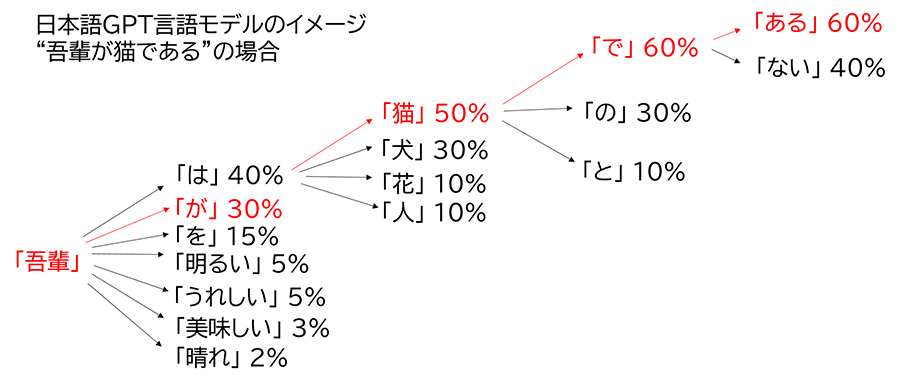
確率(吾輩は猫である)=1(吾輩の確率)×0.3((が|吾輩)の確率)×0.5((猫|吾輩,は)の確率)×0.6((で|吾輩,は,猫)の確率)×0.6((ある|吾輩,は,猫,で))の確率
=0.054
以上から、確率(吾輩は猫である)=0.072、確率(吾輩が猫である)=0.054となり、確率(吾輩は猫である)>確率(吾輩が猫である)となることが分かりました。このように優れた言語モデルは、「人間が使う言葉」を正確に推定します。
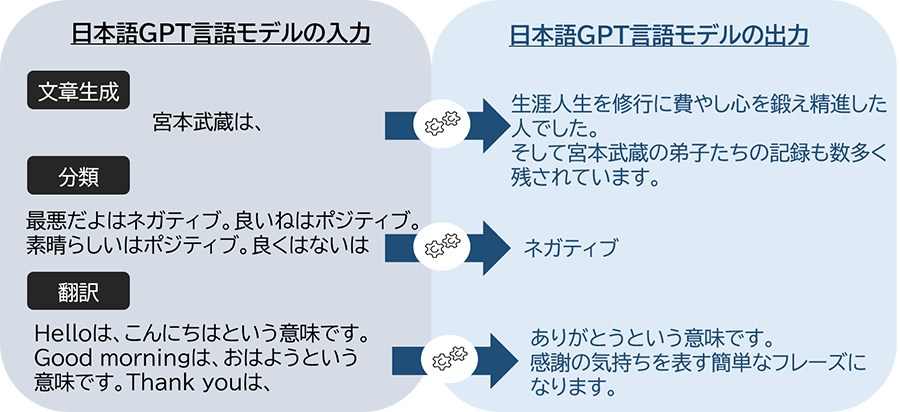
今回、rinna社が公開した日本語GPT言語モデルは、一般的な日本語テキストの特徴を持つ高度な日本語文章を自動生成できます。例えば日本語GPT言語モデルに入力するテキスト(テキストプロンプト)を工夫することで、以下のような文章生成、分類、翻訳などの出力を得ることができます(出力は確率に基づき、毎回異なるテキストが生成されます)。
(3)rinna社の日本語GPT言語 モデルの特徴※2
- ●学習データとして、日本語のC4 、CC-100 、Wikipediaのオープンソースデータを使用しています。
- ●モデルは十分に学習されており、その性能は約14 perplexityを達成しています。
※14 perplexityとは、日本語GPT言語モデルが次の単語を予測するときに、単語候補の数を14に絞れる性能を意味します。 - ●利用者が簡単にアクセスできるように、開発したモデルを Hugging Face に商用利用可能なMITライセンスで公開しています。
- ●利用者の目的に沿った多様なタスク(ドメインに特化した文章生成、分類、翻訳など)を、テキストプロンプトやファインチューニングにより実現できます。
(4)rinna社の日本語GPT言語モデルのまとめ
rinna社が公開している日本語GPT言語モデルのパラメータ数や学習データセットは以下の通りです※3。
| 日本語モデル名 | 層 | 隠れ層 | パラメータ数 | 学習データ |
|---|---|---|---|---|
| japanese-gpt-1b | 24個 | 2,048個 | 13億 | Japanese C-4 Japanese CC-100 日本語Wikipedia |
| japanese-gpt2-medium | 24個 | 1,024個 | 3.36億 | Japanese CC-100 日本語Wikipedia |
| japanese-gpt2-small | 12個 | 768個 | 1.1億 | Japanese CC-100 日本語Wikipedia |
| japanese-gpt2-xsmall | 6個 | 512個 | 0.37億 | Japanese CC-100 日本語Wikipedia |
ここでいうJapanese C-4とは、googleのmc4(多言語Webコーパス)のデータセットをMicrosoftの共同創設者であるPaulAllenによって設立された研究所のallenai(Allen Insutitute for AI)が言語ごとにダウンロードできるように前処理をした後の、日本語部分になります。C-4のURLは以下になります。
https://huggingface.co/datasets/allenai/c4
Japanese CC-100は、Facebook 製 XLM-R 用のデータセットの日本語部分になります。Japanese CC-100のURLは、以下になります。
http://data.statmt.org/cc-100/
(5)日本語データセットの紹介
この章では、HuggingFace Dataset Hub(https://huggingface.co/datasets)で公開されている日本語データセットの中から、いくつかのデータセットをご紹介します※4。Huggingface Datasetsは、パブリックなデータセットの「ダウンロード」と「前処理」の機能を提供する軽量ライブラリです。紹介する日本語データセットは以下の通りです(前章で紹介したJapanese CC-100、Japanese C-4も含まれます)。
- ●CC-100:Facebook 製 XLM-R 用のデータセット
- ●mc4:googleのmc4のデータセットをallenaiが前処理したバージョン
- ●oscar: inria.fr製
- ●amazon_reviews_multi: amazon のレビュー
各データセットの日本語データセットは以下の通りです。
| データセット | エントリ数 | データセットサイズ | ダウンロードサイズ |
|---|---|---|---|
| Japanese CC-100 | 458,387,942 | 82GB | 15GB |
| mc4(Japanese C-4) | 87,337,884 | 830GB | 316GB |
| oscar(original_ja) | 62,703,315 | 232GB | 79B |
| oscar(deduplicated_ja) | 39,496,439 | 113GB | 40GB |
| amazon_reviews_multi(ja) | 2,000,000 | 0.086GB | 0.177GB |
ここで、Japanese CC-100のエントリ数がmc4(Japanese C-4)より大きいにも関わらずデータセットサイズやダウンロードサイズが小さいのは、mc4(Japanese C-4)の1件当たりのtextデータがJapanese CC-100のtextデータより長く、データとして大きくなるためです。
2. LINE社の日本語に特化した大規模汎用言語モデルHyperCLOVA
2020年11月にLINE社はNAVER社と共同で日本語に特化した言語モデルをGPT-3レベルで開発するというニュースがありました※5。その後、LINE社は2021年7月のLINE AI DAYで日本語に特化した大規模汎用言語モデル「HyperCLOVA」の開発を発表しました※6。
(1)HyperCLOVAとは何か
HyperCLOVA は、1,750億以上のパラメータと100億ページ以上の日本語データを学習データとして利用予定の、世界初の日本語に特化した大規模汎用言語モデルです。膨大なデータを学習させたモデルにより、少量の言語をインプットすることで、文脈にあった言語処理を可能にしたり、人間との自然な対話が可能になります※5。実際、2021年11月に開催されたLINE DEVELOPER DAY 2021では、HyperCLOVAを応用した対話システムと人の滑らかな会話や商品の説明文を生成するデモ、質問応答タスクの性能の高さなどが紹介されています※7。さらに2021年12月に、HyperCLOVAは、第12回対話システムシンポジウムにおいて2部門で1位を獲得しています※8。対話システムシンポジウムは、対話システムを最前線で研究・開発する方々が集い、最新の対話モデルのAIを活用し、どれくらい滑らかに対話ができるか、音声認識ができるかなどが評価されるシンポジウムです。
(2)現在のモデルのパラメータ数
現在はパラメータ数が67億、130億、390億の3つのモデルがあり、390億モデルでは、会話の滑らかさ、そしてトピックの追従度は98パーセントの性能を誇っています。また、2022年1月時点では、820億のモデルの開発が進んでいます※9。さらに、2022年中には、2,040億以上の日本語モデルが活用されていくとのことです※7。
(3)コーパス
言語モデルを構築する際、重要になるのがモデル構築に使うコーパスです。LINE社ではお客様がLINEで送受信されたメッセージはもちろん、オープンチャットのトークルームの書き込みを含め、LINEのサービスに関するデータは一切使用しておらず、サブセットの外部提供の可能性も含めて、社内外でなるべく汎用的に利用できるよう、さまざまな権利関係に最大限の配慮をしながら整備を続けているとのことです。また、このようなポリシーのもと、構築しているLINE LM Corpusは、2019年以降BERTのモデル構築のために作られたコーパスをベースに、個人情報を削除し、外部コンテンツの購入と利用に関しては権利問題を解決したうえで実施されています。このようにして構築したLINE LM Corpusは、約100億サンプル、約1.8テラバイト、約5,000億トークンに達しています※7。このコーパスは毎月更新しており、徐々にサイズと品質が向上しています。
(4)巨大なインフラ環境
大規模な汎用言語モデルを学習したり運用するには、大規模なインフラが必要になります。そこで、LINE社はNAVER社と共同で、HyperCLOVAを迅速かつ安全に処理できる700ペタフロップス(PF=1秒間に1,000兆回の浮動小数点演算を行う能力)以上の性能を備えた、世界でも有数のスーパーコンピュータを活用し、HyperCLOVAの土台となるインフラの整備をしているそうです※5。
3. フリーで使用できる日本語に特化した汎用的な大規模言語モデル
この章では、要約や質問応答、対話など主に文章生成タスクに使用するモデルで、現在フリーで使用できる日本語に特化している汎用的な大規模言語モデルについてまとめます※10。
| 日本語モデル名 | モデル名 | 学習データ | 開発元 | HuggingFaceで使用できるか |
|---|---|---|---|---|
| japanese-gpt-1b | GPT | Japanese C-4 Japanese CC-100日本語Wikipedia |
rinna社 | 〇 |
| japanese-gpt2-medium | GPT-2(medium) | Japanese CC-100 日本語Wikipedia |
rinna社 | 〇 |
| japanese-gpt2-small | GPT-2(small) | Japanese CC-100 日本語Wikipedia |
rinna社 | 〇 |
| japanese-gpt2-xsmall | GPT-2(xsmall) | Japanese CC-100 日本語Wikipedia |
rinna社 | 〇 |
| 早大GPT-2 | GPT-2(small) | Japanese CC-100 日本語Wikipedia |
早大 河原研 | 〇 |
| 日本語BART | BART(base,large) | 日本語Wikipedia (約1800万文) |
京大 黒橋研 | - |
| 日本語T5 | T5(base) | mc4データセット内の日本語 wiki40bデータセット内の日本語 |
Megagon Labs | 〇 |
ここで、「HuggingFaceで使用できるか」については、HuggingFaceのModel Hubにモデルがアップロードされており、AutoModelForCausalLM.from_pretrained(rinna社)やGPT2Model.from_pretrained(早大 河原研)、T5ForConditionalGeneration.from_pretrained(Megagon Labs(リクルート))等ですぐに読み込めるものを「〇」にし、モデルの参照元へのリンクを付けています。
4. 多くの企業で開発が進む自然言語モデル
2022年の自然言語モデルの傾向は、引き続き言語モデルの大規模化が進んでいくと考えられます。2022年4月には、Google社がGPT-3の約3倍となる5,400億パラメータを持つPathways Language Model(以下、PaLM)※11を発表しました。PaLMは、多くの評価タスクでAI史上最高の精度であることが証明されており、論理的な推論やジョークを説明するタスクについても強力な結果を示しています。
一方、最近のトレンドとして、DeepMind社が発表したRETRO(Retrieval-Enhanced Transformer)※12などは、モデル自体は小さくて良いという方向性も示されています。RETROは、AIに外部記憶装置を取り付けて機能を強化するというアイディアです。記憶装置に巨大なデータを格納し、AIがそれをカンニングペーパーのようにして新しい文章を作成します。RETROの性能は、25倍の規模のニューラル・ネットワークを有するモデルに匹敵し、巨大なモデルの学習に必要な時間とコストを削減できます。この場合、モデル自体は小さくても大規模なデータを整備する必要があります。また、GPT-3を開発したOpenAIは、2022年1月にInstructGPT※13と呼ばれる最新の言語モデルを発表しました。この言語モデルは、人工知能の専門用語で「アラインメント」という技術を採用しており、使用する人の指示に上手く従うことができます。そのため、明示的に言われない限り、攻撃的な言葉や誤った情報を生み出すことが少なくなっており、全体的にミスが少ないそうです。OpenAIの開発チームは、完全に訓練されたGPT-3モデルから始めて、新たな訓練を追加で実施することで、有害な言葉やデマをデータセットから削除した際、言語モデルの性能が低下してしまう問題を回避しました。追加で実施した訓練とは、強化学習を用いて、人間のユーザーの好みに応じて、いつ、何を言うべきかを言語モデルに教えることでした。さらにInstructGPTの異なるサイズのバージョンの比較をしたところ、1,750億パラメータのGPT-3と比べ、ユーザーは100倍以上小さい13億パラメータのInstructGPTのモデルの回答の方を好むことが分かりました。開発者は、「アライメント」は、言語モデルのサイズを大きくするためでなく、言語モデルを改良するための、より簡単な方法となる可能性があると述べています。
5. 予想される.GPT-4の特徴※14
上述したものに加えて、GPT-4の発表が近いうち(2022年7月~8月)に行われるだろうということが予想されています。GPT-4の特徴として予想されていることを2点ご紹介します。
- (1)パラメータ数の大規模化主義からの方向転換
- (2)小さい言語モデルから最大の性能を引き出す
(1)の「パラメータ数の大規模化主義からの方向転換」では、GPT-4はGPT-3のパラメータ数とそこまで大きくは変わらないだろうと言われています。具体的には、GPT-4のパラメータ数は、GPT-3とGopherの中間(1,750億~2,800億パラメータ)になると予測されています。これは、GPT-3以降続いている自然言語モデルの大規模化の傾向と比べると、パラメータ数が際立った特徴になるわけではないということを示しています。
(2)の「小さい言語モデルから最大の性能を引き出す」とは、言語モデルにおけるモデルサイズと学習データにおいて最適な関係を特定できれば、その関係性を満たす言語モデルは最大級の言語モデルよりサイズが小さいにも関わらず、性能はそれらを超えるということが分かってきました。具体的には、最適なハイパーパラメータのセット、最適な計算モデルとパラメータ数等の最適化が必要になると言われています。そのため、GPT-4はGPT-3に比べ多くの計算が必要になります。また、小さい言語モデルの性能を向上させるためには、同じ予算を掛けるならば、モデルのサイズを大きくするよりも学習データを増やす方が有効なことが分かっています※15。具体的には、DeepMind社のGopher(2,800億パラメータ)と、モデルとしてはGopher の1/4倍のChinchilla(700億パラメータ)にGopherの4倍の学習データで訓練するとChinchillaの方の性能が良くなったという実験結果も出ています※16。 これらをまとめますと、小さい言語モデルで性能を引き出すためには、大量の学習データを使用し、言語モデルの最適なパラメータの計算をすることが必要であり、それらを満たすことで、大きいサイズの言語モデルの性能を超えていけるということです。
これまでご紹介してきたRETROやInstructGPT、GPT-4のように 技術を用いて言語モデル自体の規模を小さくすることは、言語モデルの費用面や運用面からユーザーが利用しやすくなる点においても、今後のトレンドの一つになる可能性があります。
6. 汎用的な大規模言語モデル「日本語に特化した自然言語モデル」の今後
最後に今回タイトルにも関係がありますが、汎用的な大規模言語モデルの多言語化もトレンドの一つになると考えられます。これは、主に英語圏で活発だった汎用的な大規模言語モデルを英語圏以外の言語に特化した、汎用的な大規模言語モデルを作ろうとする試みです。ここでの課題は、英語圏以外のデータセットを使用して英語圏のデータセット並みに精度が出せるかということです。日本語の場合、日本語独自の必須単語の多さや文脈の難しさがあるため、英語圏のデータセットと同じ学習方法では英語圏ほど精度が出ないことがあります。
最近では上述したように日本語のデータセットが充実してきましたが、今後さらなる大規模なデータセットの整備は、日本語に特化した自然言語モデルの課題の一つであり、今後はさらに日本語で使用できる大規模なデータセットが増えていくのではないかと思います。
引用元
- ※1https://rinna.co.jp/
- ※2https://prtimes.jp/main/html/rd/p/000000025.000070041.html
- ※3https://github.com/rinnakk/japanese-pretrained-models
- ※4https://tech.yellowback.net/posts/datasets-japanese
- ※5https://linecorp.com/ja/pr/news/ja/2020/3508
- ※6https://linecorp.com/ja/pr/news/ja/2021/3828
- ※7https://logmi.jp/tech/articles/325452
- ※8https://blog.clova.line.me/hyperclova-202112
- ※9https://ainow.ai/2022/01/31/262132/
- ※10https://zenn.dev/hellorusk/articles/ddee520a5e4318
- ※11https://www.infoq.com/jp/news/2022/05/google-palm-ai/
- ※12https://www.technologyreview.jp/s/263211/deepmind-says-its-new-language-model-can-beat-others-25-times-its-size/
- ※13https://www.technologyreview.jp/s/267557/the-new-version-of-gpt-3-is-much-better-behaved-and-should-be-less-toxic/
- ※14https://ainow.ai/2022/05/23/264997/
- ※15https://www.deepmind.com/publications/an-empirical-analysis-of-compute-optimal-large-language-model-training
- ※16https://towardsdatascience.com/a-new-ai-trend-chinchilla-70b-greatly-outperforms-gpt-3-175b-and-gopher-280b-408b9b4510
※文章中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。