
















自然言語処理モデル「GPT-3」の紹介
1. 概要
近年、ディープラーニングの自然言語処理分野の研究が盛んに行われており、その技術を利用したサービスは多様なものがあります。
当社も昨年2020年にINTELLILINK バックオフィスNLPという自然言語処理技術を利用したソリューションを発表しました。INTELLILINK バックオフィスNLPは、最新の自然言語処理技術「BERT」を用いて、少ない学習データでも高精度の文書理解が可能です。また、文書の知識を半自動化する「知識グラフ」を活用することで人と同じように文章の関係性や意図を理解することができます。INTELLILINK バックオフィスNLPを利用することで、バックオフィス業務に必要となる「文書分類」「知識抽出」「機械読解」「文書生成」「自動要約」などさまざまな言語理解が可能な各種AI機能を備えており、幅広いバックオフィス業務の効率化を実現することが可能です※1。
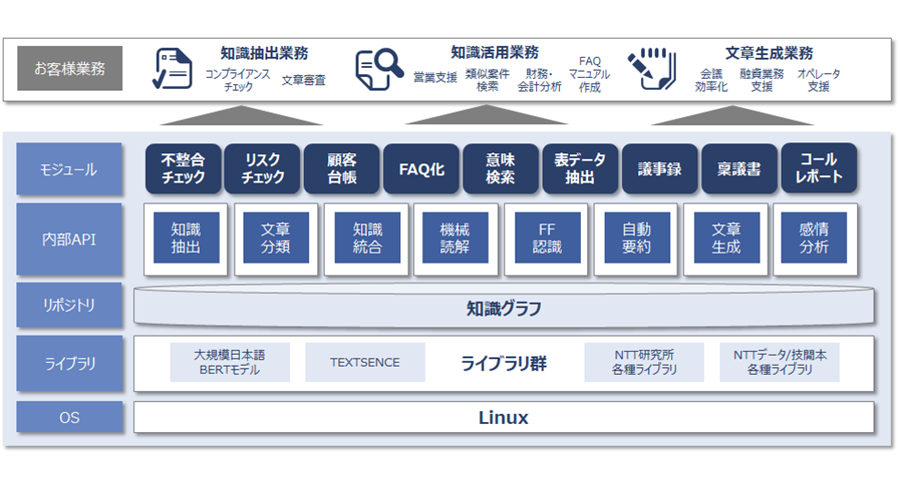
図:INTELLILINK バックオフィスNLPのソフトウエア構成図
こうした中、2020年に「GPT-3(Generative Pre-Training-3、以下GPT-3)」が登場し自然言語処理分野に大きな衝撃を与えました。さらに、日本でもLINE社が日本語の自然言語処理モデルをGPT-3レベルで開発するというニュース※2がありました。
そこで、本コラムでは数ある自然言語処理分野の中からGPT-3についてご紹介したいと思います。
2. GPT-3とは
GPT-3は2015年12月にイーロン・マスクなど有力な実業家・投資家が参加したことで注目を集めたOpenAIが開発している言語モデルの最新版のことです。
約45TBの大規模なテキストデータのコーパスを約1750億個のパラメータを使用して学習するため、高い精度である単語の次にくる単語の予測を可能にし、あたかも人間が書いたような文章を自動で生成します。
それでは、ある単語の次に来る単語の予測とはどのようなものでしょうか。例えば「明日の天気は」という単語列を与えた場合、次に来る単語の確率が、晴れ:40%、曇り:30%、雨:15%、明るい:5%、うれしい:5%、美味しい:3%、は:2%だとすると、「明日の天気は」の後に続く単語は天気を表す単語「晴れ」、「曇り」、「雨」の順に確率が高いことになり、「明るい」、「うれしい」、「美味しい」、「は」になる確率は低いと言えます。GPT-3は、このようにある単語の次に来る単語を高い精度で予測していくことで自動的に文章を完成させます。

図:言語モデルのイメージ
GPT-3のライセンスは、2020年Microsoft社がOpen AIから独自ライセンスを取得しています。また、GPT-3はオープンソースとして提供されておらず、現在Open AIのAPIを介して利用できるようになっています。ただし、APIの利用には申請が必要であり、現在は順番待ちの状態です。
3. 巨大なデータセットと巨大なネットワーク
前述した通り、GPT-3は約45TBの大規模なテキストデータを事前学習します。これは、GPT-3の前バージョンであるGPT-2の事前学習に使用されるテキストデータが40GBであることを考えると約1100倍以上になります。また、GPT-3では約1750億個のパラメータが存在しますが、これはGPT-2のパラメータが約15億個に対して約117倍以上になります。このように、GPT-3はGPT-2と比較して、いかに大きなデータセットを使用して大量のパラメータで事前学習しているかということが分かります。
4. GPT-3の特徴
それでは、この高い精度で文章生成を行うGPT-3の特筆すべき点を述べていきます。
第一に、GPT-3は事前学習したモデルに対して、ファインチューニングと呼ばれる既存のモデルを利用し、パラメータを微調整して追加学習を行い、新しいモデルを再構築することなく高い精度で予測を行うことができます。一般的に機械学習において、高い精度で予測する場合、事前に汎用的なデータで学習したモデルに対して、予測したい領域(ドメイン)のデータを追加学習することで、より高精度な予測を実現することが可能になります。例えば、金融機関に適用する場合は、事前に汎用的なデータセットを学習したモデルに対して金融機関で扱われるデータセットを追加で学習するイメージです。この点において、GPT-3はファインチューニングをすることなしに高精度な予測を行えるという所が優れた点の1つだと思います。
第二に、GPT-3は「Few Shot learning」※3と呼ばれる文章のお題や書き出しの一例、プログラミングコードの一部をタスクとして与えて実行するだけで、さまざまなケース(文章生成、穴埋め問題、機械翻訳、質問応答など)に応じたタスクを行うことができます。これはGPT-3が少ない事例で学習することを意味しています。また、「Few Shot learning」を設定することで、十分に学習されたモデルの精度を上回ったという事例も報告されています。具体的には、文章の最後の文字を当てる穴埋め問題のタスクや文章生成のタスク、知識を検証するタスクで高い精度結果を示しています。特に文章生成では、GPT-3は人間によって書かれたものと判断されるような自然な文章を作成することが可能です。海外ではGPT-3を利用して偽のブログを作成したところ、GPT-3が書いたものと気づいた人はほとんどいなかったという事例※4やGPT-3を使用して海外サイトの掲示板に投稿し続けたところ、約1週間誰も気づかずにGPT-3と会話をし続けたという事例が報告されています※5。偽ブログやフェイクニュースを簡単に作成できる点は、GPT-2の時から囁かれていたことですが、GPT-3ではより人間らしい文章を生成できるようになったということだと思います。
5. GPT-3の活用事例
GPT-3の活用事例はどのようなものがあるでしょうか。バックオフィス業務であれば、GPT-3を活用して提案書、稟議書、マニュアル、仕様書など業務で用いる各種ドキュメントを自動生成することが挙げられます。また、マニュアルなどドキュメントからFAQを自動的に生成し業務に活用することも考えられます。
さらに、GPT-3を質問応答に利用することも考えられます。実際、開発元のOpen AIが質問応答タスク向けに設計した訓練用の文章を学習した後、知識を必要とする常識問題を質問したところ、高い正答率を示した事例もあり、チャットボットへの活用やコールセンターにおけるオペレーター業務のメールの自動返信に活用できる可能性があります。会議の効率化という面では、議事録の内容を高精度で自然要約することにも使えると思います。
次に、営業業務では、GPT-3に商品の概要や写真を入力することで自動的にキャッチコピーを作成してくれるという使い方が考えられます。このように、GPT-3を活用して業務の効率化だけでなく高品質なサービスを提供できる未来が来るかもしれません。
6. GPT-3の課題
一方、GPT-3には現時点でいくつかの課題が報告されています。本コラムでは、その中から3つの課題を紹介します。
(1) 文章生成と文章の関係性に関する課題
GPT-3で生成する文章は過去の情報を元に単語を並べ、文法的にそれらしい文章を作っていることにすぎないため、長い文章を生成すると、同じ意味の単語を繰り返したり、結論が矛盾した文章を生成してしまうことがあります。また、人間のような常識を持っていないため、社会通念上ふさわしくない文章を作り出すこともあります。さらに、2文間の関係性を比較する能力に課題があります。具体的には、2文の中で使われている単語が同義であるかどうかを比較することや2文の中で一方が他方を暗に意味するかどうかを比較することが苦手です。これは、GPT-3が前の文章にある単語との関係性をパターン学習するというところに起因しており、後ろの単語から前の単語への関係性が問われる問題を解くことが難しいとされています。しかし、この2文間の関係性を理解する能力は自然言語処理分野では難しい課題のひとつと言われています。
(2) 推論における課題
GPT-3は物理現象の推論問題に弱いのではないかという報告があります。有名な事例として「冷蔵庫にチーズを入れて溶けるか?」という質問に対して、GPT-3は正しく回答することができません※6。さらに、人間であれば「意味が分からない」と答えるようなナンセンスな質問に上手く答えられません。例えば「太陽の目はいくつありますか?」という質問に対して、「太陽の目は1つです」と答えてしまいます※7。このように、人間が持つ常識や推論に基づく自然言語理解を実現しようとする試みは、それが実現可能であるか?ということも含めて大きな議論のひとつに挙げられます。また、推論や常識を求められるタスクに対して、テキストと知識ベースを融合させ、深層学習を行うことで人間並みの自然言語理解を獲得しようとするアプローチはトレンドのひとつになっています※8。
(3) 膨大な運用コストの課題
GPT-3の運用に掛かるコストの問題があります。具体的には、GPT-3の土台とのなるインフラ整備コストや膨大なパラメータを使用した事前学習などの運用コストがあり、それらを踏まえると気軽に実運用に踏み切れないのではないかという点が指摘されています。この課題に対しては、今後の事前学習のアルゴリズムの発展により、より小さなコストでGPT-3が利用できるようになる可能性もあります。
以上のように、GPT-3は現時点で課題はあるものの、今後の技術のブレイクスルーによっては、人間並みの自然言語理解に近づき自然言語処理分野に更なる可能性が広がることが期待されます。
7. 最後に
2021年はGPT-3をはじめとした自然言語処理分野の発展が期待されている年であり、今後もGPT-3の動向を見守っていき、機会があれば触れていきたいと思います。
※2021年1月にはGPT-3に近い性能の言語モデルをオープンソースで目指す「GPT-Neo」の記事※9が掲載されていました。
引用元
- ※1https://www.intellilink.co.jp/business/software/backofficenlp.aspx
- ※2https://linecorp.com/ja/pr/news/ja/2020/3508
- ※3https://arxiv.org/pdf/2005.14165.pdf
- ※4https://www.technologyreview.jp/s/216514/a-college-kids-fake-ai-generated-blog-fooled-tens-of-thousands-this-is-how-he-made-it/
- ※5https://gigazine.net/news/20201008-gpt-3-reddit/
- ※6https://xtech.nikkei.com/atcl/nxt/column/18/01428/092300002/
- ※7https://gigazine.net/news/20200726-giving-gpt-3-turing-test/
- ※8https://www.jst.go.jp/crds/pdf/2019/WR/CRDS-FY2019-WR-08.pdf
- ※9https://gigazine.net/news/20210119-gpt-neo/