
















自社のデータで生成AIを強化すべし:ファインチューニングしてビジネスに活用させたい基盤モデル(その2)
Microsoft、Google、MetaなどのBig Techが生成AIの開発をリードし、競争を激化させている現在、国家レベルでも本腰を入れて政策的に取り組もうという動きが加速しています。たとえば、英国では、2023年度春季予算案において、財務大臣が大規模言語モデルを含む基盤モデルにおける英国の主権能力を向上させるための新たな政府・産業タスクフォースを設立すると発表し、また、スナク首相が11月1日~2日にAIの安全性やリスク管理をテーマにした世界初のサミット "AI Safety Summit" を世界28カ国とEUの政府高官やAI企業の代表らを招集して主催するなど、AI推進とAI規制は英国政府の積極的な政策分野となっています。
英国の政府機関の一つであるCMA(Competition & Markets Authority:競争・市場庁)は、2023年9月18日に、"AI Foundation Models: Initial Report"(AI基盤モデル:イニシャル・レポート)[https://www.gov.uk/government/publications/ai-foundation-models-initial-report] というレポートを発表しています。CMAは、競争・消費者保護当局で、競争市場を促進し、不公正な行為を取り締まることで、英国の国民、企業、経済を支援しています。AI基盤モデルに関する競争と消費者保護の問題を検討するCMAによるこのレポートは、先に述べた政府の動きへの対応の一環を成すものであり、消費者、企業、国家に利益をもたらすAIのイノベーションを支援する上でCMAを含む規制当局がその役割を果たすための活動の一つです。
レポートでは、AIの利用から生じる可能性のある競争と消費者保護の問題を、三つのテーマ(①基盤モデルの開発における競争、②基盤モデルが他の市場の競争に与える影響、③消費者保護)に沿って考察しています。今回は、①について述べられている第3章を翻訳してご紹介したいと思います。なお、このCMAのレポートは、Open Government Licenceの条件の下で、ロゴ以外の情報をいかなる形式や媒体でも無料で自由に再利用することができます。以下の翻訳部分については、Open Government Licence v3.0に基づいてライセンスされた公共部門の情報が含まれています。(Contains public sector information licensed under the Open Government Licence v3.0.)
- ※文中の商品名、会社名、団体名は、一般に各社の商標または登録商標です。
3. 基盤モデル開発における競争と参入障壁
3.1 はじめに
本章では、基盤モデルの開発における競争と参入障壁について、基盤モデルの開発における主要なインプットと、それらが基盤モデルの導入においてどのように利用されているかを含めて調査します。(この章では、以下の図の赤で囲んだ部分に焦点を当てます。)
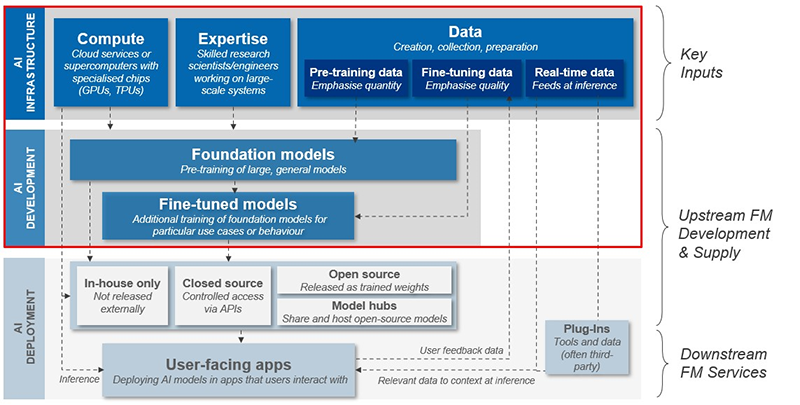
図:基盤モデル(FM)の開発とデプロイメント
これまでのテクノロジ主導の市場では、ネットワーク効果とスイッチング障壁が、統合、競争力の低下、「勝者総取り」の結果につながる可能性があることが示されています。この章では、特に市場開発の初期段階における基盤モデルに対するこれらの要因の適用可能性を評価します。また、市場の集中と競争力の低下の可能性を測るために、参入障壁の可能性と性質も評価します。
以下の各項目を順に説明します。
- ・データ要件
- ・計算資源
- ・技術的専門知識
- ・資金へのアクセス
- ・オープンソースモデル
- ・基盤モデルの将来的な発展を取り巻く不確実性、および競争への潜在的な影響
3.2 データ要件
基盤モデル開発の各段階において使用されるデータには様々な種類があり、それぞれ潜在的な参入障壁を検討する際の考慮事項が異なります。
3.2.1 事前学習
基盤モデルは広範で一般的なデータセットを用いて事前学習されます。事前学習データの量は、高性能なモデルを開発する上で非常に重要な要素であり、モデルのサイズと学習データの量の両方を均等にスケーリングすることで、モデルが最適に事前学習されることが経験的に示されています。(脚注:DeepMindの70BパラメータをもつChinchillaは、より多くの事前学習データを使用することで、4倍の280BパラメータをもつGopherよりも高い性能を達成しました。)そのため、これまでに開発されたモデルでは、事前学習データセットがますます大きくなる傾向にあります。しかし、より質の高いデータを使用することで、学習データ1トークンあたりのパフォーマンスが向上することもあります。
多くの関係者は、一般に入手可能なデータ(通常はWebからスクレイピングされたもの)が事前学習データセットの大部分を占めるのが一般的であると述べています。たとえば、LLaMA(Meta)、GPT-3(OpenAI)、Stable Diffusion(Stability AI)など、これまでに開発された多くの著名な基盤モデルは、すべて自由に利用できるソースからのデータで事前学習されています。
『今後数年間で、事前学習に利用可能な公開データが完全に利用され尽くしてしまう可能性があり、プロプライエタリ・データへの依存度が高まる可能性があります。』
Webからスクレイピングされたデータなど、一般に入手可能なデータは、当然ながら事前学習用として高品質ですが、プロプライエタリ・ソースからの独自データを事前学習用データセットに追加する傾向があります。これは、(さらなるパフォーマンス向上の源泉となりうる)高品質の言語データのストックが今後3年以内に完全に利用され尽くしてしまうのではないかという懸念によるものかもしれません。一部の関係者は、データの利用可能性には必ずしも厳しい制限があるわけではなく、一般に利用可能なソースから現在、事前学習データセットに追加されているデータは、繰り返し利用され、質が低下しているため、効率が著しく減少していると説明しています。
基盤モデル開発において、独自データの重要性が増す可能性があります。学術雑誌、画像リポジトリ、コーディング企業、コンテンツWebサイトなど、独自の情報源を用いて事前学習データを収集する組織の例があります。また、データプロバイダが価格を引き上げるという報告(Stack Overflow、Reddit、Twitter)や、MicrosoftがBing Search APIへのアクセスを減らし、価格を引き上げるという報告もありました。多額の資本を調達することができた様々な基盤モデル新興企業があることを考えると、特定の企業がサードパーティのデータ所有者から独自データを購入することに必ずしも優位性があるかどうかは明らかではありません。
『企業によっては、他のデジタル市場での活動から得たデータに関連する優位性を持っている場合があります。』
デジタル市場における他の活動から得られた広範なデータセットを所有することから得られると考えられる利点に関する懸念があります。
- (a)Webインデックス(脚注:Webクロールデータを分類・整理したコーパスのことで、検索エンジンがユーザのクエリに関連した結果を迅速に提供できるようにしたもの)の構築に使用されたWebクローリングデータは基盤モデルの学習にも使用できるため、Webインデックスへのアクセスは基盤モデルの事前学習に有利に働く可能性があります。また、多くの高性能モデルがWebインデックスにアクセスすることなく開発されていることを考えると、C4のようなWebクロールコーパスも、事前学習に同様の有用性があると強調する関係者もいます。しかし、検索エンジンのプロバイダは、より質の高いWebクロールデータを入手する上で有利であるという意見も聞かれました:
- (i)検索エンジンのクローラは、検索結果ページに表示されることを望むWebサイト所有者によって、レートを制限(脚注:Webページを過度に使用または乱用しているとみなされるユーザ、ボット、またはアプリケーションの活動をブロックまたは制限すること)されたり、ブロックされたりする可能性が低い。
- (ii)Webクロールデータには本来、無意味な情報や役に立たないノイズ情報が含まれており、Webインデックスは検索エンジンに「ノイズの中からシグナルを見つける」能力を提供します。Webインデックスに匹敵するようにWebクロールデータを前処理するコストは、ある関係者の試算によると数千万ドルのオーダーになるといいます。さらに、別の関係者からは、独自データセットの規模に比べるとWeb上のデータ量の方が膨大なことから、Webスクロールデータをフィルタリングして高品質なデータを見つけることは、独自ソースからのデータを追加することよりも重要である可能性があるといいます。
- (b)プラットフォームのインタラクションや、写真、ビデオ、デジタルブック、オーディオブック、音楽、ポッドキャストのリポジトリなど、一部の企業が所有していたり、アクセスしやすかったりするデータは、事前学習に役立つ可能性があります。特にYouTubeは、字幕のテキストデータや動画間のリンク情報などのメタデータが付随した「会話スタイル」の動画データのリポジトリとして、特に価値のあるソースになる可能性があると推測されています。しかし、この種のデータの有用性は、IPとプライバシー保護に依存するかもしれません。垂直統合された企業は、ソーシャルメディア上のユーザとのインタラクションから得られるデータなど、独自データに容易にアクセスできるかもしれません。さらに、メディアや出版社、デジタルアーカイブの所有者など、他の情報源から購入できる独自データも、事前学習に同様の価値を持つかもしれません。
3.2.2 ファインチューニング
ファインチューニングにはアライメントとドメイン/タスク固有という主に二つのタイプがあります。ファインチューニングに必要なデータ量は、通常、事前学習よりも大幅に少なく、その品質がより重視されます。ファインチューニングのためのデータの質を決定する特に重要な要因は、対象となるテーマやユースケースの専門的な「ノウハウ」をどれだけ反映しているかになります。
3.2.3 アライメント
アライメント(脚注:人間のユーザが持つ期待や嗜好に沿うように、モデルの振る舞いを改善するファインチューニングのプロセス)に使用されるデータは専有される傾向があり、多くの場合、人手によって生成されたもの(特にトレーニングの目的で人手によって作成されたもの)、またはアノテーションされたもの(学習プロセスをガイドするためにラベルや追加情報が人手で追加されたもの)です。これは、従業員を使って会話例を生成したり、RLHF(Reinforcement Learning from Human Feedback)(脚注:人間のフィードバックからの強化学習のことで、悪い行動を罰する報酬関数でモデルをトレーニングする。これは、良い行動と悪い行動を区別するための人間のフィードバックに依存している。)の目的でモデル出力を評価したり、ユーザからのフィードバックデータを使用したりすることで、社内でインハウスに達成することができます。
また、RLHFを含むアライメント目的のために、高品質のラベル付きデータを提供する専門データプロバイダの市場も出現しています。また、アライメントのためのデータをクラウドソーシングし、オープンソースとして共有する取り組みも行われています。たとえば、Open Assistant Conversationsと名付けられた、人間が生成し注釈を付けたアシスタントスタイルの会話コーパスなどがあります。しかし、ある関係者からは、一般的に、こうした取り組みは、クローズドソースによるアライメント用データの提供に遅れをとっているのではないかという声が聞かれました。
『アライメントデータの入手の難しさについては、意見が分かれるところです。』
多くの関係者は、データを効果的にアノテーションするために必要な経験、技能、労力のため、アライメントデータはコストがかかり、入手が困難であると考えています。また、アライメントデータの入手の複雑さとコストは、基盤モデルが意図する目的の難易度によっても増加する可能性があります。たとえば、医療目的で使用される基盤モデルのアライメントデータは、高度に熟練した専門家のインプットを必要とするかもしれません。しかし、クラウドソーシングデータは、事前学習データよりも著作権やプライバシーに関する問題が少なく、また、専門プロバイダからアライメントデータを購入するコスト(数千万米ドルの範囲と推定される)は、ベンチャーキャピタルの支援を受けた新興企業にとって法外なコストではないかもしれないという意見もありました。
ユーザのフィードバックデータもRLHFを通じてモデルの挙動を改善するために使用できることを考えると、大量のフィードバックを提供できる確立されたユーザベースを持つことにはメリットがあるかもしれません。しかし、現在のところ、このデータは自動的にモデルに「フィードバック」されるのではなく、品質と安全性を確保するために厳格な手作業によるレビューが必要であることを考えると、ユーザからのフィードバックが多いプロバイダがどの程度有利になるかは明らかではありません。このことは、現在のところ、モデルが散発的に更新されることを意味し、利用できるユーザデータの量に現実的なスケーリングの限界が生じる可能性があります。一方、大規模なユーザベースを持つある企業は、ユーザフィードバックデータの価値が低下するような事態には、これまで遭遇していないと語っています。
『アライメントデータを取得するためのオープンソースの代替手段がいくつか登場しています。』
モデルの挙動を改善するためにユーザフィードバックデータを使用することに代わる新たな方法として、オンラインで共有されている、人間と既存モデルとの会話を利用する方法があります。たとえば、注目すべきオープンソースモデルの一つであるVicuna-13Bは、Metaの学習済みLLaMAモデルと、ShareGPTというWebサイトから収集されたChatGPTによるユーザ共有の会話データセットを使用してファインチューニングされました。研究者は、このモデルはOpenAIのChatGPTとGoogleのBardの90%以上の品質を達成したと述べていますが、性能を評価するための普遍的に採用されたベンチマークは存在していません。このファインチューニング手法の長期的な実行可能性は、主要な基盤モデルサービスの利用規約内の制限によって影響を受けます。すなわち、競合する基盤モデルや技術を開発するための利用は制限される可能性があるからです。たとえば、GoogleとOpenAIの利用規約には、現在そのような制限が設けられています。
また、アライメントのファインチューニングのためのデータセットを作成し、開発者に公開し、共有しようとする取り組みもあります。独自データセットと比較した場合の有効性は今のところ不明ですが、オープンソースモデルの研究開発にとって、これらのデータセットは重要であると考えられます。
3.2.4 ドメインまたはタスク固有のファインチューニング
ドメインやタスクに特化したファインチューニングのプロセスでは、事前学習されたモデルを、より小規模で専門特化したデータセットで再度学習させます。ドメインやタスクに特化したファインチューニングには膨大な可能性があり、利用できるデータソースも多様なことから、多くの企業が専門特化したモデルのファインチューニングに利用価値がありそうなデータを所有しているか、利用できる可能性があります。
ドメイン固有のファインチューニングデータが、特定分野における専門特化モデルの開発およびデプロイメントの参入障壁となる可能性は、その分野の力学にも左右されます。特に、特定のセクターにおける既存のデータ分布は、業界のコンペティタの競争力に影響を及ぼす可能性があります。
3.2.5 合成データ
モデルの事前学習、ファインチューニング、テストに使用するために、合成データと呼ばれるデータを人工的に生成する方法があります。たとえば、シミュレーションのデータを使用する方法、既存のAIモデルを使用して新しいデータセットを生成する方法、実際のデータを人工的に拡張する方法などがあります。(脚注:オープンソースのチャットボットVicunaは、ユーザがChatGPTと交わした会話をもとにトレーニングされました。)合成データは、人間が生成した大規模なデータよりも取得コストが低く、意図的にラベル付けされているため、多くの利点があります。また、モデルの学習に機密データや著作権保護されたデータを使用する必要もありません。
基盤モデルが作成した合成データを使ってモデルを学習させた二つの研究により、「モデル崩壊」と呼ばれるリスクが明らかになりました。これらの研究によると、既存のモデルを用いて生成された合成データには、元々のトレーニングデータからの学習が失われるため、不可逆的なプロセスで将来のモデルを汚染する欠陥が含まれる可能性があります。このリスクは、基盤モデルで生成されたコンテンツがWebに溢れ始め、将来クロールされるデータの一部を形成するようになるにつれ、基盤モデル開発者にとってより大きな懸念となる可能性があります。この研究はまだ始まったばかりであるため、このようなリスクが実際に発生するかどうか、またそのリスクを軽減するためにどのようなことができるかは、まだ明らかではありません。しかし、市場が独自データを使用する方向に急速に移行した場合、合成データは基盤モデル開発者にとって直ちに代替となるデータソースとはならないかもしれません。
3.3 計算資源
基盤モデルは、多くの場合、数百のアクセラレータチップから構成される大規模な分散コンピューティングシステムを必要とします。これらは入手するのに高価であり、利用可能なものも限られ、技術的な制約もあります。たとえば:
- (a)少数の企業が必要なチップを生産しているため、AIツールを開発およびデプロイメントする新興企業やその他の企業に依存関係が生じています。たとえば、NVIDIAは現在AIアクセラレータチップで市場をリードしており、Googleは独自のTPUをGCPでのみ提供しています。機械学習用のGPUやチップを製造する他の企業は、競争に苦戦していると言われています。
- (b)知識要件、専門知識、原材料、高度に専門化された製造工程、多額の固定費などの要因により、初期製造コストが高い。これは、半導体製造のマーケットリーダが規模の経済の恩恵を受けられることを意味し、新規参入企業がこれに対抗するのは難しいかもしれません。
- (c)現在、AI用のサーバGPUは不足しています。
- (d)最新のGPUアーキテクチャはTransformerのボトルネックに遭遇しており、モデル内の特定の計算を効率的に処理するのに苦労しています。これは、開発されるモデルの規模が拡大するにつれて悪化しています。
- (e)大手テクノロジ企業も、独自のAIアクセラレータチップを開発するさまざまな段階にあります。たとえば、Amazon AWS Trainium、Meta Training and Inference Accelerator、Microsoft "Athena"、IBM Telumなどです。
3.3.1 事前学習
基盤モデルが効果的な事前学習を行うには、かなりの計算能力が必要です。これは近年、平均して増加しています。事前学習に必要な計算量は、モデルのサイズと種類によって異なります。たとえば、MetaのLLaMAモデル(パラメータ数65B)の計算コストは約400万ドルと推定され、MicrosoftがNVIDIA社と提携して作成した比較的大規模なMegatron-Turing NLG(パラメータ数530B)の計算コストは1億ドルと推定されます。OpenAIは、GPT-4の開発に1億ドル以上を費やしたと言われています。そのため、必要とされる計算インフラが、下流の企業が独自の基盤モデルを開発しないことを選択する理由の一つになっています。
モデルが大きくなるにつれて、学習させるための演算回数はべき乗則で増加します。これは、モデルの大きさと学習させるための計算コストとの間にトレードオフが生じることを意味します。推論に必要な計算量も同様にスケールします。さらに、最適な学習データサイズは、モデルサイズとともにスケールします。一握りの大手テクノロジ企業は、AIアクセラレータを含む膨大な計算資源を保有しており、基盤モデルの事前学習をインハウスで迅速かつ効率的に行うことができます。一部の例外を除き、ほとんどの基盤モデル開発者は、多額の初期費用がかかるため、事前学習に必要な計算インフラを構築しないといいます。しかし、そうすることで、大手のテクノロジ企業や基盤モデル開発者にとっては、長期的にはコスト削減となる可能性があります。
データセンタを保有していない基盤モデル開発者は、一般的にクラウドサービスプロバイダ(CSP)を活用します。基盤モデル開発者が利用できる主な選択肢は以下の通りです:
- (a)CSPから商用オンデマンド料金で計算資源を購入します。これはコストが高くつく可能性があり、基盤モデルの学習や推論に必要な計算が利用できる保証もありません。
- (b)CSPのリソースを、オンデマンド価格よりも割安な価格で、初期費用や継続費用を伴う契約(通常1年または3年)を締結します。これにより、リソースの利用を保証することができますが、リードタイムが長くなる(6~9ヶ月)可能性があります。
- (c)CSPと商業的パートナーシップを結びます。これには、CSPが独自のサービスにそのモデルを使用できるようにする(脚注:たとえば、Microsoftは、OpenAIのGPT-4をBingに統合しました。)とか、推論のためにクラウドサービスでその基盤モデルを利用できるようにする(脚注:たとえば、AWSは、Stability AIのStable DiffusionモデルをSagemaker上にデプロイしました。)という条件が含まれる場合があります。
CSPとのパートナーシップを確保できた企業はごく少数です。CSPは、パートナーシップの締結を優先し、希少な計算資源や投資を、より確立されたパートナーや、そうすることに正当な戦略的根拠があるパートナーに割り当てる可能性があります。パートナーシップを結べば、より優先度の高い計算資源へのアクセスと安価な料金の両方が得られるため、(CSPから計算資源を購入したり、購入契約を結んだりするよりも)パートナーシップを確保できる者はそうするでしょう。基盤モデルの開発には計算資源パートナーシップが必要です、あるいは「決定的に重要」であるとさえ言う人もいます。アクセラレーション機能を持つ主なCSPは、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Platform(GCP)の3社です。基盤モデル開発者の中には、より小規模なプロバイダや複数のプロバイダとの関係を維持している者もいますが、通常、パートナーシップはこれら3社のうちの1社を通じて結ばれます。
商業的パートナーシップには他にも利点があります。CSPは、基盤モデルを支える技術についてより多くを学び、それに応じてハードウェアとソフトウェアを改善することができます。新しいアクセラレータチップへのアクセスも、CSPと開発者の双方に有益です。CSPは、潜在的な供給不足を緩和するだけでなく、最新のハードウェアを使用することで提供するサービスを向上させることができ、一方、開発者は、より革新的なアプリケーションを作成するのに役立つ最先端技術にアクセスすることができます。最近の業界の動きとしては、Stability AIが次世代モデルのトレーニングにAWS Trainiumチップを使用したり、Midjourneyが最新モデルをGoogleのTPUv4で学習させています。
一部の関係者は、コンピュート契約やパートナーシップの割り当てに関して懸念を表明しており、既存のビジネス関係や長期的なコミットメントの可能性がある事業者に偏る可能性を示唆しています。一部の新興企業は、クラウド・コンピューティングに支払うクレジットという形でCSPから投資を受けることができるが、大企業ほど「一番乗り」しやすく、より大規模な計算クラスタを保有する契約を結ぶ可能性が高いという懸念を耳にしました。このため、新興企業のような小規模な組織にとっては、基盤モデルの開発およびデプロイメントに必要な計算資源へのアクセスが困難になる可能性があります。
さらに、英国を拠点とするCSPクラスタは、最先端のアクセラレータの採用と利用可能性において他地域に遅れをとっています。3大CSPのいずれも英国ではNVIDIA A100を利用できず、GCPは米国でのみTPUv4クラスタを提供しています。このことは、機密データや個人データを扱う必要がある基盤モデルの開発に携わる英国の開発者にとって、国際的なデータストアの制約を受ける可能性があり、問題となります。
CSP以外の計算資源を借りるという選択肢もあります。たとえば、Hugging Faceは基盤モデルBLOOMの開発において、フランスの公有スーパーコンピュータであるJean Zay(ジャン・ゼイ)を使用しました。この方法には、エネルギーコストを完全に把握できるなどの利点もありますが、プロジェクトごとに研究助成金を必要とするため、民間の計算資源のように柔軟に利用することはできません。Hugging Faceは、CSPとの関係も維持しているため、この方法が継続的な商業利用として実行可能であるとは考えにくいと言えます。また、学術界では、分散型計算資源(家庭用コンピュータなどのアイドル状態のデバイスをモデルの学習に使用)の利用もありますが、これも現在のところ商業的には実行可能ではありません。
3.3.2 ファインチューニング
基盤モデルのファインチューニングに必要な計算量は事前学習に比べて桁違いに少ないため、より簡単に利用できます。基盤モデルのファインチューニングは、たとえばGPU一つやCPU一つなど、グレードの低いハードウェアの少ない要素で行うことができます。必要なチップの数が少なかったり、そんなに高度でなかったりするため、ファインチューニングに使用されるハードウェアはより安価で、より広く利用できます。開発のファインチューニング段階に限ると、計算資源へのアクセスの問題を懸念する声は聞いていません。
また、ファインチューニングに必要な計算量も減少し続ける可能性があります。(EleutherAIのGPT-JやMetaのLLaMAモデルのような)オープンソースのモデルの上に、低ランク適応(LoRA:Low-Rank Adaption)のような新しい技術によって構築されたファインチューニングにおける最近の技術革新は、わずかなコストと時間でモデルのファインチューニングを可能にします。これらの例としては、Vicuna-13B(脚注:ShareGPTから収集されたユーザ共有の会話データでLLaMA事前学習モデルをファインチューニングすることによって訓練されたオープンソースのチャットボット)、Alpaca、Koalaがあり、ファインチューニングのコストはそれぞれ300ドル、600ドル、100ドルです。しかし、このプロセスは、事前学習されたモデルを利用し、その上で反復することに依存します。この方法で開発された新しいモデルが競争力を維持できるかどうかは、ファインチューニングのために自由にアクセスできる高性能な事前学習済みモデルがリリースされ続けるかどうかにかかっています。
3.3.3 推論
モデルが推論を行うときにも計算が必要になります。1回の推論に必要な計算量はごくわずかなため、小規模な推論であれば、アクセスしやすく、持続可能です。しかし、モデルのサイズやユーザ数が増加するにつれて、推論に必要な計算量も増加します。そのため、需要を管理し、推論にかかる時間(レイテンシー)を短縮するために、アクセラレータの大規模なクラスタが必要になることもあります。したがって、他のデジタル市場とは異なり、基盤モデルのデプロイメントには無視できない限界コストがかかります。
基盤モデル開発者は、自らモデルをデプロイすることができます。そのためには、推論を容易にするためのインフラを開発・維持し、計算コストを支払う必要があります。これはAPIを通じて行うことができ、ユーザはプログラムでモデルに問い合わせを行い、その応答として推論結果を受け取ることができます。基盤モデルAPIの例としては、OpenAIやAnthropicが提供しているものがあります。
あるいは、いくつかのクラウドサービスプロバイダは、自社のプラットフォームやAPIを通じて基盤モデルの推論(およびファインチューニング)を提供することができます。たとえば、Amazon Bedrock APIは、AI21、Anthropic、Stability AIのモデルにアクセスできます。AzureはOpenAIのモデルで同様のサービスを提供しています。Amazonはまた、APIよりも詳細な開発が可能なプラットフォームであるSageMakerを通じて基盤モデルを提供しています。この場合、基盤モデルのデプロイメントコストを管理するのはCSPであることが多いです。
これらの方法やその他の方法で推論用の計算資源にアクセスできることについての具体的な懸念は聞いていませんが、この市場の特徴は、推論コストが低い可能性が高い垂直統合企業や垂直関係を持つ企業に利益をもたらす可能性があります。
3.4 技術的専門知識
基盤モデルは複雑で、開発と学習には高度な技術的専門知識が必要とされます。必要とされる技術的専門知識には、機械学習に関する最先端の知識だけでなく、データ工学や高性能コンピューティングに関する実践的な専門知識も含まれます。基盤モデル開発者の求人広告の多くには、データサイエンティスト、機械学習(ML)エンジニア、自然言語処理/コンピュータービジョンの専門家が含まれています。これらもまた高度なスキルを必要とし、通常、修士/博士号が必要とされます。
10年前、先進的なMLモデルのほとんどは学術研究から生まれたものでした。その後、このようなモデルの開発は産業界に移行しましたが、これはより多くのリソースと人材を利用できるようになったためです。たとえば、GoogleはTransformerモデルに関する最初の論文を発表し、MicrosoftはLoRAの論文を発表しています。しかし、公的資金、学術界、非営利企業によって、事前学習とファインチューニングの両段階で開発されたモデルもあります。(脚注:たとえば、Falconはアラブ首長国連邦の技術革新研究所によって、BLOOMは公有のスーパーコンピュータJean Zayの資金援助を受けて多くの学術共同研究者とともに、また、Alpacaはスタンフォード大学基盤モデル研究センタによって、RedPajamaはTogetherによって開発されました。)
データサイエンティストやML/AI研究者の人材は、学術界から産業界へとシフトしています。たとえば、2011年にはAIに関するPhDの新規取得者の41%が産業界に雇用されていたのに対し、2021年には65%が産業界に雇用されています。これは、この分野での仕事が新しいモデルの開発・研究に対して高いプレミアムがつくためで、学術界では太刀打ちできないと言われたからかもしれません。
基盤モデルは、大規模にデプロイするためのエンジニアリングの一般的なスキルと、事前学習に必要な専門的なスキルを必要とします。後者は、このセクターの既存のエンジニアのみが、産業界に限られた必要なインフラにアクセスできるため、不足しています。一部の企業は、AIの仕事ができるように経験豊富なソフトウェア・エンジニアを育成しています。つまり、大企業は、関連スキルを持つ人材を高給で雇用するか、関連スキルを持つ既存のソフトウェア・エンジニアを育成するために投資することで、このような人材をより容易に獲得できる可能性があります。
ヒアリングにおいて、従業員に課された競業避止条項や公表制限について懸念を示した利害関係者はいませんでした。
3.5 資金へのアクセス
基盤モデルの学習とデプロイメントには、特に事前学習に多額の費用がかかります。追加的な資金を確保することなく、独自に基盤モデルの学習を行えるリソースを持つ組織は限られています。
我々が見たエビデンスによると、現在、小規模なプレーヤーは投資家から資金を確保することができます。このため、近年、基盤モデルの数は顕著に増加しており、2018年以降、推定160の基盤モデルが存在しています。Adept、Cohere、Stability AIなどの企業は、基盤モデルを開発・デプロイするための資金調達に成功しています。GoogleやMicrosoftも、Anthropic(脚注:Googleから総額4.5億ドルの資金提供を受けたと報じられている。)やOpenAI(脚注:MicrosoftはOpenAIに3回のラウンドで総額130億ドルを投資している。)など、さまざまな基盤モデル開発企業に資金を提供しています。フランスの新興企業Mistral AIは設立からわずか4週間で1億1300万ドルのシード資金を確保することができました。
このような資金調達がこの分野の小規模なプレーヤーの成長に与える長期的な影響はまだ不透明です。とはいえ、こうした資金調達が、こうしたプレーヤーがこの分野で存在感を示す上で極めて重要な役割を果たしていることは明らかです。
3.6 オープンソースモデル
3.6.1 事前学習
多くの企業は、最も高いパフォーマンスを持つ事前学習済み基盤モデルをクローズドソースとし、モデルの重み(モデルの内部的な「知識」)を企業秘密とし、APIまたはユーザ向けアプリケーションを通じてアクセスを提供しています。また、多くの事前学習済みモデルがオープンソースとして公開されています。
オープンソースモデルは通常、クローズドソースモデルよりも透明性が高く、アクセスしやすいです。これは、オープンソースモデルのコードとパラメータが公開されているため、研究者や開発者がモデルを理解し、改良することが容易になっているためです。一方、クローズドソースモデルは、企業がモデルの全詳細や学習方法を公開しないことを選択する場合があるため、透明性が低いと言えます。
オープンソースモデルの透明性が高いことには、いくつかの利点があります。利用者は、モデルがどのように機能するかをよりよく理解することができ、モデルの精度と信頼性を評価するのに役立ちます。また、利用者はオープンソースモデルのコードを修正することで、モデルの改善や新機能の追加を行うことができます。さらに、ユーザはバグフィックスや新機能を提出することで、オープンソースモデルの開発に貢献することができます。
オープンソースモデルの開発は、クラウドソース化することもできます。ユーザは、モデルを改善するために、オリジナルの開発者に提案することができます。また、モデルをフォークして独自の改良を加える(脚注:モデルがフォークされるということは、通常、誰かが既存のモデルを取り出して、その別バージョンを作成することを意味します。フォークされたモデルは、元のモデルに影響を与えることなく、修正、ファインチューニング、さらなる開発を行うことができる独立した存在となります。)ことで、元のモデルに影響を与えることなく、基盤モデルの利用可能性と多様性を高めることもできます。
オープンソースモデルにはリスクもあります。オープンソースモデルには非中央集権的な性質があり、貢献者は多様なバックグラウンドを持ち、専門知識のレベルも様々です。そのため、オープンソース・コミュニティ全体にわたって一貫したガバナンス方針を確立し、実施することが困難になる可能性があります。また、有害な理由で利用しようとする悪質な行為者による利用を監視するという課題もあります。
一部の関係者や報告書によると、オープンソースの事前学習済みモデルは一般に小さく、最もパフォーマンスの高いクローズドソースモデルに比べてパフォーマンスが劣ります。これは、クローズドソースモデルが通常、より強力なハードウェアを使用して大規模なデータセットでトレーニングされ、パフォーマンスが向上するように最適化されているためと考えられます。しかし、オープンソースとクローズドソースのモデル間の能力格差の程度とその意味するところは、まだ不確実であり、そのような格差が時間の経過とともにどの程度維持されるかはまだわかりません。
3.6.2 ファインチューニング
オープンソースモデルのファインチューニングの開発により、その機能は大幅に進歩しました。たとえば、一部のファインチューニングされたオープンソースLLMは、ChatGPTなどのファインチューニングされたクローズドソースモデルと同等のパフォーマンスに達すると主張しています。たとえば、2023年3月には、130億パラメータのVicuna LLMモデルがChatGPTの品質の90%を実現すると主張しました。
Hugging Faceによって発行されたLLMリーダーボードも、オープンソースモデルによる進歩を示しており、最高パフォーマンスのモデルはますます優れたパフォーマンス・メトリクスを達成しています。ただし、オープンソースモデルとクローズドソースモデルの両方のパフォーマンスを評価するために使用される一部のパフォーマンス指標の信頼性には疑問があります。それらは非常に主観的であり、開発者はモデルにとって最も有利な指標を選択する傾向があるためです。
オープンソースの事前学習済みモデルへのアクセスにより、研究者や開発者は、パラメータ効率の良いファインチューニング(PEFT)や低ランク適応(LoRA)などの多くのファインチューニング手法を使用してきました。これらにより、事前学習済みモデルのファインチューニングに必要なリソースが削減され、コスト効率の高い方法で迅速な反復が可能になります。
3.7 不確実性
私たちの分析では、基盤モデル開発者は効果的に競争するために、データ、計算能力、技術的専門知識、資金へのアクセスを必要としていることに加えて、基盤モデルの将来の開発に関する多くの重要な不確実性も特定しました。これらの不確実性は、競争や消費者にとって前向きな、あるいは、より懸念すべき結果をもたらす可能性があります:
- ・競争するには独自データへのアクセスが必要になるのでしょうか?
- ・モデルはさらに大型化するのでしょうか?
- ・基盤モデルは高度に一般化されるのでしょうか?
- ・競争するには最先端のパフォーマンスが必要でしょうか?
- ・大手テクノロジ企業や先行者が有利になるのでしょうか?
- ・オープンソースモデルは今後も市場の重要な部分を占めるのでしょうか?
基盤モデルの開発はまだ初期段階にありますが、これらのモデルは将来的にさまざまな方法で進化する可能性があります。たとえば、基盤モデル開発は少数の大企業、または多数の中小企業が中心となる可能性があります。
複数の独立した企業が主要な基盤モデルを生み出すために互いに競争し、革新的な企業が参入、拡大、効果的に競争するために必要なインプットにアクセスできれば、消費者、企業、そして経済全体にとってプラスの市場結果が生まれるでしょう。そのシナリオでは、企業は、他の企業が既存の基盤モデル機能を引き続き構築できるように、オープンソースとクローズドソースの両方で基盤モデルを供給するなど、さまざまなビジネスモデルや収益化の形式を実験できるようになります。
しかし、インプットへのアクセスが制限され、少数の企業だけが主要なモデルを作成および維持できる場合、懸念すべき市場結果が生じる可能性があります。その結果、残った企業は、クローズドソースベースでのみモデルを提供し、不当な価格と条件へのインセンティブをもつ強力な立場を築くことになるでしょう。
次のセクションでは、主要な不確実性を概説し、それらが競争と市場の結果に与える潜在的な影響を、プラス面とマイナス面の両方で分析します。また、ここでは説明されていませんが、競争や消費者に影響を与える可能性のあるその他の不確実性も存在する可能性があります。
3.7.1 競争するには独自データへのアクセスが必要になるでしょうか?
3.2.1で強調したように、基盤モデル開発のための公的に利用可能な高品質データのストックは、モデルのパフォーマンスを向上させるために、間もなく完全に活用され尽くされる可能性があります。これが本当であれば、別の手段を通じてパフォーマンスの向上を達成する必要がある可能性がありますが、これがどのような結果をもたらすかは現時点では不明です。
効率やパフォーマンスの向上を見つけるための新しい学習方法とモデルアーキテクチャを特定することは、現在、基盤モデル開発者にとって重要な研究分野です。ただし、これらの革新がどの程度、どのくらいの速さで起こるかは明らかではありません。より少ないリソースでパフォーマンスの向上を達成するための新しい方法が出現し、短期的にさまざまな競合他社が利用できるようになった場合、大量の高品質の学習データにアクセスするメリットは少なくなる可能性があります。ただし、学習データの量を増やし続けることで達成されるパフォーマンスの向上に効率の革新が追いつかない場合、アクセスがさらに有利になる可能性があります。
ますます大量の学習データにアクセスするための最も効果的な方法が何かについても不確実性があります。3.2.1で説明したように、Webインデックスにアクセスすると、基盤モデル開発者がWebクロールから高品質のデータを取得または識別する能力が向上する可能性があります。したがって、この状況で効果的に競争するには、Webインデックスへのアクセスが必要になる可能性があります。
しかし、最も競争力のあるモデルを開発するためにプロプライエタリのソースから大量の独自データを取得することが(Webクローリングから入手できるデータに加えて)必要になった場合、独自データへのアクセスが競争に影響を与える重要な要素になる可能性があります。これにより、一方では、さまざまな基盤モデル開発者に公正かつ平等な条件でデータを提供するデータプロバイダのダイナミックな市場が刺激される可能性があります。しかしその一方で、学習に最も有用な独自データのソースに(たとえば他のデジタル市場での活動などにより)一部の既存の基盤モデル開発者のみがアクセスできる場合、競争が阻害される可能性があります。
この不確実性に影響を与える可能性のある要因は、Webクロールされた学習データの使用に関連する著作権法の施行の可能性です。たとえば、これは、GettyがStability AIに対して起こした訴訟や、作家のMona AwadとPaul TremblayがOpenAIに対して起こした訴訟など、進行中のさまざまな法的訴訟の対象となっています。このような訴訟で裁判所が原告に有利な判決を下した場合、学習に利用できるデータの量が減少したり、その価格が上昇したりする可能性があり、その結果、独自のデータを所有することの潜在的な利点が増幅される可能性があります。
3.7.2 モデルはさらに大型化するのでしょうか?
基盤モデルは大型化する傾向にあります。最初にリリースされたTransformerモデルの一つは、2018年に3億5,400万のパラメータを備えたBERTでした。それ以来、PaLM、GPT-3、およびMegatron-Turing NLGが数千億のパラメータを使用して開発されました。上位のオープンソースLLMでさえ、少なくとも数百億パラメータを持っています。この傾向の背後にある主な理由は、「スケーリング則」として知られる、規模(モデルサイズ、学習データ量、計算量および学習時間)とパフォーマンスの間に観察された正の関係です。ただし、モデルサイズと、学習と推論のための計算要件のコストとの間のトレードオフは増加しています。
競争力を維持するために基盤モデルが拡大し続ける場合、これらのモデルの開発は、必要な計算インフラにすでにアクセスできる企業に限定される可能性があります。また、上で説明したように、学習には独自の不確実性があるため、ますます大規模なデータセットが必要になります。この軍拡競争のシナリオは、計算資源とデータの投入により、多くの参入者にとって参入や拡張に対する高い障壁を生み出し、市場が集中する可能性があります。
事前学習済みモデルの開発に集中しても、基盤モデルのファインチューニングのための多様な市場が必ずしも排除されるわけではありません。ファインチューニングを行うための計算要件が低い場合、開発者は「既製」の基盤モデルを利用して、独自のニーズまたはクライアントのニーズに合わせてファインチューニングすることが奨励される可能性があります。
モデルサイズの増加によってどの程度のパフォーマンスが得られるかについては、これを評価するための標準化されたパフォーマンス指標が不足していることもあり、不確実性があります。また、モデルがしきい値を超えるとパフォーマンスが低下する可能性がある「逆スケーリング」のリスクもあります。(脚注:最近の研究で、モデルの規模が大きくなると、より不正確になる可能性があることがわかりました。その説明の一つは、大規模なモデルはより強い事前分布を持つ傾向があり、学習データから学習されたフレーズを記憶し、プロンプトのコンテキストよりも優先して選択されるというものです。特に、与えられたコンテキストが学習データと異なる場合、このような先入観がモデルを不正確な予測に導くことがあります。)
逆に、モデルが小さくなる可能性もあります。小規模な基盤モデルを開発するためのいくつかのインセンティブは次のとおりです:
- (a)モデルが小さいほど、必要な計算量とデータが少なくなるため、事前学習にかかる初期費用が少なくなります。
- (b)モデルのサイズに応じて推論コストが下がるため、長期的にはより持続可能です。
- (c)モデルが成長するにつれてパフォーマンスが頭打ちになり始める可能性があるため、開発者はより効率的なモデルを構築して収益性を高めることができます。
モデルをより小さく、より効率的にするためのさまざまな方法があります。たとえば、スパース化(脚注:ゼロ値を多く含む疎な行列をモデルに使用する方法です。これにより、精度を損なうことなく、モデルを学習するためのストレージと計算リソースを削減することができます。)と量子化(脚注:モデルパラメータに8ビット浮動小数点のような、より小さく精度の低い数値フォーマットを使用する。これにより、トレーニングの計算コストを削減しつつ、パフォーマンスを維持することができる。)により、計算要件が軽減されます。モデルアーキテクチャと学習技術における他の潜在的な革新は、同様のパフォーマンスを維持しながら、より効率的なスケーリング則につながる可能性があります。モデルは事前学習後に圧縮することもできます。これにより、学習の計算コストは削減されませんが、デプロイメントコストが安くなります。そして、推論コストが削減され、推論がエンドユーザのデバイスで計算される場合はゼロになる可能性があるため、プロバイダにとって利点が得られます。この圧縮方法には、枝刈り(学習後のスパース化の一種)と量子化が含まれます。あるいは、知識蒸留は、学習済みの大規模なモデル(教師)を使用して、それをできるだけ忠実に模倣する小さなモデル(生徒)を訓練する方法です。たとえば、Googleは、PaLMの蒸留されたモデルを使用してスマートフォン上で動作させたという報告があります。
パフォーマンスを向上させるために基盤モデルがますます大規模になり続ける場合、参入障壁が高まり、基盤モデル開発者間の競争が減少する可能性があります。これは、ユーザが最高のパフォーマンスのモデルを必要とする場合に発生する可能性があります(「競争するには最先端のパフォーマンスが必要でしょうか?」を参照)。それに到達するための主な手段は、モデルのサイズを増やすことです。開発コストの増加と計算リソースが引き続き制限される可能性が組み合わさることにより、参入障壁がさらに高くなる可能性があります。ただし、モデルのサイズを縮小し、パフォーマンスを犠牲にすることなくトレーニング効率を高めるなど、基盤モデル開発における可能な革新によって障壁が軽減される可能性があります。
3.7.3 基盤モデルは高度に一般化されるのでしょうか?
基盤モデルは汎用テクノロジとして、多くの製品やサービスに導入できます。たとえば、基盤モデルを使用してチャットボットを強化したり、テキストを生成したり、言語を翻訳したりできます。モデルは、広範なタスクで非常に効果的になるために大幅なカスタマイズが必要なくなるところまで発展する可能性があります。これにより、ドメイン固有のファインチューニングの必要性が減り、プロンプトエンジニアリング(脚注:AIモデルが与えられた入力に基づいて応答を生成できるように、効果的なプロンプトを作成するプロセス。プロンプトは基本的に、モデルに何をすべきかを指示する命令です。)や検索拡張生成(RAG:Retrieval Augmented Generation)(脚注:RAGでは、まず言語モデルにプロンプトが与えられる。その後、モデルは知識ベースから関連情報を検索し、この情報を使って応答を生成する。これにより、モデルの応答の精度と関連性が向上する。)などの他の技術の使用が増加する可能性があります。
基盤モデル開発が、大規模なカスタマイズを必要とせずに、最も強力なモデルが幅広いタスクに対して非常に効果的になるところまで進歩した場合、市場ダイナミクスに影響を与える可能性があります。たとえば、少数のモデルでほとんどのユーザのニーズを満たすことができるため、利用可能な基盤モデルの数が統合される可能性があります。この統合により、基盤モデル開発者が競争して革新するインセンティブが低下するのであれば、懸念されるでしょう。競争の減少により、新しいモデルの需要が減少する可能性があるためです。これは、開発者が基盤モデルを開発したり、既存のモデルを改善したりする動機が少なくなるため、基盤モデルイノベーションの停滞につながる可能性があります。
しかし、他の利害関係者は、基盤モデルは特定のタスクに合わせてファインチューニングされた場合に引き続き最も効果的であると信じています。この状況では、さまざまな組織がそれぞれドメイン固有のデータを利用して開発またはファインチューニングしているという、あまり集中しない固有のモデルが急増する可能性があります。また、異なる下流市場が異なるアプローチに従って、一般的な基盤モデルとタスク固有のファインチューニングモデルが混在する可能性もあります。
3.7.4 競争するには最先端のパフォーマンスが必要でしょうか?
現在、パフォーマンスの点で最先端の基盤モデルは、膨大な量の入力を使用する基盤モデルです。ただし、オープンソースまたはクローズドソースのモデルが、競争上の制約として機能するために最高パフォーマンスのモデルと同等のパフォーマンスレベルを達成する必要がない可能性があります。
この理由の一つは、基盤モデルの潜在的なアプリケーションのすべてが最先端のパフォーマンスを必要とするわけではないためです。たとえば、顧客レビューの分類や製品のテキスト説明の生成などの特定のタスクは、より小さなモデルや特定の目的に合わせてファインチューニングされたモデルを使用して効果的に実行できます。このタイプのモデルの一例は、顧客関係管理(CRM)に焦点を当てたモデルであるSalesforceのEinstein GPTです。CRMのタスクでは、このモデルはタスク固有の性質により、「最先端」のモデルよりも優れたパフォーマンスを発揮する可能性があります。
現在、最もパフォーマンスの高いモデルはクローズドソースです。事前学習されたオープンソースモデルのパフォーマンスは現在、クローズドソースのモデルに比べて遅れています。ただし、いくつかのファインチューニングを行うことで、オープンソースモデルが一部のクローズドソースモデルと競合できる可能性があります。一部のアプリケーションでモデルを利用するために最先端で競合する必要がない場合、小規模またはファインチューニングされた、クローズドソースモデルやオープンソースの代替モデルとの競合が生じる可能性があります。
一部のアプリケーションでさまざまなパフォーマンスレベルのモデルが利用されている場合、そのようなモデルの開発には、最先端のものよりも少ない計算量、より少ない専門知識、および潜在的に異なるデータが必要となる可能性があるため、モデル開発への参入障壁が低くなる可能性があります(たとえば、一部のモデルでは、必要なレベルまで習熟するために必要なデータが少なくなる場合があります。また、特定のタスクのモデルでは、潜在的に簡単にアクセスできるドメイン固有のデータが必要になる場合があります)。これにより、すべてのアプリケーションが最先端のモデルを使用する場合よりも、より競争力のある市場結果が得られる可能性があります。これは、たとえ将来のオープンソースが最先端のパフォーマンスを達成できなかったとしても、オープンソースモデルがクローズドソースモデルに競争上の制約を与える可能性があるということです。
ほとんどのアプリケーションで最先端のモデルが必要または優先されるようになった場合、このパフォーマンスは最前線にある一つまたは少数のモデルでしか達成できない可能性があります。この状況では、少数の大手企業が独占する集中した基盤モデル市場になる可能性があります。ただし、将来のイノベーションにより、最先端のパフォーマンスを実現するために多くの入力を備えた大規模なモデルが必要とされない場合、より幅広い開発者が最先端にアクセスできるようになる可能性があります。
より一般化されたモデルの開発は、このダイナミクスに影響を与える可能性があります。より一般化されたモデルが複数の専門特化な市場で競争できるように開発された場合(これは最先端である必要はない場合があります)、専門特化モデルが競争上の制約として機能するには、最先端のパフォーマンスに近づく必要がある場合があります。
3.7.5 大手テクノロジ企業や先行者が有利になるのでしょうか?
大規模なテクノロジ企業が膨大な量のデータやリソースにアクセスできることで、小規模な組織に比べて圧倒的な優位性が得られ、競争が困難になる可能性があります。ただし、この利点がどの程度であるかは、規模の経済、範囲の経済、フィードバック効果などの多くの要因に依存するため、不確実です。基盤モデルの状況も進化していますが、小規模、クローズド、またはオープンソースモデルの長期的な影響はまだ完全には理解されていません。イノベーション、コミュニティのコラボレーション、新興テクノロジなどの要因により、既存のダイナミクスが破壊される可能性があり、将来の競争環境が予測しにくくなります。
このセクションでは、先行者利益、規模の経済、範囲の経済、およびフィードバック効果の潜在的な影響をより詳細に検討します。これらの影響が非常に強い場合、一部の企業が将来的に競争することが困難な強力な地位を築く可能性があります。
基盤モデルの最初の公開リリースはOpenAIによって行われ、その後、Google、Meta、Microsoft、NVIDIAによってさまざまなモデルが開発されました。基盤モデル市場におけるこれらの先行者は、いくつかの利点を享受できる可能性を持っています。まず、基盤モデルの開発に早期に投資することで、需要によってコストが上昇する前に、入力コスト(たとえば、計算やデータのコスト)を削減できる可能性があります。第2に、これらの企業は基盤モデルの主要なプロバイダとしての地位を確立し、ブランド認知度や顧客ロイヤルティの点で優位性を得ることができます。また、モデルを実験して改良するためのより多くの時間を得ることができ、パフォーマンスと機能の点で優位性を得ることができます。あるいは、モデルを再トレーニングするために大量のユーザデータを活用できる可能性があります。最後に、早期参入により、パートナーと開発者の堅牢なエコシステムを構築する機会が得られ、その結果、幅広いユーザネットワークとより強力な市場での地位が得られます。
主要な基盤モデルを早期にリリースしても、成功やこの利点を活用できることが保証されるわけではありません。知的財産法に違反したり、プライバシー規制を遵守しなかったりするなど、初期参入者が犯した間違いは、他にとって学習の機会となる可能性があります。初期の開発者は、精度や効率が劣る基盤モデルを開発する場合もあります。市場の進化に伴い、すでに投資されているリソースが時代遅れになる、投資の座礁ももう一つのリスクです。(脚注:たとえば、基盤モデルのデプロイメントや商用化の前に時代遅れとなったり陳腐化したりする基盤モデルのトレーニングに、企業が多大な資源を割く場合などである。)さらに、事前学習されたオープンソース基盤モデルにより、新規参入者がすぐに追いつくことができる場合があります。これは、後からの参入者が、時間やリソースを投資することなく、先行者の取り組みから恩恵を受けることができることを意味します。これにより、先行者が競争上の優位性を維持することが困難になる可能性があります。
モデルのパフォーマンスや機能に関して競合他社が追いつく能力などの他の要素も、先行者が競争上の優位性を確立し維持できるかどうかを決定する上で重要な役割を果たします。
規模の経済、範囲の経済、およびフィードバック効果(学習効果とネットワーク効果)も、一部の大企業にとって潜在的な利点となります。基盤モデルを開発する大手テクノロジ企業は、学習済みのモデルを効率的に使用して他の複数のモデルを学習させることで、大幅に削減されたコストで初期の高額な学習コストを相殺できるため、規模の経済(脚注:企業が生産規模を拡大することによって達成できるコスト優位性を指します。生産レベルが上がるにつれて、各ユニットの平均生産コストは低下します。)によって有利になる可能性があります。
大規模テクノロジ企業が複数のモデルにわたってハードウェア、アルゴリズム、学習技術を活用できるため、範囲の経済(脚注:企業がさまざまな製品やサービスを別々に生産するよりも、一緒に生産した方が得られるコスト優位性のこと。)によって利点も得られる可能性があります。これらの共有リソースを活用することで、大規模テクノロジ企業はリソースを最大限に活用し、より効率的かつコスト効率の高い方法で全体的なパフォーマンスを向上させることができる可能性があります。
チャットインターフェイスのサムアップボタンやサムダウンボタンなどの機能を通じて伝えられるフィードバックなど、ユーザが生成したデータからの学習効果も、大手テクノロジ企業に利点をもたらす可能性があります。このデータは収集元の基盤モデルを直接改善しない可能性がありますが、事前学習や将来の反復のファインチューニング中に使用でき、そのようなデータにアクセスできるプロバイダに優位性を与えることができます。このデータに価値があることが証明されれば、大量のユーザフィードバックデータを持っている企業は、それを使用してモデルを大幅に改善できる可能性があります。
現在導入されている基盤モデルがネットワーク効果から恩恵を受けるかどうかは明らかではありません(ただし、以下で説明するように、プラグインなどの一部の下流アプリケーションのコンテキストではネットワーク効果が存在する可能性があります)。たとえば、ある利害関係者は、現在、基盤モデルが事前学習またはファインチューニングを完了すると、そのパフォーマンスレベルは基本的に固定され、ユーザ数がユーザエクスペリエンスに即座に直接影響を与えることはないと主張しました。それにもかかわらず、大規模なユーザベースを持つ企業は、将来のモデルを開発する際にデータフィードバックループから恩恵を受ける可能性があります。これによって先行者がどの程度有利になるかは、このフィードバックデータの価値によって決まります。
ある市場参加者はまた、規模の経済、範囲の経済、およびフィードバック効果の重要性に疑問を呈し、オープンソースモデルの一部のプロバイダは、これらの利点を享受せずに運用する可能性があるが、クローズドソースモデルのプロバイダと効果的に競合できると主張しています。(脚注:さらに、Googleのエンジニアからリークされたメモによると、オープンソースモデルはクローズドソースモデルに対して競争上の制約をもたらすといいます。メモの著者の見解では、オープンソースモデルは、より費用対効果が高く、カスタマイズ可能で、使用制限が少ないなど、さまざまな利点があるからです。)
我々は、正のフィードバック効果を引き起こす可能性のある他のメカニズムについてのいくつかの推測的な見解も聞いています。基盤モデルはコーディングアシスタントとして使用できるため、さらに基盤モデルを構築するチームにとっても役立つと聞いています。「セルフプレイ」アプローチ(脚注:セルフプレイは強化学習エージェントのパフォーマンスを向上させる技術で、DeepMindのAlphaZeroがチェスや囲碁のようなゲームのプレイに使用しました。)や、後続のトレーニング反復用のデータを生成(上記の「合成データ」のセクションを参照)するために学習済みモデルを使うなど、基盤モデルが再帰的な自己改善(自分自身の改善能力を向上させるために基盤モデルを使用できるという考え方)からどの程度、どの領域やユースケースでメリットを得ることができるかは不明です。
3.7.6 オープンソースモデルは今後も市場の重要な部分を占めるのでしょうか?
オープンソース基盤モデルでは、高性能でファインチューニングされたモデルの効率的な開発に焦点を当て、重要かつ急速な革新が起こっています。多くの開発者は、一般に公開されている事前学習済みモデルを利用しているため、基盤モデルにかかる多額の初期費用が不要になります。これにより、商用基盤モデルに依存しないオプションが市場に提供されます。ただし、ファインチューニングされたオープンソースモデルが長期的にクローズドモデルとの競争力を維持できるかどうかは不明です。
オープンソース開発者が事前学習された基盤モデルを開発するための資金を確保できるかどうかについては、いくぶん不確実性があります。これは、オープンソース・ムーブメントを支援したいという投資家の意欲と、オープンソース開発者がビジネスモデルの一部をマネタイズする能力(たとえば、オープンソースモデルとともに、モデルとの相互作用やモデルのファインチューニングがより簡単になるソフトウェアを販売するなど)に依存します。このチャネルを通じて何らかの利益を生み出すことができれば、オープンソースはより魅力的な投資先となる可能性があります。
もう一つの潜在的な懸念は、高品質で競争力のあるオープンソースの事前学習済みモデルが今後もリリースされるかどうかです。たとえば、オープンソースの事前学習済みモデルの著名な貢献者から、いくつかの小規模なオープンソース言語モデルをリリースした後、基盤モデルの開発を中止する意向を示したという話を聞きました。
一部のより「オープン」な基盤モデル(つまり、モデルの重みが公開されている狭い意味)には、その使用と配布を制限するライセンス条項が適用される場合があります。たとえば、MetaのオリジナルのLLaMAモデルは、オープンソース開発で多くの進歩がもたらされたものですが、非商用である研究目的でのみ使用できます。OpenAIの利用規約では、そのモデルを使用して競合モデルを開発することも禁止されている場合があります。これらのライセンス条項は、将来「オープン」モデルおよびオープンソースモデルへのアクセスを誰が管理するのか、またモデルの開発と使用方法にどのような制限が課されるのかについて重要な疑問を引き起こします。
したがって、クローズドソースの事前学習済みモデルが最先端の機能に関して進歩するにつれて、オープンソースの代替モデルからファインチューニングされたモデルが競争力を維持できるかどうかは不確実になります。ただし、この分野では多くの開発が行われています。MetaはLLaMA 2をリリースしました。これは、いくつかの制限はありますが、商用利用のライセンスを取得できます。(脚注:LLaMA 2は、月間アクティブユーザ数が7億人を超えるライセンシーの除外や、他のLLMを改善するための出力結果の使用の制限など、一定の制限付きでリリースされています。)OpenAIはまた、近い将来、商用目的で使用できるオープンソース基盤モデルをリリースする計画も発表しました。これらのモデルは幅広い開発者や企業が利用できる可能性があるため、これらの開発は基盤モデルの開発と使用に重大な影響を与える可能性があります。
最後に、基盤モデルのサプライヤが最初はオープンソースモデルを使用してパートナーと開発者のエコシステムを開発するが、後にオープンソースアプローチからの移行を選択する可能性があるという、追加の潜在的な懸念も聞きました。(脚注:米国連邦取引委員会のブログには、次のように書かれている。『これまでの経験から、企業が長期的な競争を損なうような方法で、「先にオープン、後でクローズド」という戦術を用いることも分かっています。最初にオープンソースを使用してビジネスを呼び込み、安定したデータの流れを確立し、規模の優位性を獲得した企業は、後にエコシステムを閉鎖して顧客を囲い込み、競争を締め出す可能性があります。』)
もう一つの課題は、イノベーションと倫理基準の維持の間で適切なバランスを取ることです。オープンソース開発は実験と創造性を奨励し、それが成功の原動力となっています。ただし、これは、たとえ安全策が講じられていたとしても、悪用や非倫理的な行為が行われる可能性があることも意味します。これにより、単一の組織が管理するクローズドモデルとは異なり、オープンソースプロジェクトは幅広い個人や組織からの自発的な貢献に依存するため、標準の施行が複雑になる可能性があります。
3.8 結論
基盤モデル開発者は、効果的に競争するために、データ、計算能力、技術的専門知識、資金といった主要なインプットにアクセスする必要があります。これらのインプットは、基盤モデルの開発、デプロイ、使用にとって重要です。これらの主要なインプットへのアクセスが制限されると、基盤モデル開発者は、より多くのリソースを備えた、より大規模で確立された企業と競争できなくなる可能性があります。これは基盤モデル分野における競争と技術革新の減少につながり、最終的には消費者に損害を与える可能性があります。
我々はまた、基盤モデルの将来の発展に関して多くの重要な不確実性を特定しました。これらの不確実性が基盤モデル分野の競争に与える影響はまだ不明ですが、次のような形で現れると悪影響を及ぼす可能性があります:
- ・基盤モデルの学習に独自データが重要になった場合、このデータへのアクセスが不足すると、小規模な組織や研究グループの参入や拡大に障壁が生じる可能性があります。これにより、これらの組織は、より規模が大きく確立されたプレーヤーと効果的に競争することができなくなる可能性があります。
- ・ますます複雑化するアプリケーションのニーズに対応するためにモデルを大きくする必要がある場合、計算資源とインフラストラクチャが限られている小規模な組織にとってさらに不利になる可能性があります。
- ・同様に、競争力を高めるために最先端のパフォーマンスが必要な場合、そのような進歩を達成するためのリソースや専門知識を持たない小規模な組織に多大な負担がかかる可能性があります。
- ・基盤モデルが幅広い業務で高い効果を発揮するようになれば、基盤モデルの数は統合される可能性があります。少数の非常に効果的なモデルがあれば、ほとんどのユーザのニーズを満たすことができるからです。この統合により、新しい異なるモデルに対する需要が減少するため、基盤モデル開発者が競争して革新するインセンティブが低下する可能性があります。
- ・大規模なテクノロジ企業は、膨大な量のデータとリソースにアクセスできるため、規模の経済、範囲の経済、フィードバック効果を活用して、小規模な組織に対して乗り越えられない優位性を獲得できる可能性があり、競争が困難になります。
- ・オープンソースモデルの継続的な開発とデプロイメントには潜在的な課題が存在します。これらには、ライセンス制限の可能性、資金調達の不確実性、長期的にはクローズドモデルがオープンソースモデルを上回る可能性が含まれます。
基盤モデル分野がこのように発展すると、一部の企業が効果的に競争することが難しくなる可能性があります。これはイノベーションを抑制し、アプローチの多様性を制限し、これまで基盤モデルの進歩に貢献してきた市場のダイナミックな性質を妨げる可能性があります。
経済全体における基盤モデルの重要性を考えると、基盤モデルの開発に必要な主要なインプットへのアクセス、特にデータや計算能力が不当に制限されるのではないかと懸念します。以下の場合、市場はプラスの結果に向かう可能性が高くなります:
- ・さまざまな基盤モデル開発者が、データ、計算能力、専門知識、資金など、基盤モデルを構築するために必要な主要なインプットに、不当な制限なく公正な商業条件でアクセスできる場合
- ・初期に成功を収めた基盤モデル開発者が、新規参入者による継続的な競争上の制約に直面するため、市場の先駆者となり、規模の経済を享受したり、フィードバックループの恩恵を受けたりすることによって、不釣り合いな確固たる優位性を得ることができない場合
- ・オープンソースおよびクローズドソースのモデル、新機能の最前線を推進する基盤モデルなど、企業が選択できるさまざまなモデルが存在する場合
- ・他の市場でのリーダ的地位を利用して、その市場で競合する他の企業や競合する基盤モデル開発者へのアクセスを不当に制限することができない場合